Summary
- AI responses are based on the internet (via training or search), and AI is now used to generate a significant amount of content online, creating the potential for an infinite feedback loop.
- Prior work has shown that when LLMs are recursively trained on their own output, they experience model collapse: responses become less diverse, and eventually no longer resemble the original training data.
- In this report, we show that a similar collapse occurs if LLM-based AIs retrieve references they authored using a search tool.
- We conduct extensive experiments with three simulations of AI retrieving references it generated, using three LLMs, and 1,019 information-seeking prompts, totaling 1,528 simulations and over one million LLM API calls.
- We see that a single self-authored reference can start to trigger collapse because AI disproportionately cites its own content. This self-bias persists even after controlling for reference quality.
- We find that 79.6% (1,216/1,528) of simulations end in collapse.
Introduction
AI systems like ChatGPT are powered by large language models (LLMs). LLMs are trained on large text datasets, primarily from the internet. AI systems also often have access to a search tool to retrieve additional information from the internet. Using search results to generate responses is called retrieval-augmented generation (RAG). LLM responses are randomly sampled from a probability distribution based on the internet. Therefore, responses from AI should approximately mirror the diversity of thought online.
AI is now also used to generate large amounts of text online. In our recent AI-generated content paper, we show that there are now as many AI-generated articles as human-written articles being published. In this report, we find that a substantial share of references AI cites are AI-generated. This creates the potential for an infinite feedback loop.
Prior work has shown that training LLMs on their own generations can lead to model collapse, in which token probabilities become increasingly concentrated, resulting in substantially less diversity in responses and eventually text that no longer resembles the original training data.
We investigate what happens when search-enabled LLMs retrieve pages they authored. We call a reference self-authored when it was generated by the same model using its own answer to a prompt. Across 1,528 simulations, we find that retrieving self-authored references in RAG leads to collapse (essentially the same response every time) in 79.6% (1,216/1,528 simulations). In one experiment (see Larger-Scale Experiments), 22% of pairs of AI responses are essentially paraphrases initially. By the end of the simulation, 89% are.
Surprisingly, this collapse begins almost immediately, even when only a single reference is self-authored by the model. The results suggest that self-authored references have a disproportionate influence on responses. We find that they are cited more often than original references, including those that are themselves AI-generated, even after we control for reference quality. This suggests self-bias: AI prefers its own answer in its own writing style.
Our simulations demonstrate a risk: AI responses no longer reflect the diversity of human thought, and as more AI-generated content is published, the internet converges on a single perspective.
Example
Consider the information-seeking prompt “Who are the best Twitch streamers currently?” This may trigger a search that identifies the following pages as relevant:
- https://streamscharts.com/news/top-twitch-streamers-2025
- https://en.wikipedia.org/wiki/List_of_most-followed_Twitch_channels
- https://www.shanethegamer.com/esports-news/most-watched-twitch-streamers-2025/
- https://www.techradar.com/ai-platforms-assistants/twitchs-most-subscribed-streamer-is-not-human
- https://www.dexerto.com/entertainment/top-20-most-followed-twitch-streamers-750744/
- https://streamscharts.com/news/most-subscribed-twitch-streamers-2025
If we ask GPT-5.2 10 times, using the above as references (the sources it uses to answer), we get 10 different answers. Here are two examples that differ in structure and streamers mentioned.

The visibility of an entity in a set of responses is the percentage of responses that mention the entity. Across ten responses, we observe the following visibilities for each streamer.
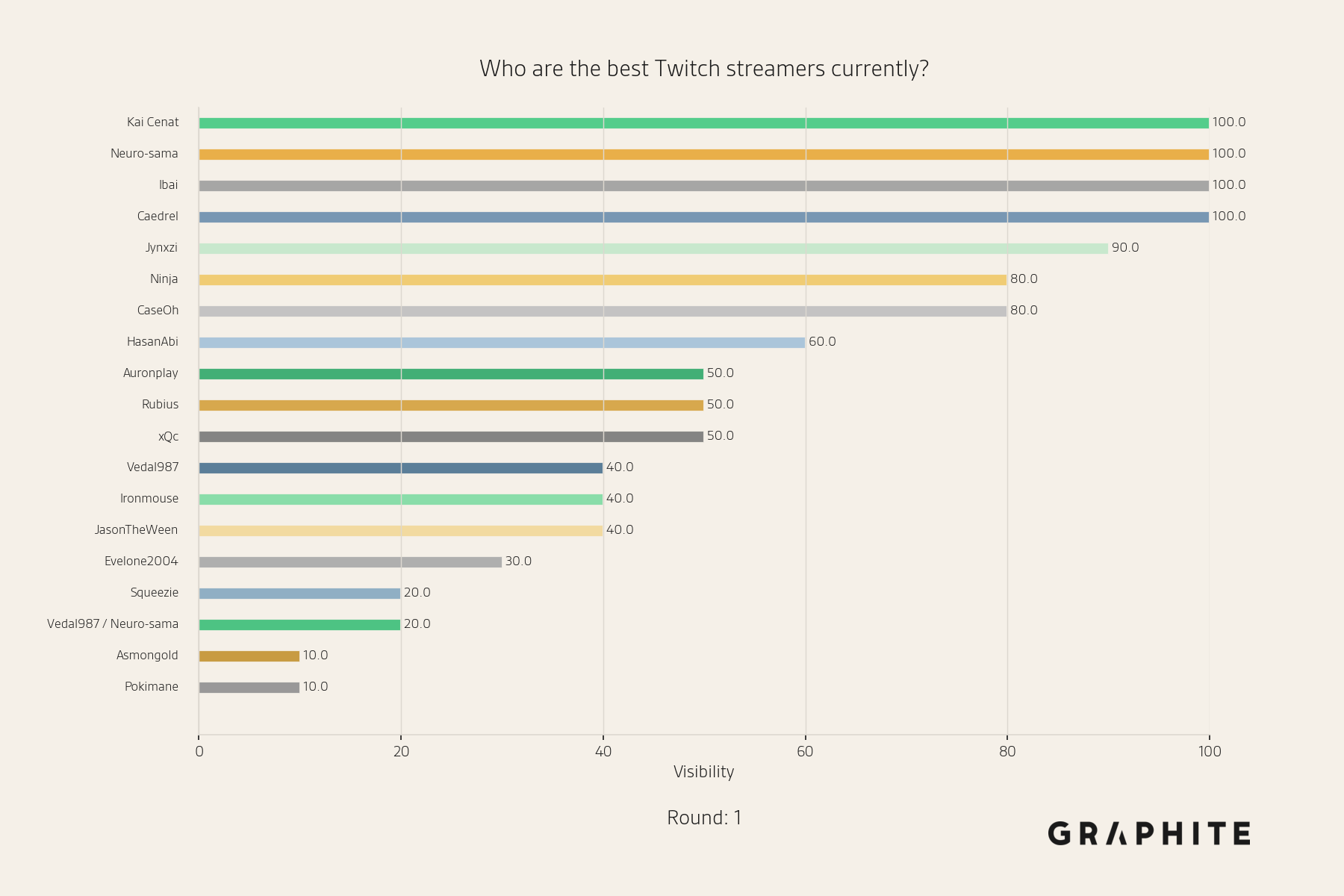
Note the diversity in responses. Some streamers, like “Kai Cenat”, are mentioned in every response, while others, like “Squeezie”, are mentioned occasionally (2 of 10 responses).
What if we use AI to generate a new article based on one of the model’s responses, replace one of the original references with it, and then regenerate the answers? What if we repeat this process over and over? We answer this question by running our Replace One simulation. The simulation takes place over a number of rounds, and in each round, we replace one original reference with a self-authored reference. We provide a complete description in the Simulations section below.
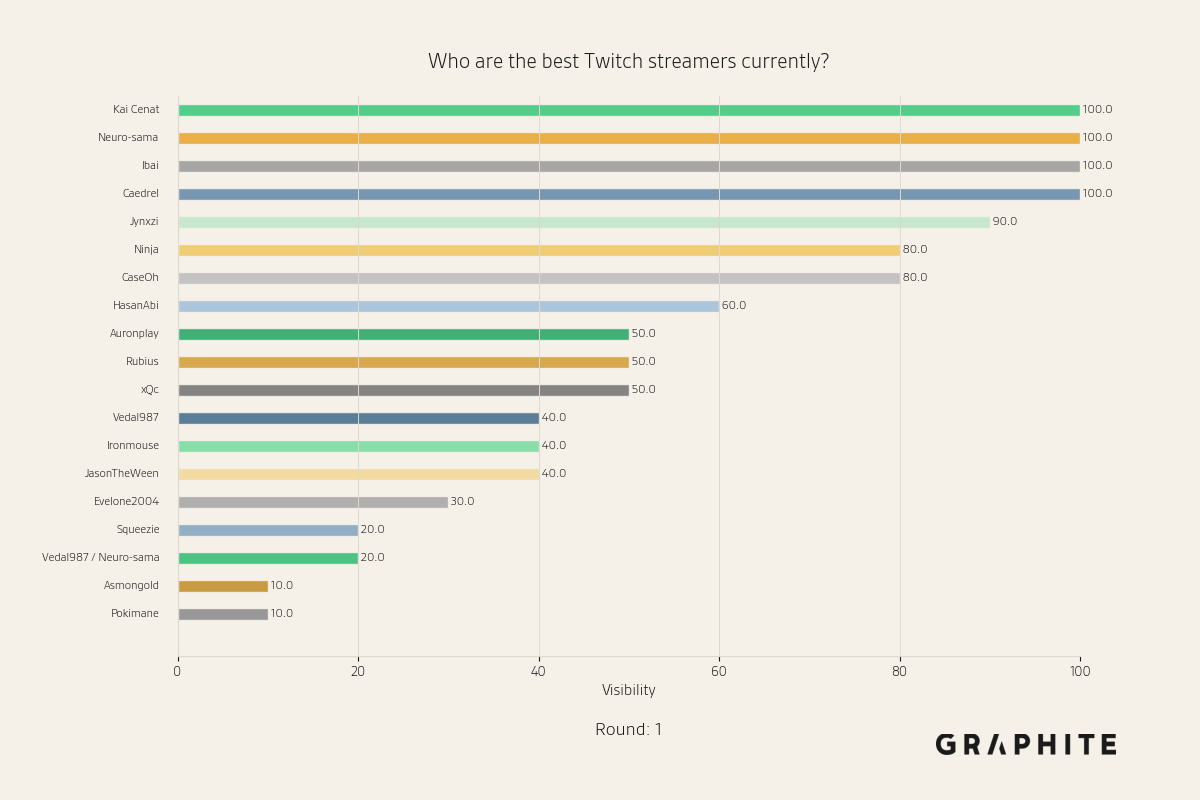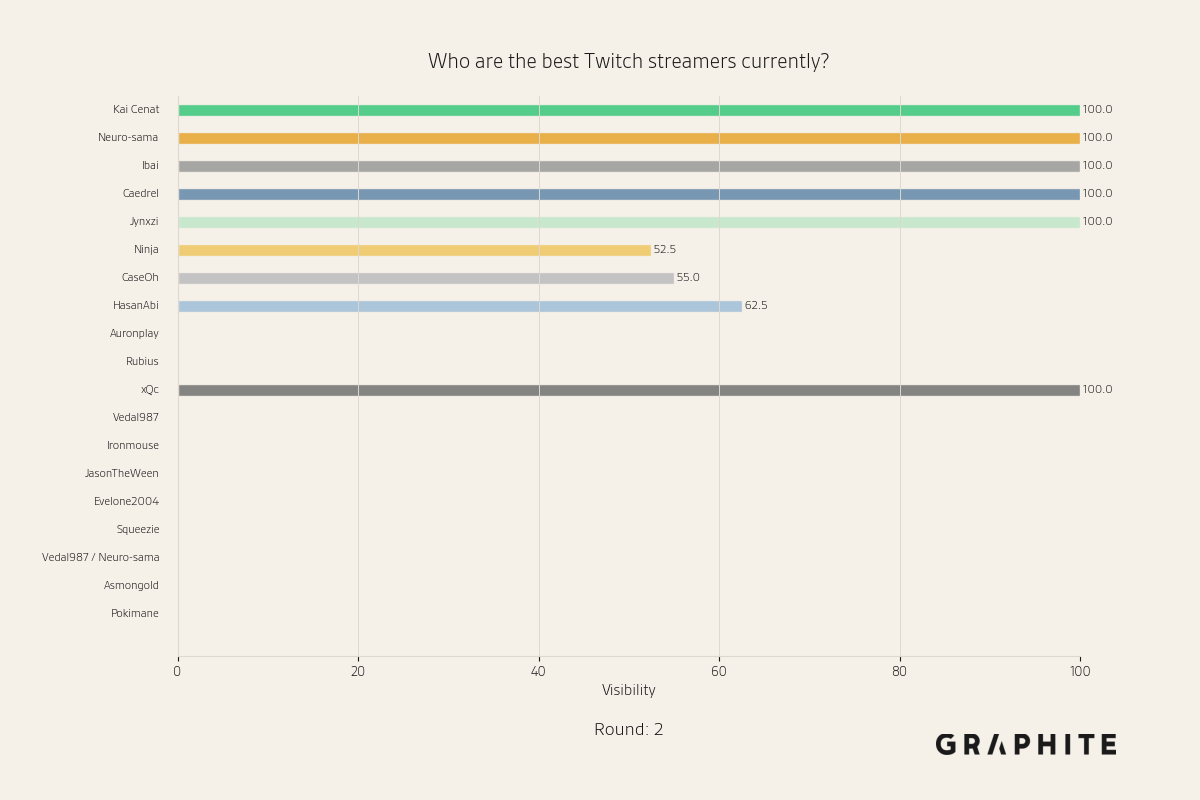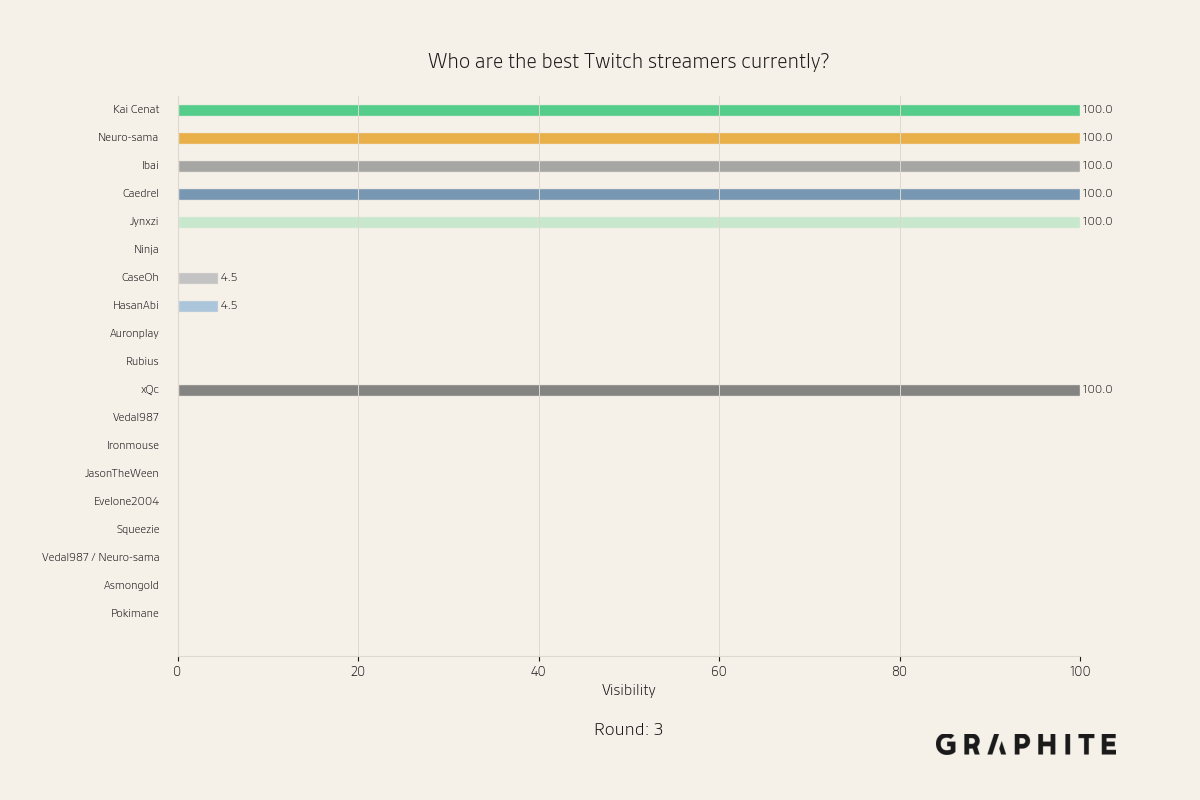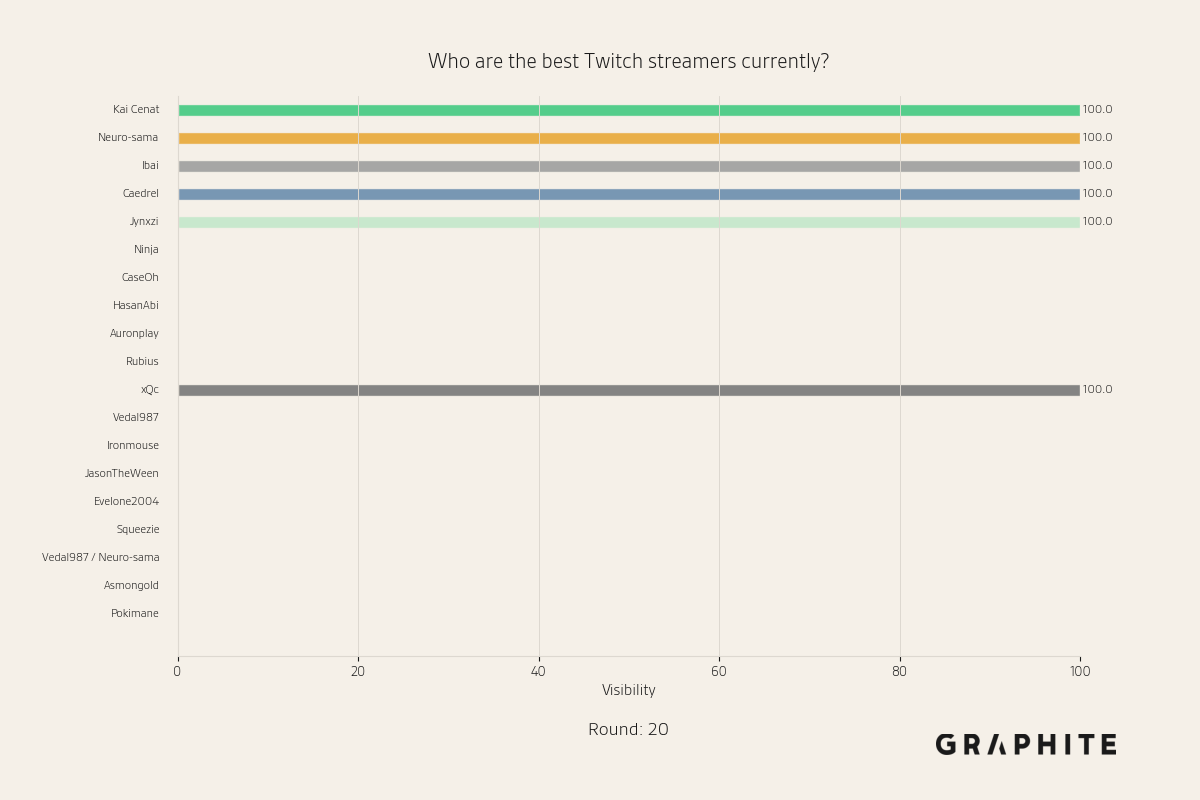
After five rounds of recursively replacing references, we end up with the following streamer visibility plot:
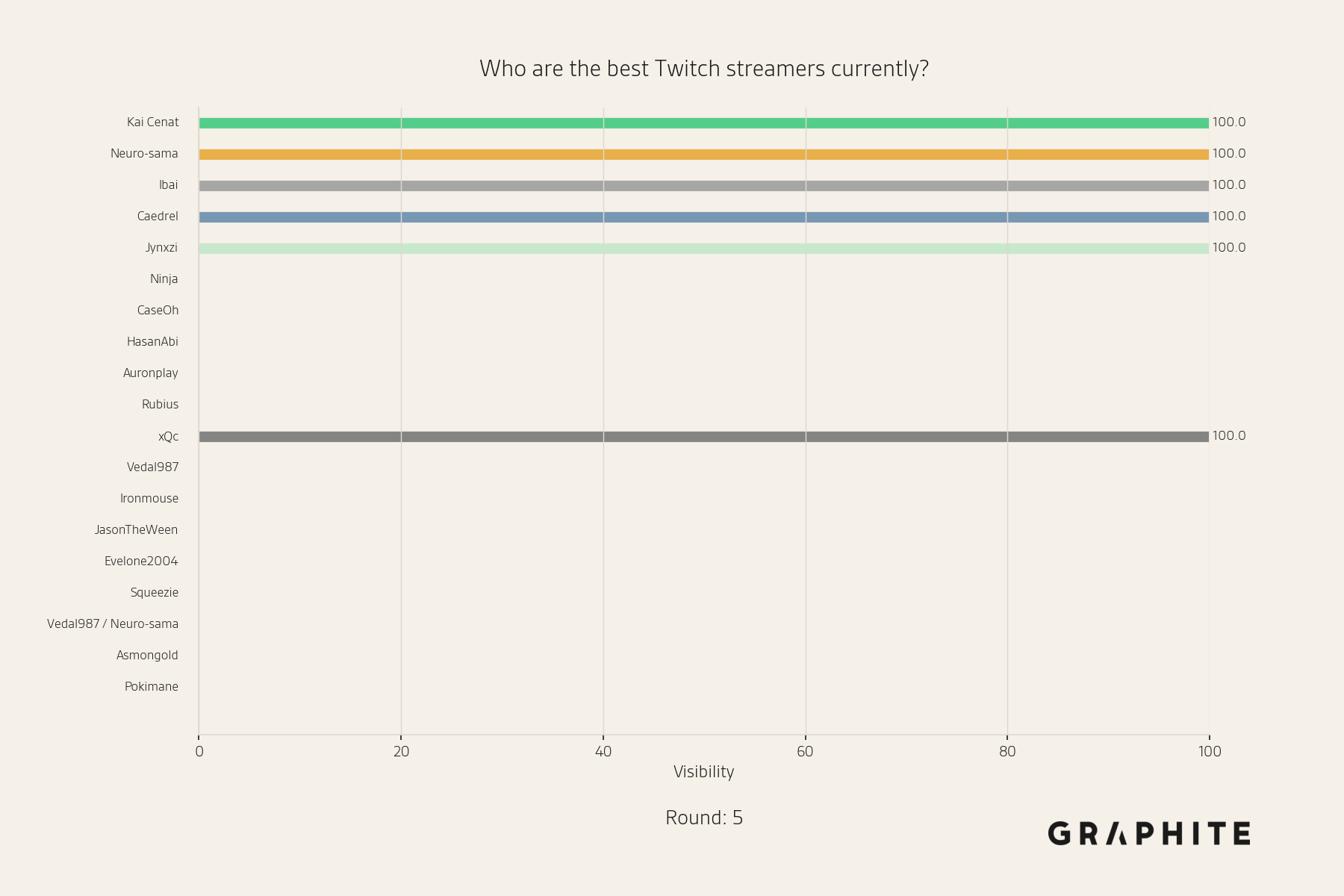
Note that every streamer has visibility 0% or 100%. This means that every answer mentions exactly the same streamers. The previously wide distribution over streamers considered the best has collapsed. While the streamers mentioned in every response in the original distribution have survived, some that were initially mentioned frequently, like “Ninja”, have dropped out of the responses entirely, and “xQc”, originally mentioned 50% of the time, now always appears. So in addition to less diversity, the answers to this prompt have changed. These visibilities remain the same for the rest of the simulation.
Below is an animation of how visibilities change over the course of the simulation.
Background and Related Work
LLMs and RAG
LLMs are pre-trained on massive text datasets from the internet. An LLM can respond to a prompt (without web search) based on its “fuzzy recollection of the internet” (credit: Andrej Karpathy), but cannot attribute its answer to a particular document in its training set.
To generate a response, LLMs predict a probability distribution over possible next tokens (sub-word character sequences), and then randomly select a next token according to that distribution. As a result, LLM responses are non-deterministic, and they often generate different responses to the same prompt. We describe this in detail in Demystifying Randomness in AI.
To reduce hallucinations and incorporate more real-time information, AI systems like ChatGPT now have access to web search. In this report, we use retrieval-augmented generation (RAG) as a general term that encompasses any use of web search, including agentic search, in which the model can selectively choose when to search and which results to read.
When the model uses the web search tool, it adds the retrieved information to its context window to better address the prompt. Research suggests that LLMs are heavily influenced by this context. RAG also allows the LLM to provide citations to the documents it has read to inform the answer.
For information-seeking prompts (i.e., questions), when using RAG, the LLM's answer distribution should resemble the distribution of answers on the internet. At a high level, the model should faithfully represent the diversity of opinion and thought on the internet. (Though note that post-training alignment with human preferences to remove certain types of unwanted bias may shift this distribution.)
Model Collapse
What happens now that AI is used to generate text published on the internet? What if an AI trains on or retrieves its own generations?
Prior work has shown that training LLMs on their own generations can lead to model collapse, in which token probabilities become increasingly concentrated, resulting in substantially less diversity in responses and eventually text that does not resemble the original training data.
Why does this happen? Recursively resampling and re-estimating the probability distribution causes it to drift over time. Specifically,
- When you take a finite sample from a probability distribution, it will not faithfully represent that distribution.
- The model may not faithfully represent the training data distribution, either because it lacks the capacity to fit the data or because learning algorithms fail to find optimal weights.
As a simple illustration, suppose we roll an unweighted die. The probability of rolling each number from 1 to 6 is equal (⅙), and over many rolls, we expect to get about the same number of 2s and 5s, for example. However, suppose we roll the die ten times and never roll a 2. If we were to take those ten rolls and use them to reweight the die, we would end up with a very different distribution, as the probability of rolling a 2 would become 0. In this way, recursively re-estimating a probability distribution from a sample causes drift.
AI Search Collapse
What if, rather than being retrained on its generations, a model retrieves its own generations using a search tool?
Suppose we ask AI, “Who is the best NBA player of all time?” repeatedly, and get different answers. The response will likely always include Michael Jordan and LeBron James, but may occasionally include Hakeem Olajuwon or Larry Bird. If a few people generated articles using the model’s response, and those articles happened to include Hakeem Olajuwon more frequently than Larry Bird, and the AI system retrieved those articles, Larry Bird could drop out of the answer entirely, while Hakeem Olajuwon could start to appear more frequently alongside Jordan and James. These self-authored responses could further influence future articles, and over time, the answers could change and converge onto a particular answer.
Because LLMs are highly influenced by retrieved documents in RAG, we may expect the LLM’s answer distribution to mirror that of the retrieved documents, leading to a similar collapse in the RAG setting as in the retraining setting. The collapse could actually be more dramatic in RAG because responses are based on a relatively small number of documents compared to the size of the model's training set (the internet).
Surprisingly, in our experiments, we find that even small changes to the reference distribution, replacing only one of the original references with a self-authored reference, can cause the responses to collapse. This suggests that RAG is not faithfully reproducing the original input distribution. Instead, there is a bias toward self-authored references. We explore this in the “Why Do Self-Authored References Have Disproportionate Influence” section.
Concurrent work simulates a network of LLMs communicating via a shared RAG database and shows that different models converge toward each other over time, and provides a theoretical analysis (using Gaussian Mixture Models). Our work focuses on the collapse of response diversity within a single model's answers across a wide range of prompts, simulations, and frontier models.
Simulations
We now describe our simulations of AI retrieving content that it previously generated.
We focus on RAG and do not retrain the base model. We limit the scope to information-seeking prompts, in particular, question prompts.
In each round, we use an LLM to generate several responses to a question based on references. We use the following system instructions:
You will be given a question, labeled "question", and context from the internet, labeled "context". Use the context to answer the question thoroughly. Cite each context that informs your answer. Each context has a number. To cite "context 3", use [3]. |
and the following prompt:
context: CONTEXT question: QUESTION |
where CONTEXT has the form:
context 0 TITLE … |
Initially, CONTEXT contains text from the original references (obtained from commercial AI products).
We then take some of these responses (10 for Replace All, 1 for Replace One and Search), remove citations (e.g., [3]), and convert them into the form of online articles using the following system instructions:
You will be given an answer, labeled "answer", to a question, labeled "question", and your job is to expand the answer into an online article. Do not change the answer; just expand it into an online article. Return only the article in plain text (not markdown). |
and prompt
question: QUESTION answer: RESPONSE |
We do this because AI responses to a question may look quite different from the original references (typically articles), and we want to simulate someone publishing an article online based on the AI answer.
We then replace the original references in the context with self-authored ones, or add them to a pool of available references, simulating the publication of self-authored articles and their subsequent retrieval by the model during RAG. There are three variants of our simulation that differ in the way they use these self-authored references.
Replace All Simulation
In the Replace All simulation, we replace each reference with a self-authored reference based on a response from the previous round. We visualize this simulation with the figure below. Note, for clarity, in the figures below we show three references and responses, but our actual simulations use ten responses and at least five references.
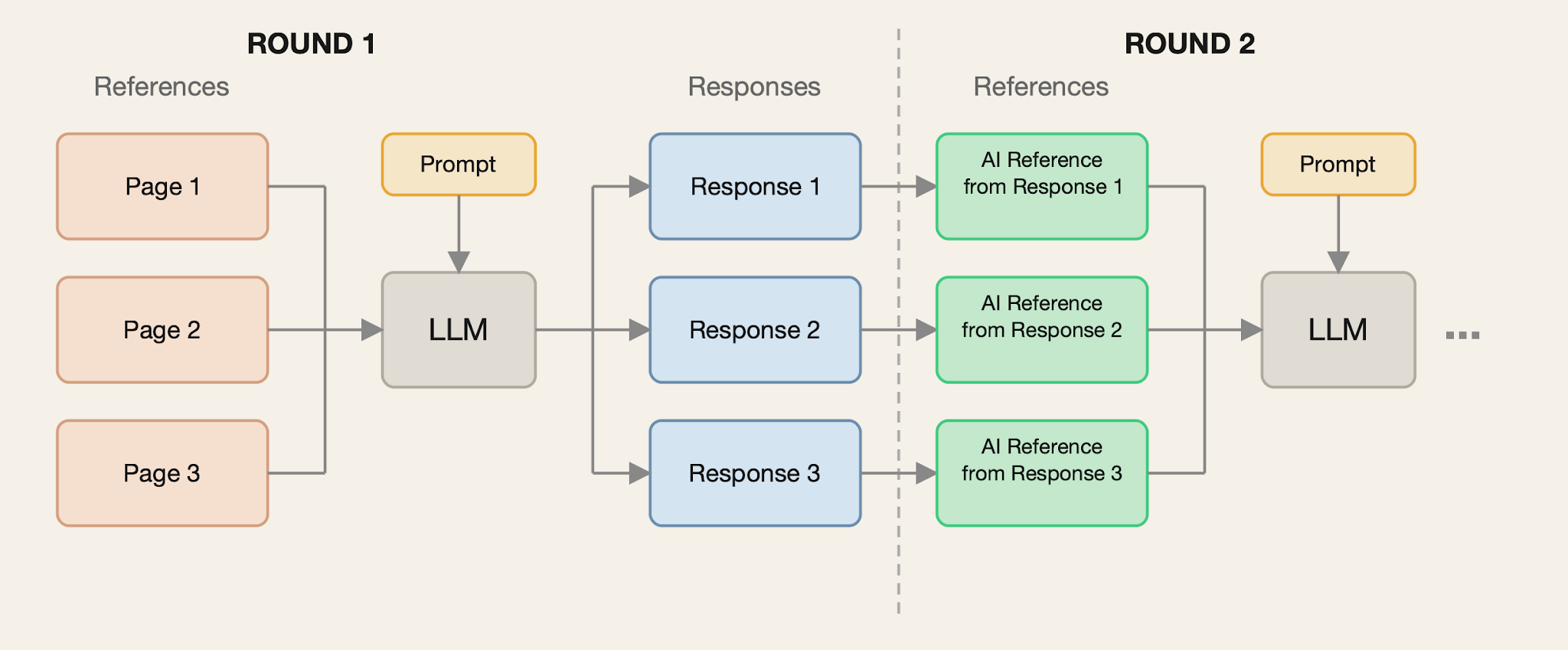
This setup is most similar to the experiments in the model collapse paper.
However, this simulation makes several assumptions. First, it assumes that the self-authored references are retrieved and included in the context. Second, it assumes all self-authored references are generated from the same set of responses and that the retriever only retrieves that set. In practice, we expect the replacement of the original references to happen more slowly and for the search tool to retrieve self-authored references from different rounds.
Replace One Simulation
In the Replace One simulation, we replace one of the original references with a randomly selected self-authored reference in each round. We depict this simulation in the figure below.
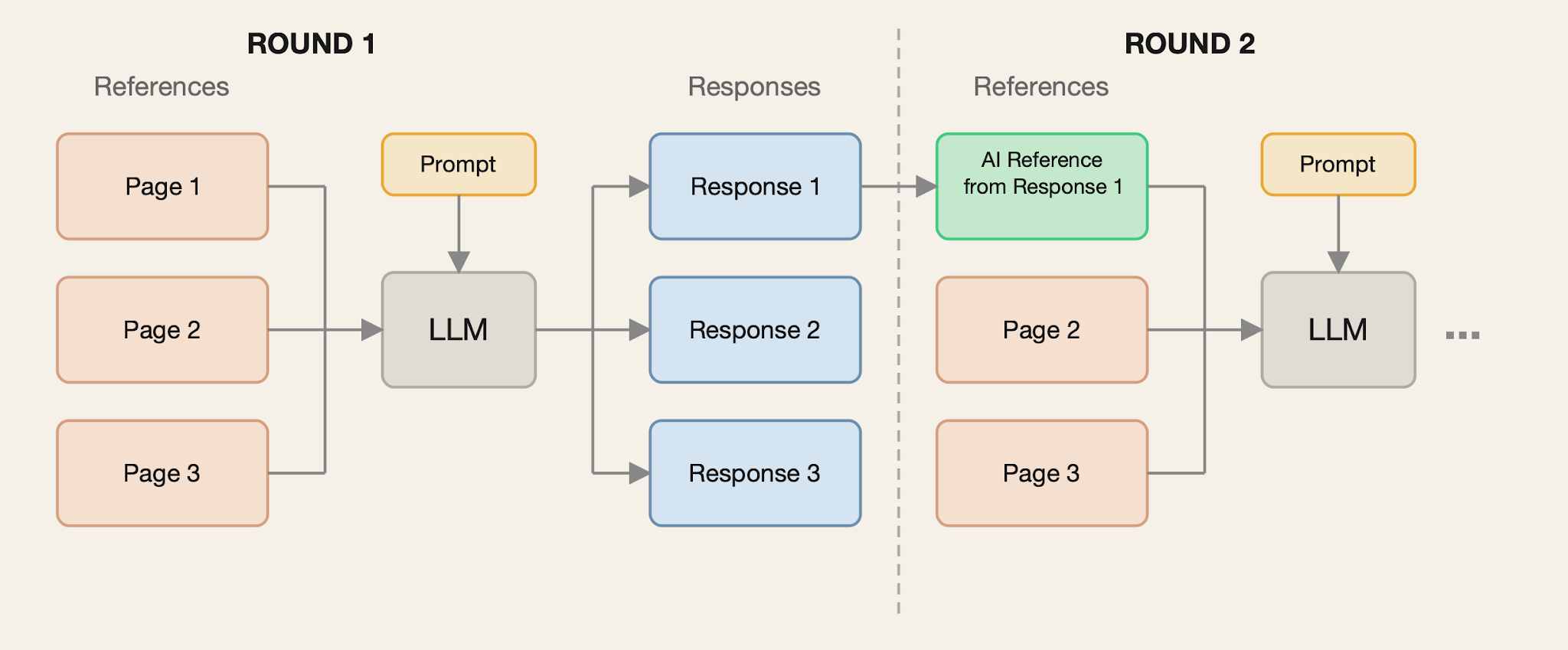
This simulation still replaces the original references, just more slowly, and it still assumes that the self-authored references would be retrieved in search.
Search Simulation
In the Search simulation, we maintain a pool of references that includes the original references and add self-authored references to it one at a time. To determine which references to add to the context in each round, we search the reference pool and retrieve the top-k most relevant chunks. We illustrate this simulation in the following figure:
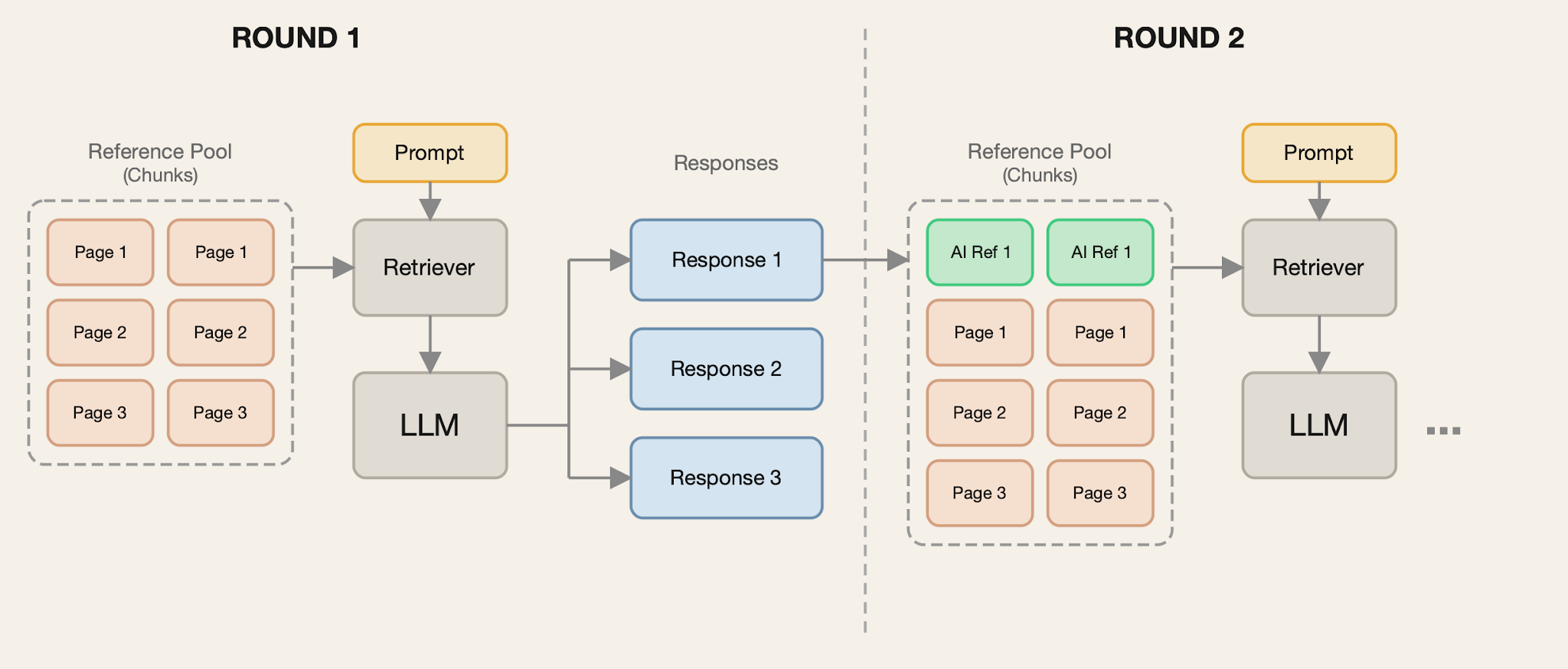
In practice, other content would continue to be published alongside AI-generated content. We do not attempt to simulate this in this paper, as it would introduce many additional free parameters. However, the ease and low cost of creating AI-generated content make it highly likely that AI-generated content will comprise an increasing share of online content.
Simulation Implementation Details
We use LLM APIs to run the simulation, so that we control the context provided to the model. In particular, we use the OpenAI, Gemini, and Anthropic APIs.
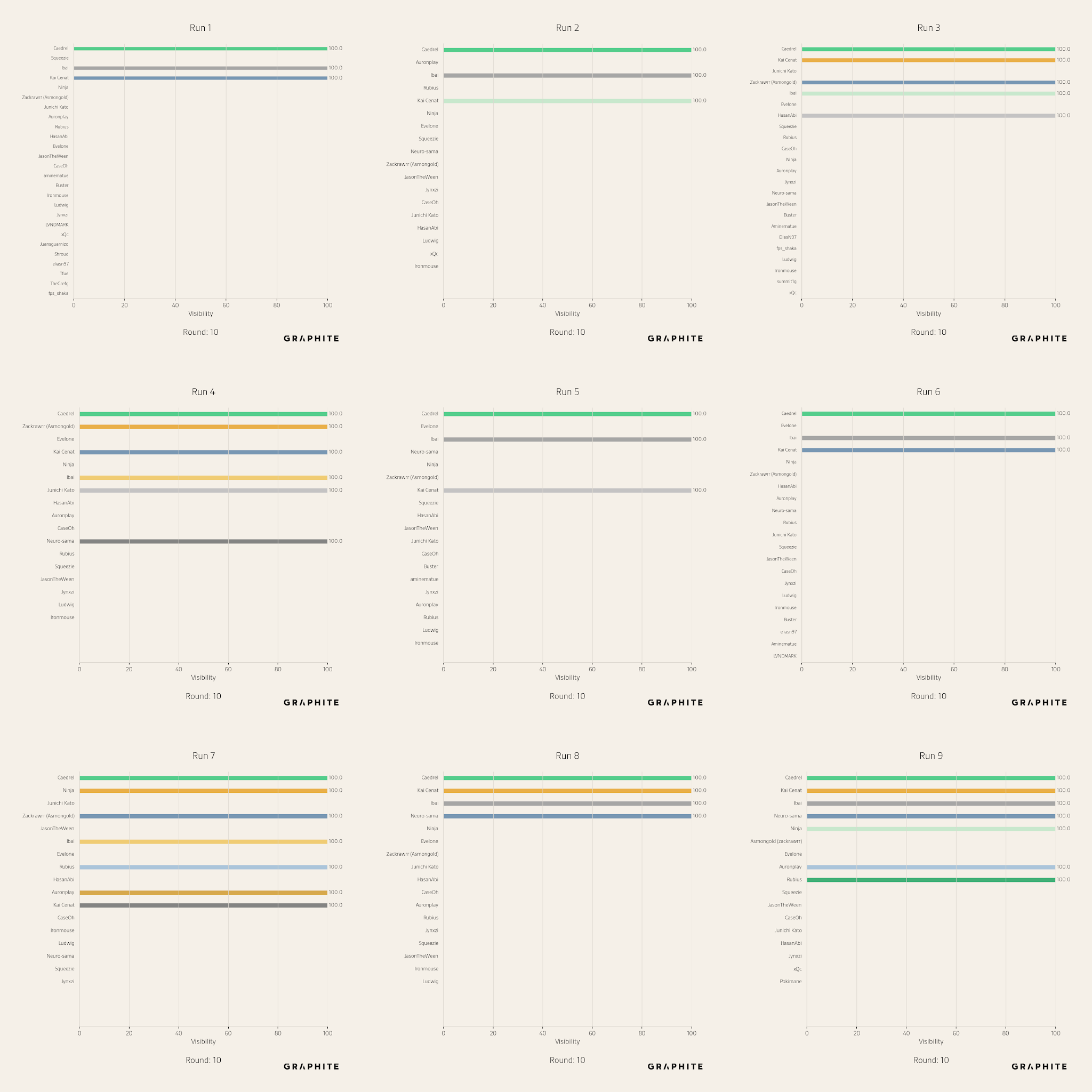
Due to randomness, there are many possible outcomes from running the simulation on each question. For example, here are the entity visibilities in the final round for nine different simulations of “Who are the best Twitch streamers currently?” Different entities survive each time.
Due to costs (see the “Costs” section below), we cannot run many questions many times each. Rather than running a small number of questions many times, we opt to run many different questions once.
For each question, we initialize references using actual references for these prompts from consumer-facing AI tools. For OpenAI models, we collect references cited by ChatGPT using logged-in accounts. For Gemini and Claude models, we collect references cited in Google AI Overviews. We call these original references.
We scrape the content of the original references and identify the page's main content (removing boilerplate, etc.) using trafilatura. We spot-checked 50 pages; they were all scraped properly, and the accuracy of the main content extraction was high. For the Replace All and Replace One simulations, we also identify the portions of the main content (for both original and self-authored references) relevant to the question using an LLM to reduce costs. For the Search simulation, we use chunks from the full main content.
We initialize the context with the content from the original references. We do not provide the original URLs in the prompt to avoid bias; instead, we rename them as “context n”. We also randomly shuffle the excerpts in each round to reduce position bias.
In each round of the simulation, we generate ten responses to the question.
To control costs, we stop the Replace All simulation after 10 rounds, the Replace One simulation after 20 rounds, and the Search simulation after 30 rounds. Although Replace One and Search run for more rounds, Replace All replaces all original references after round one, whereas Replace One replaces all original references by round 10. The original references may never be fully replaced in the context in the Search simulation, depending on whether they continue to be retrieved.
We filter questions with fewer than 5 references. For the Replace All and Replace One simulations, we truncate the number of references at 10, keeping the longest references, whereas for the Search simulation, all references are added to the pool.
For the Search simulation, we use OpenAI vector stores to implement RAG. We use the default chunking strategy, although as part of our research, we experimented with other chunking strategies and generally found that larger chunks lead to faster collapse. In each round, we add new documents to the pool, and then retrieve the top 10 chunks and use them as the context.
As part of debugging, we verified that collapse does not occur when no self-authored references are added. We observe only the variation expected from sampling LLM responses.
We leave the temperature at the default value (1.0) for all experiments.
We use GPT-5.2 for evaluation tasks such as computing the same answer percentage, extracting entities, and scoring reference quality. We use GPT-5.2 Chat for many experiments because it was the version of GPT-5.2 that ChatGPT used when we ran them.
To distinguish AI-generated and human-written original references, we use GPTZero, an AI-content detector, following a methodology similar to our AI content paper. We classify a reference as AI-generated when GPTZero labels it as AI or Mixed.
Costs
Each simulation requires hundreds of calls to an LLM API, specifically:
- Generating responses to the question (10 per round)
- Generating articles based on responses (1-10 per round)
- Computing the same answer percentage metric (10 per round)
- Extracting entities (10 per round)
- Extracting relevant content (1 per citation)
Many of the calls involve large inputs and outputs (e.g., full articles).
As a result, the simulation often costs $5 or more per question. Therefore, we cannot reasonably evaluate every combination of dataset, simulation, and model.
For the Larger-Scale Experiments, to help reduce costs, we also detect whether the simulation converges. We stop the simulation if the Same Answer % (defined below) is 100% in four consecutive rounds.
Datasets
Getting access to real user prompts is challenging. Instead, we translate Google search keywords to information-seeking question prompts or write them manually.
Entity Questions
A category of particular interest is entity comparison questions, or entity questions for short. Answers to entity questions compare different named entities, such as products, brands, businesses, and locations. For example, “What are the best restaurants in San Francisco?” These are the types of prompts that marketers target for answer- and generative-engine optimization.
We collect entity questions from a variety of sources:
- The Graphite prompt tracking tool (often translated from high-volume search keywords)
- The categorized keywords dataset from our previous paper
- Manually written questions on topics of particular interest
Editorial Questions
We also experiment with a more general set of questions that are neither entity comparisons nor factual. Factual questions like “Who were the draft picks for the Commanders in 2023?” have one correct answer, and, as a result, responses will already be collapsed (correctly). An example question in this category is "How can I improve my personal branding?" We call these editorial questions. These questions are translated from the categorized keywords dataset in our previous paper.
Original References
As described above, we need references to initialize the simulations, and we gathered them from ChatGPT and Google AI Overviews in January 2026. For each dataset, we filter out questions that do not trigger a web search in ChatGPT or do not produce an AI Overview in Google Search. (In ChatGPT, we could force the use of web search, but we suspect few users do this.)
Dataset Statistics
name | questions |
|---|---|
Entity ChatGPT | 843 |
Editorial ChatGPT | 159 |
Entity AI Overview | 60 |
Editorial AI Overview | 45 |
The AI Overview questions and ChatGPT questions largely overlap but are not identical due to differences in whether an AI Overview appeared and whether ChatGPT used the web search tool. Across all datasets, there are 1,019 unique questions.
AI-Generated Original References
The references in our dataset were collected in January 2026. We also collected new references for the questions from ChatGPT in early June 2026.
We noted in the introduction that much of the web is AI-generated. Are the original references AI-generated?
Surprisingly, we find that 38.9% of ChatGPT references in January 2026 and 42.7% in June 2026 are predicted to be AI-generated. There are more AI-generated references with Entity prompts than with Editorial, and for both Entity and Editorial prompts, the percentage of AI-generated references increased from January 2026 to June 2026. We plan to explore this in depth in a forthcoming paper.
Overall | Entity | Editorial | |
1/26 ChatGPT | 38.9% [38.0, 39.9] | 41.1% [40.1, 42.1] | 20.6% [18.3, 23.0] |
6/26 ChatGPT | 42.7% [41.7, 43.7] | 45.8% [44.7, 46.8] | 27.5% [25.4, 29.7] |
Brackets are 95% Wilson confidence intervals, computed over unique reference URLs.
Evaluation Metrics
To measure how responses change over the rounds of the simulation, we use the following metrics:
Semantic similarity measures the semantic similarity of pairs of responses generated in the same round. A larger value means the responses are more similar to each other. It is computed as the average cosine similarity between the embeddings of response pairs.
Unique words measures the number of distinct words across all 10 responses in a round.
Self-authored citation percentage measures the percentage of citations of self-authored references. In some plots, we show the self-authored citation percentage alongside the expected percentage based on the proportion of self-authored references in the context. In others, we show the self-authored citation percentage relative to the expected percentage (100 * (observed − expected) / expected), so that values above zero indicate disproportionate citation of self-authored references. We call this metric Self-Authored Citations Over Expected. Note that Self-Authored Citations Over Expected is not defined for the Replace All Simulation, as all references are self-authored after the first round. By round 10 in the Replace One simulation, all references are self-authored, so the value drops to 0. In the Search simulation, self-authored references make up an increasing proportion of the reference pool over rounds, so the value approaches 0.
Self-authored retrievals measures the percentage of retrieved chunks that are self-authored in the Search simulation.
Same answer percentage measures the proportion of pairs of responses that are paraphrases of each other. We use GPT-5.2 to evaluate whether two responses are paraphrases. To reduce costs, we sample 10 of the 45 possible unique pairs of 10 generations in each round.
Entity Question Metrics
For Entity Questions, we additionally identify the entities mentioned in each response and use them to compute additional metrics.
Entities are often referred to by several names, so in addition to extracting them, we need to canonicalize them. Responses also often mention entities that are not part of the answer. For example, responses to the prompt “What are the best restaurants in California?” will include entities such as “San Francisco” and “Dominique Crenn”, but the entities we care about here are restaurant names. We use the following algorithm:
1. Extract the entities being listed or compared in each response in each round using an LLM.
2. Cluster unique entity mentions into groups that refer to the same canonical entity across all simulation rounds.
3. To capture entity mentions the LLM missed, search for exact matches of entities in the canonical map across all simulation rounds.
Unique entities measures the number of distinct entities mentioned across all responses in a round.
Entity ranking similarity measures the similarity of the rankings of entity mentions across pairs of responses generated in the same round. In particular, we rank the entities by the position of their first mention. We use Kendall’s tau as the similarity metric. If two responses mention entities in the same order, the entity ranking similarity is 1.0.
We report the mean of these metrics for each round across all questions in the dataset.
Defining Collapse
The more similar responses to a prompt are, the more collapsed we consider them to be. Complete collapse would mean that every single response is exactly the same. However, in practice, we care about whether responses essentially say the same thing, even if they are not word-for-word identical.
For Entity Questions, there is a natural and intuitive representation of collapse: whether the entities being listed or compared are the same. Therefore, we consider responses collapsed when entities are identical across all responses in a round.
For Editorial Questions, there is no comparable compact representation of the answer, so we instead consider a set of responses to be collapsed when the same answer percentage is 100%.
Collapsed at start is the percentage of questions that are collapsed after round 1, before any self-authored references have been introduced.
Collapsed at end is the percentage of questions that are collapsed at the end of the simulation.
Rounds collapsed is the percentage of total rounds across all simulations for a set of questions in which responses were collapsed.
Experiments
Experiment Summary
In the table below, we summarize the experiments presented in this report. Most simulations end in collapse.
Simulation | Model | Dataset | Questions | Collapsed at Start | Collapsed at End | Rounds Collapsed |
|---|---|---|---|---|---|---|
Replace All | GPT-5.2 Chat | Entity ChatGPT | 101 | 2.97% | 88.12% | 68.51% |
Replace All | GPT-5.2 Chat | Editorial ChatGPT | 57 | 29.82% | 91.23% | 79.65% |
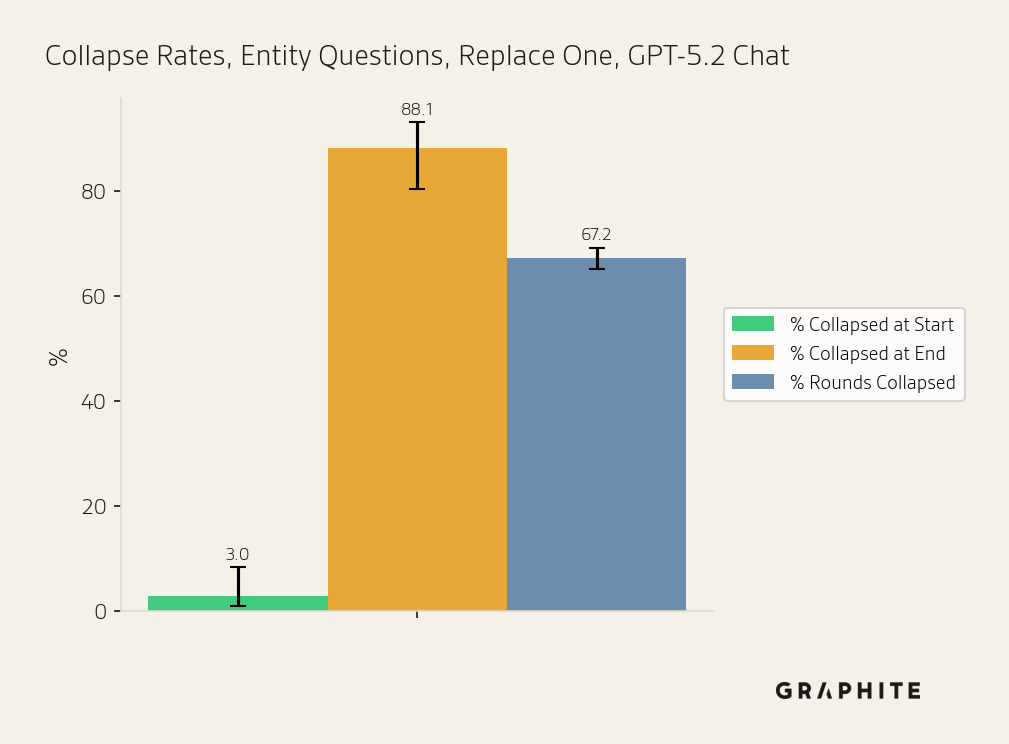
Replace One | GPT-5.2 Chat | Entity ChatGPT | 101 | 2.97% | 88.12% | 67.18% |
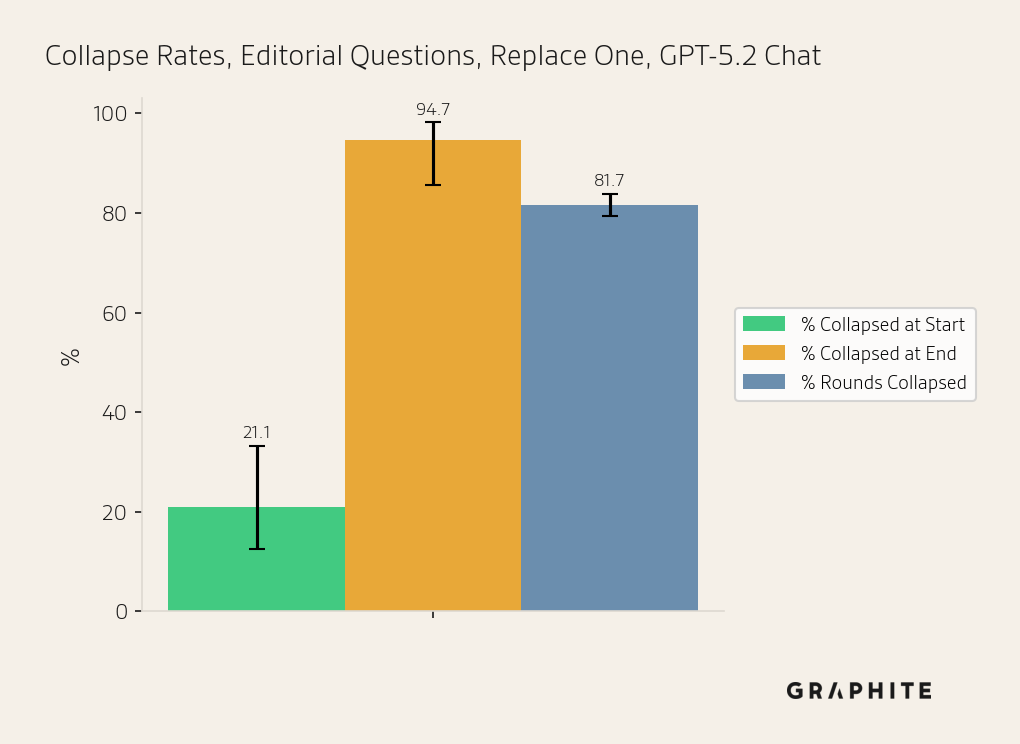
Replace One | GPT-5.2 Chat | Editorial ChatGPT | 57 | 21.05% | 94.74% | 81.67% |
Search | GPT-5.2 Chat | Entity ChatGPT | 101 | 1.98% | 77.23% | 62.31% |
Search | GPT-5.2 Chat | Editorial ChatGPT | 57 | 31.58% | 75.44% | 73.63% |
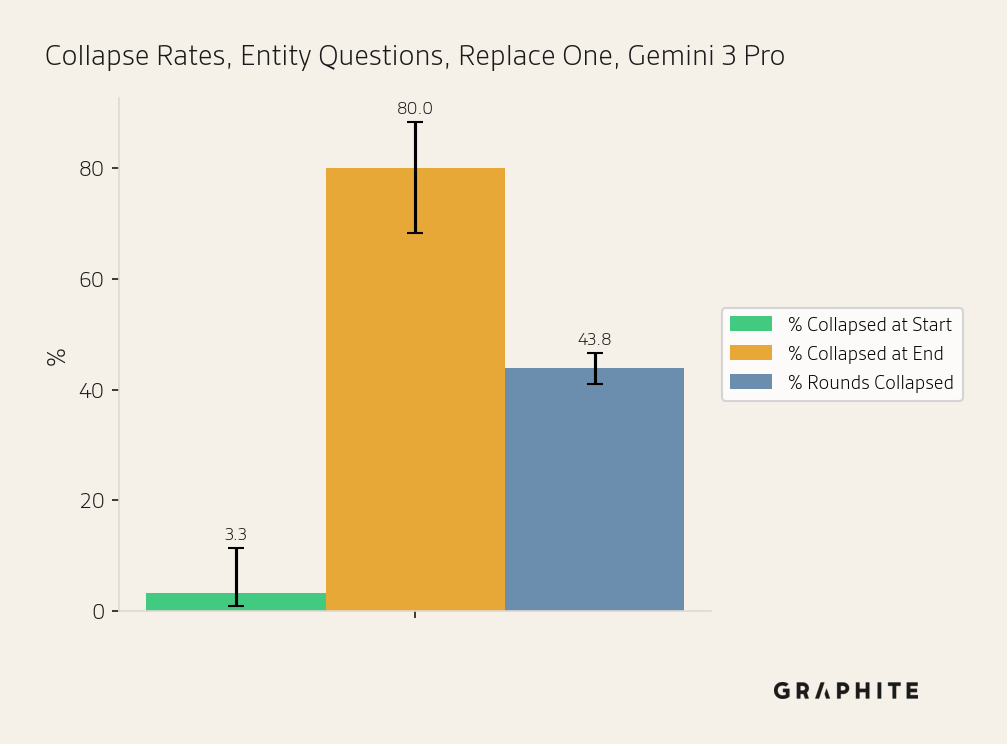
Replace One | Gemini 3 Pro | Entity AI Overview | 60 | 3.33% | 80.00% | 43.83% |
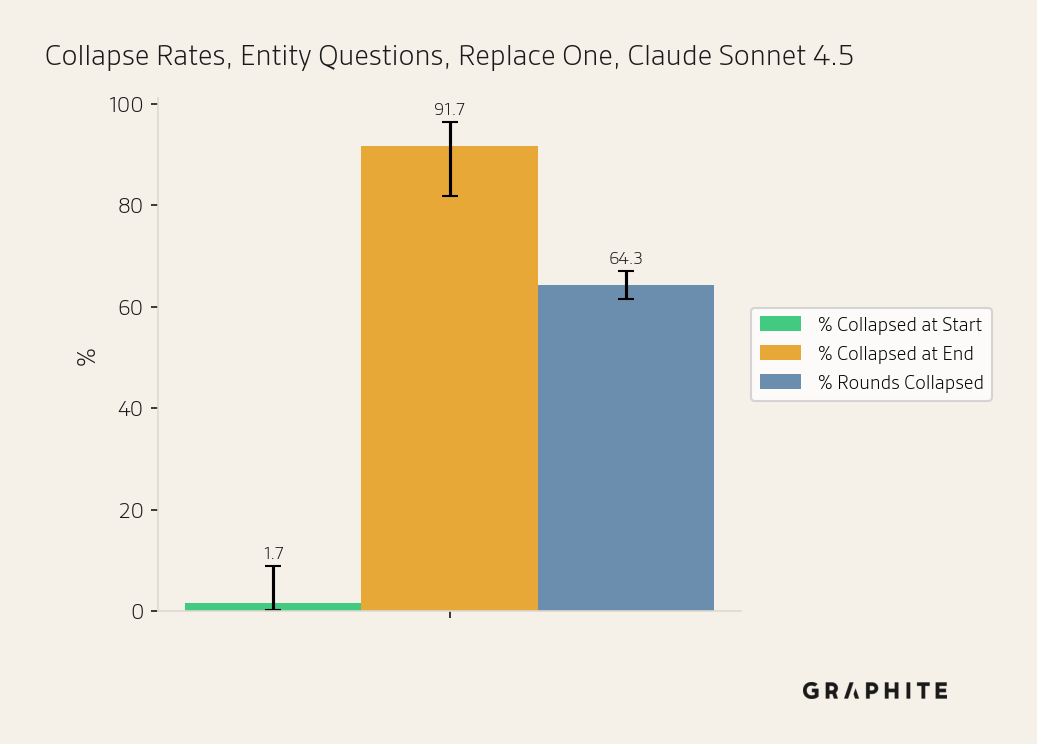
Replace One | Claude Sonnet 4.5 | Entity AI Overview | 60 | 1.67% | 91.67% | 64.33% |
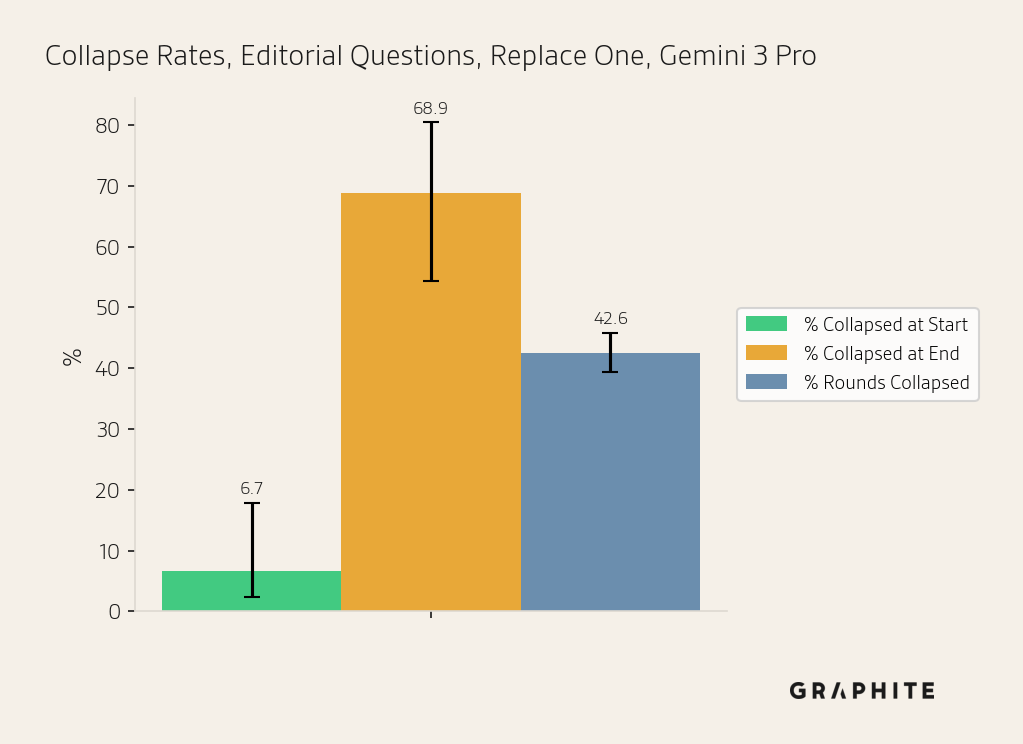
Replace One | Gemini 3 Pro | Editorial AI Overview | 45 | 6.67% | 68.89% | 42.56% |
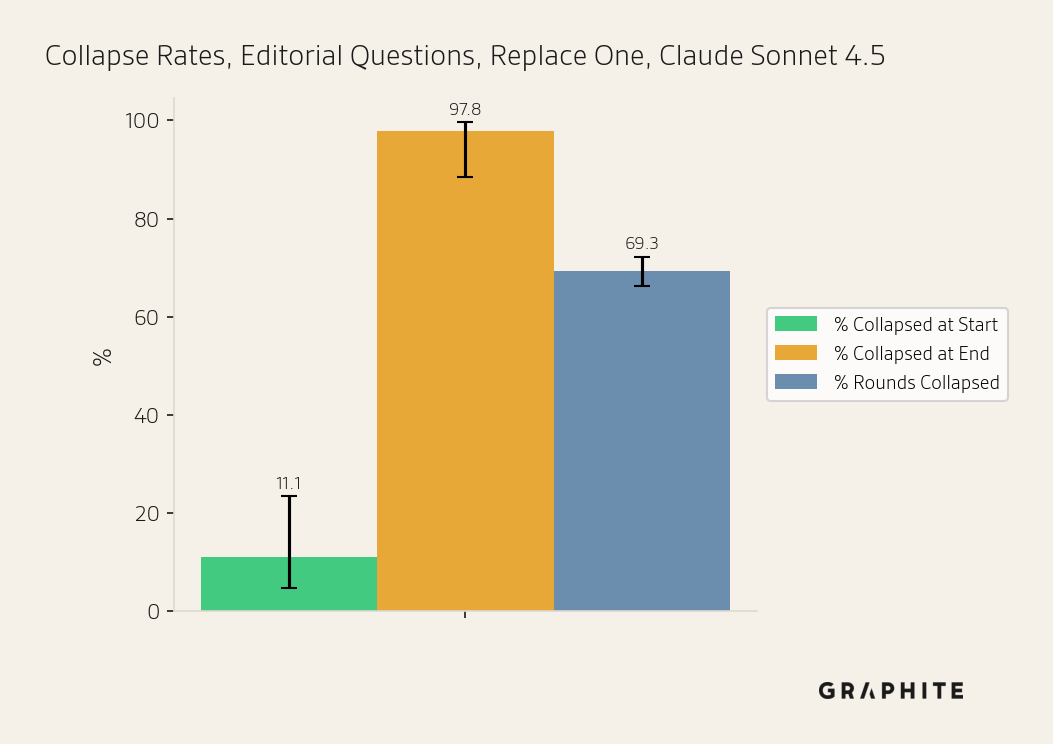
Replace One | Claude Sonnet 4.5 | Editorial AI Overview | 45 | 11.11% | 97.78% | 69.33% |
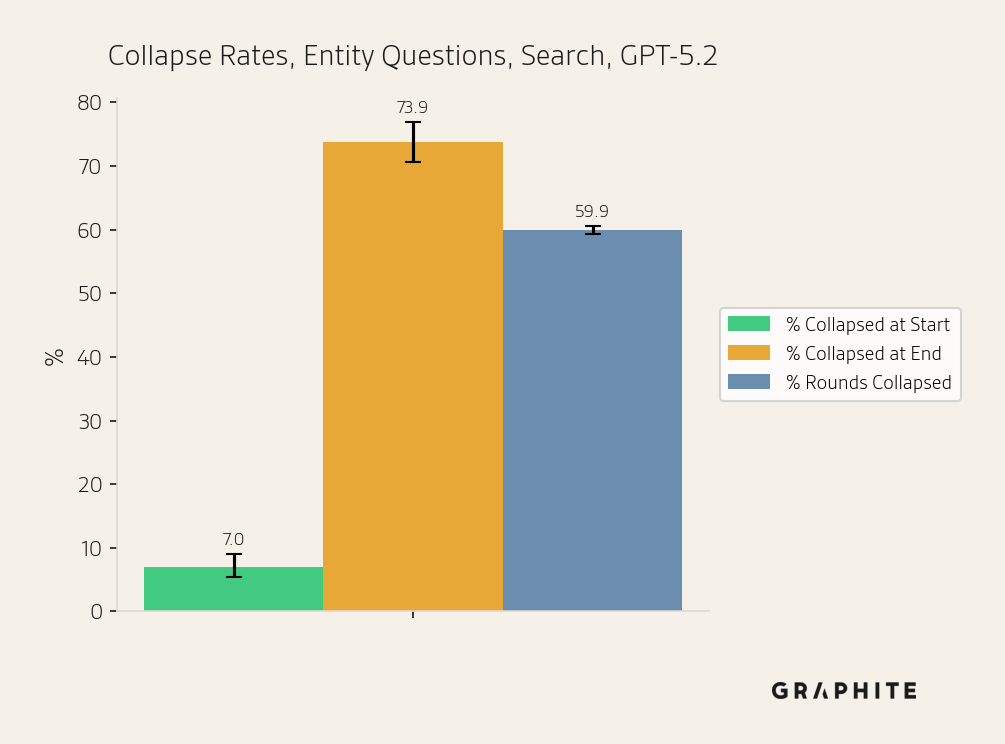
Search | GPT-5.2 | Entity ChatGPT | 742 | 7.01% | 73.85% | 59.93% |
Search | GPT-5.2 | Editorial ChatGPT | 102 | 7.84% | 83.33% | 65.85% |
See Simulation Implementation Details for the distinction between GPT-5.2 and GPT-5.2 Chat.
We consistently find the following across experiments:
- The number of unique words and entities mentioned across responses in a round decreases over the course of the simulation.
- The semantic similarity between responses and the similarity between the entities mentioned increase over the course of the simulation.
- When both original and self-authored references are available, the models disproportionately cite the self-authored references.
In the following sections, we review the results in detail.
All raw data from experiments is available here.
Comparison of Simulations
We first compare the three simulations using GPT-5.2 Chat with 101 prompts from Entity ChatGPT and 57 from Editorial ChatGPT.
After running the Replace All simulation for 10 rounds, replacing all the references with self-authored references after each round, we find that 88.1% of Entity questions and 91.2% of Editorial questions collapse. The semantic and entity ranking similarities across responses in a round increase as the simulation progresses. The same answer percentage also increases. Unique words and entities decrease.
In the Replace One simulation, we replace one reference with a self-authored reference in each round. Because the Replace One simulation has a mix of self-authored and original references in the early rounds (while Replace All replaces all references after each round), we would expect collapse to be slower and less frequent. Instead, we find that the collapse begins almost immediately, and the Replace One simulation leads to collapse as often as Replace All for Entity (88.1%) and Editorial Questions (94.7%).
This result is surprising. We find that self-authored references disproportionately influence the answer. We see in the figures below that the rate of self-authored references cited in the response far exceeds expectations based on the number of self-authored versus original references. We investigate bias in detail in the “Why Do Self-Authored References Have Disproportionate Influence?” section.
Finally, in the Search simulation, rather than replacing references with self-authored articles, we add them to a content pool and retrieve relevant documents from it. The collapse rate is lower in the Search simulation, but the absolute rates remain high: 77.2% and 75.4% for Entity and Editorial questions, respectively. This demonstrates that collapse occurs frequently even in our most realistic simulation.
In the figures below, we display the Collapsed at Start, Collapsed at End, and Rounds Collapsed rates for each simulation. For error bars, we use Wilson score intervals.
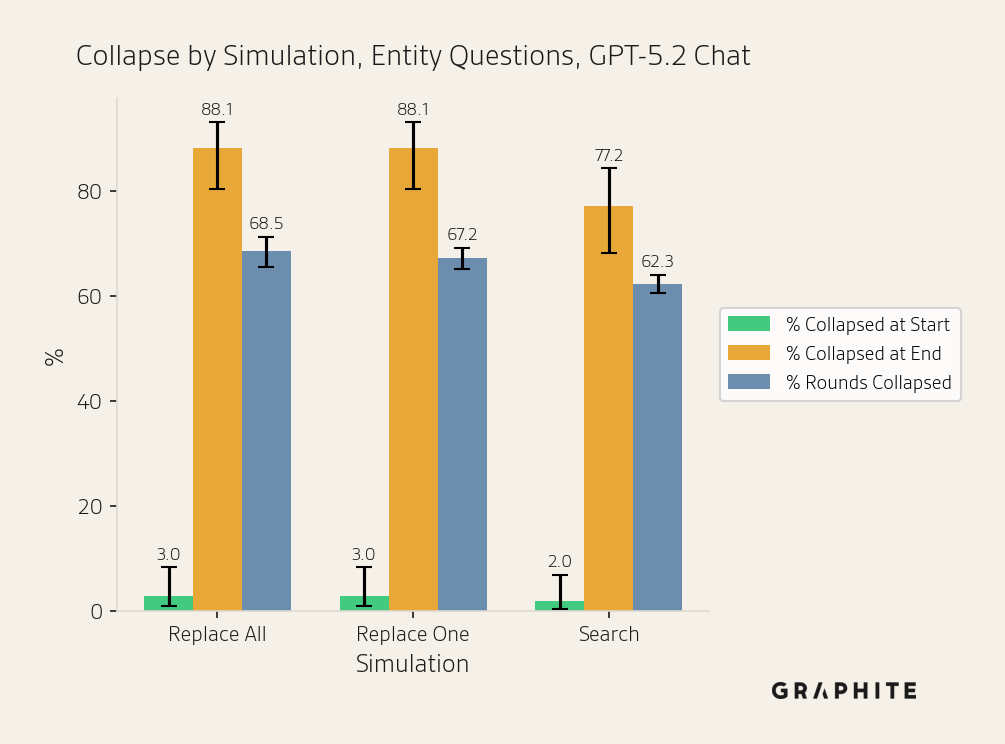
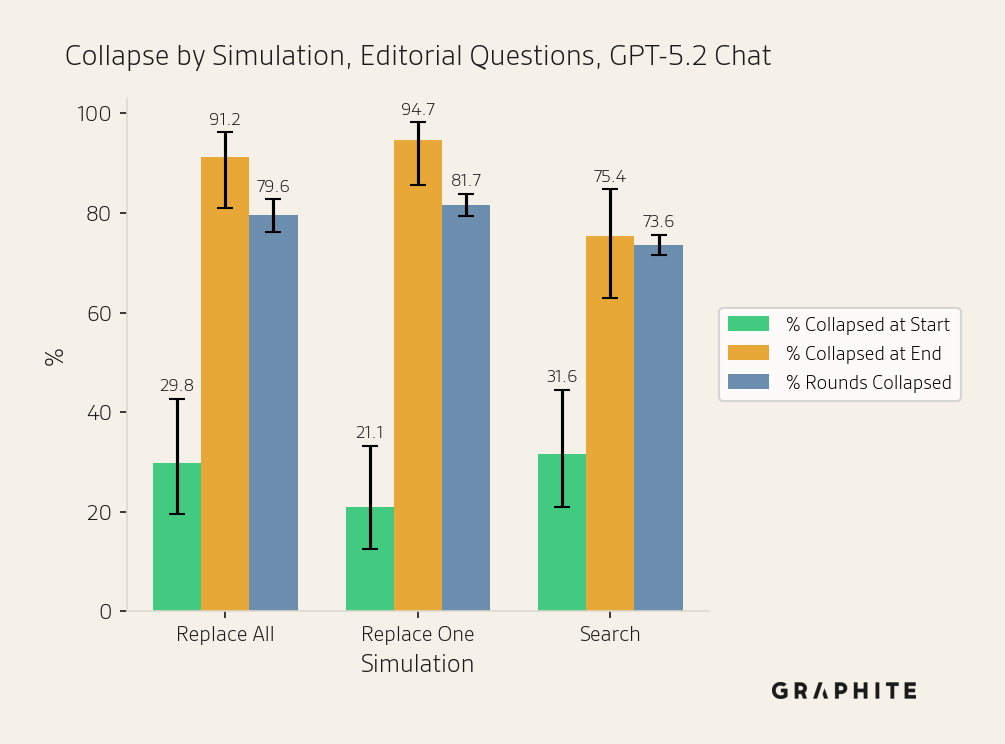
Note that Collapsed at Start rates may vary between Search and the other simulations because Search uses chunks, and rates may also vary generally due to random variation in responses.
The next set of figures plots the percentage of questions collapsed per round for different simulations. This illustrates the surprising finding that Replace One and Search start to collapse immediately, even with a small percentage of self-authored references. By round 2, after a single self-authored reference has been added (10-20% of the reference pool), 22.8% of Replace One Entity questions have collapsed, not much lower than 28.7% for Replace All, where every reference is self-authored. A small share of self-authored references produces most of the collapse that full replacement does, underscoring their disproportionate influence. The same pattern holds for Editorial questions (50.9% vs 64.9%).
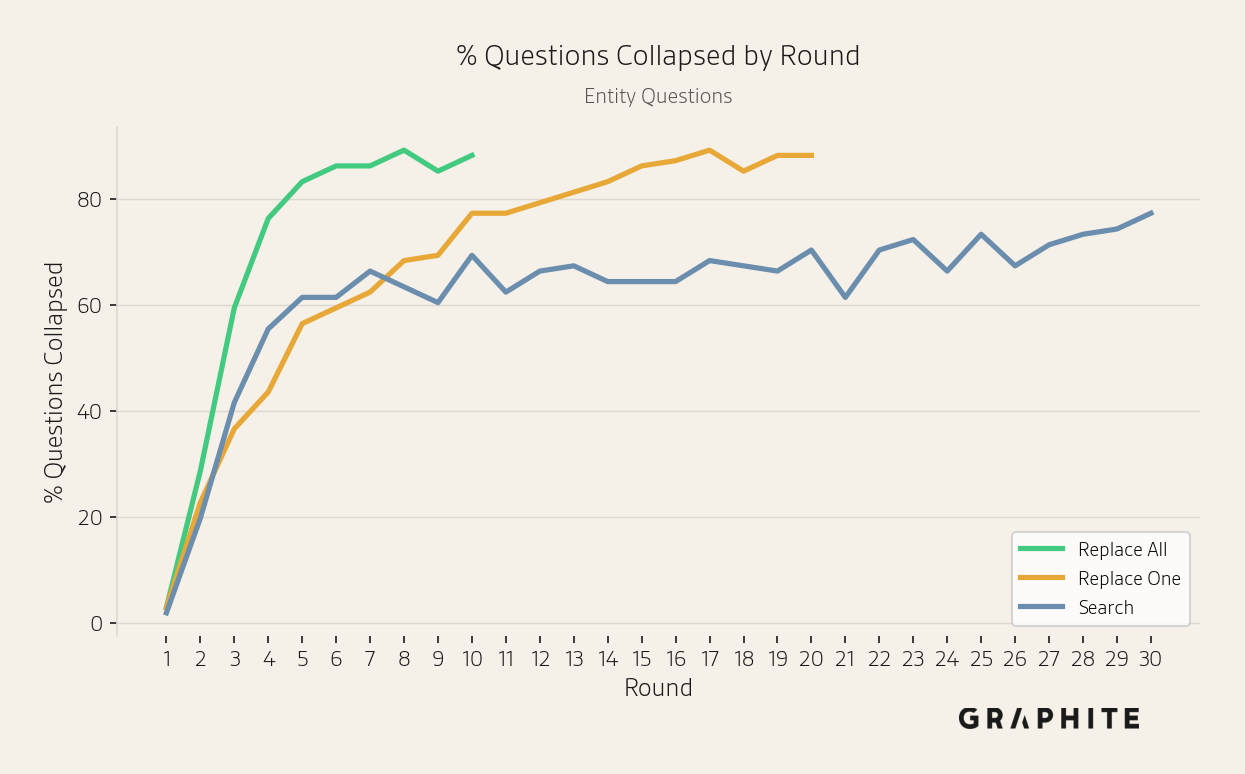
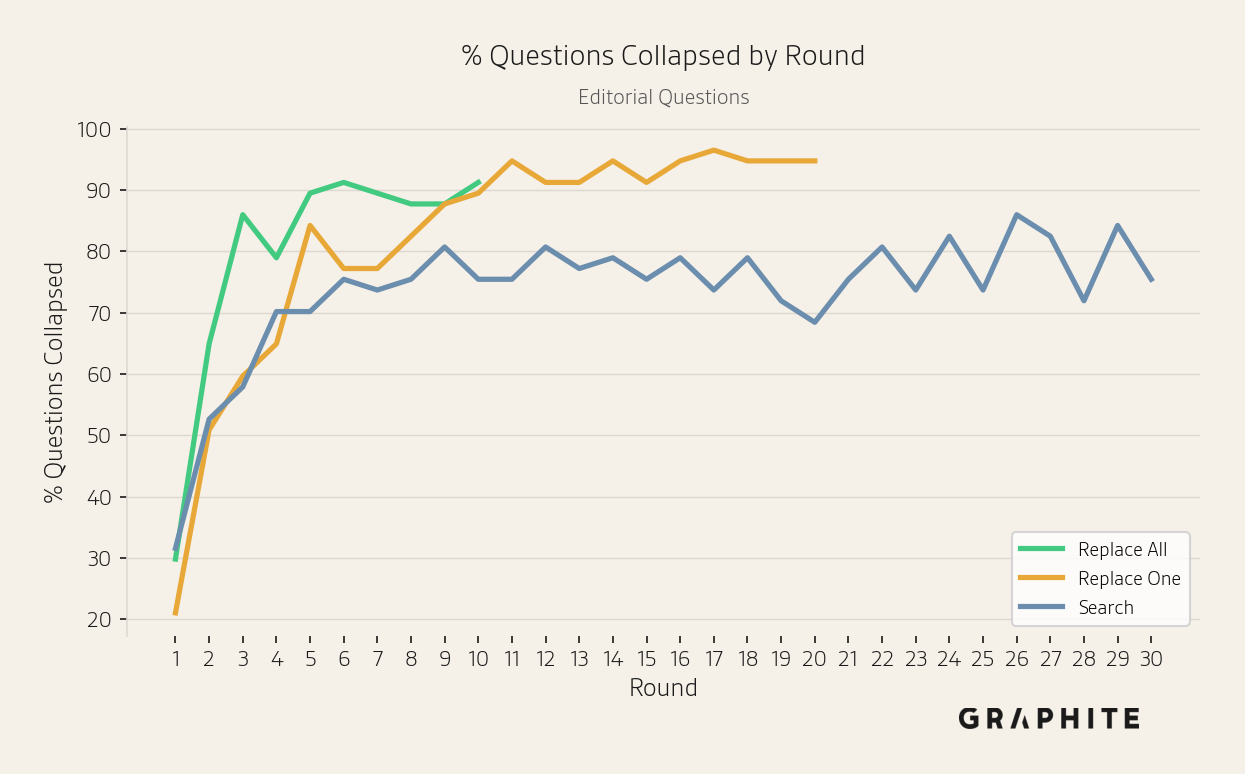
Next, we present additional metrics that illustrate the simulations' behavior. For error bands for metric-by-round line charts, we use one standard error above and below the mean.
Entity Questions
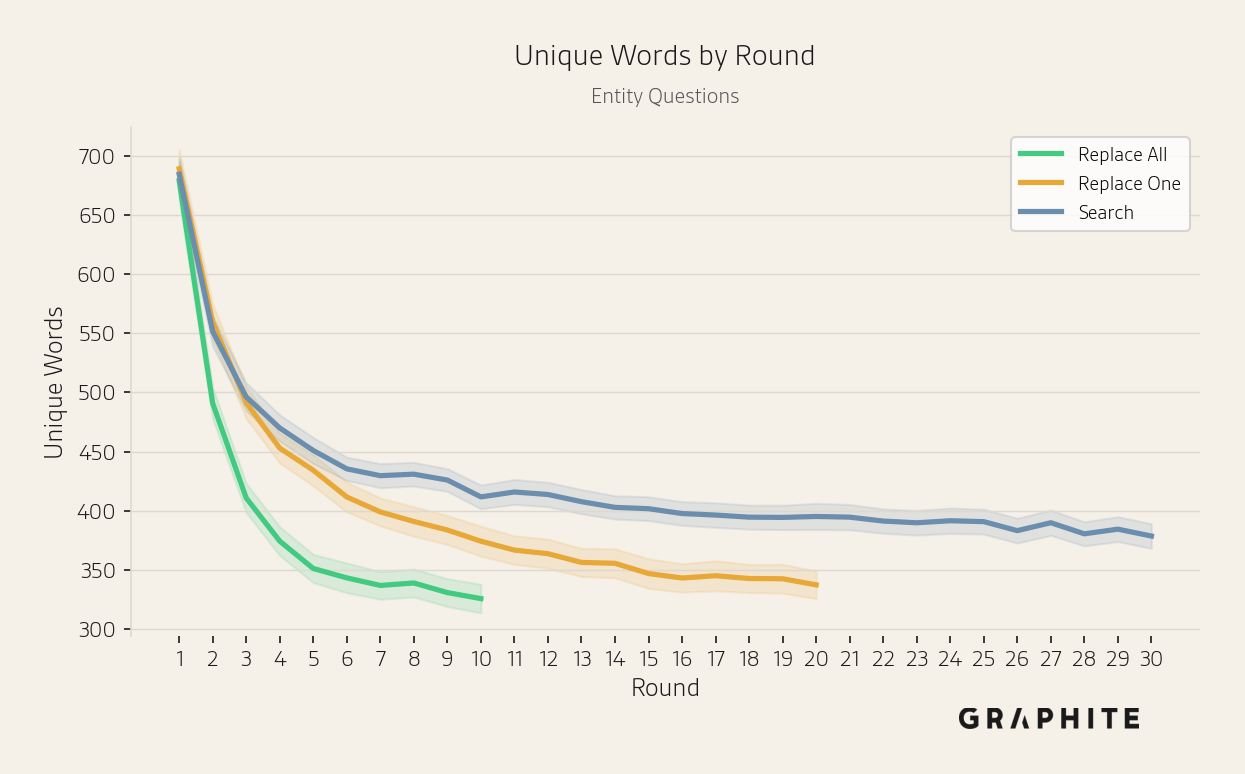
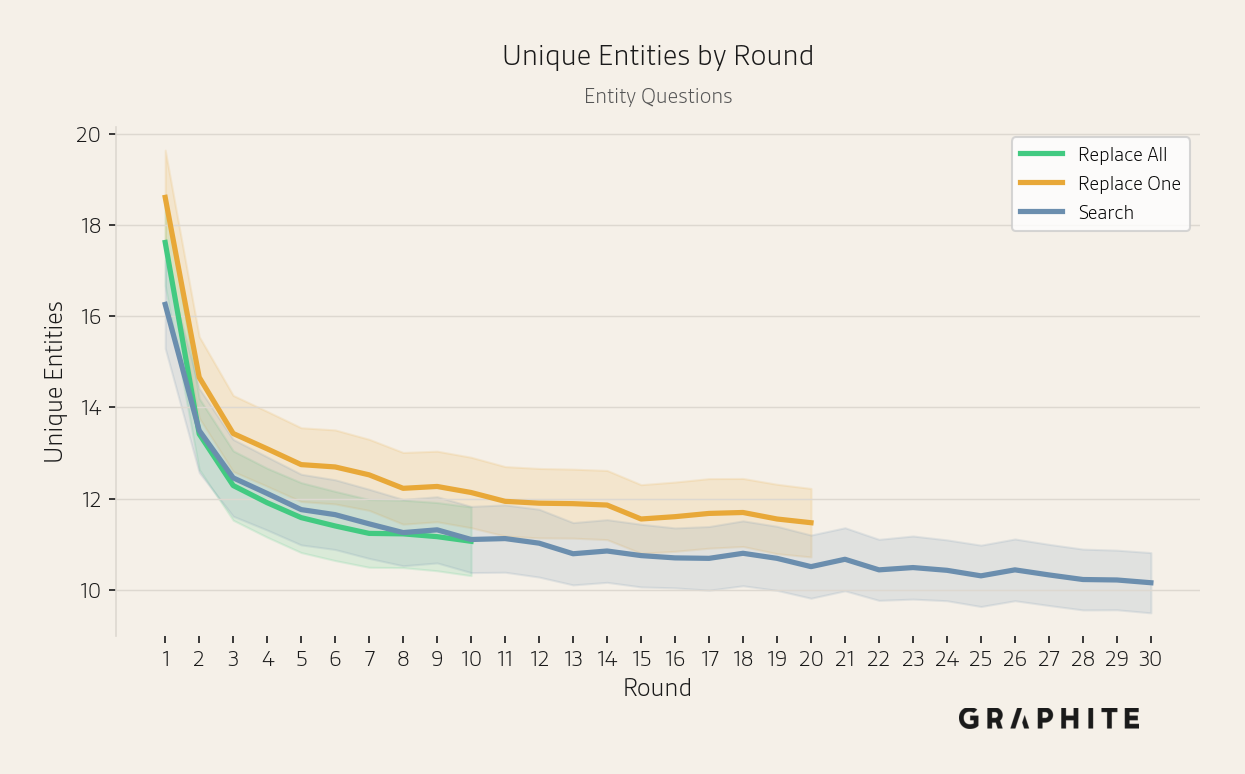
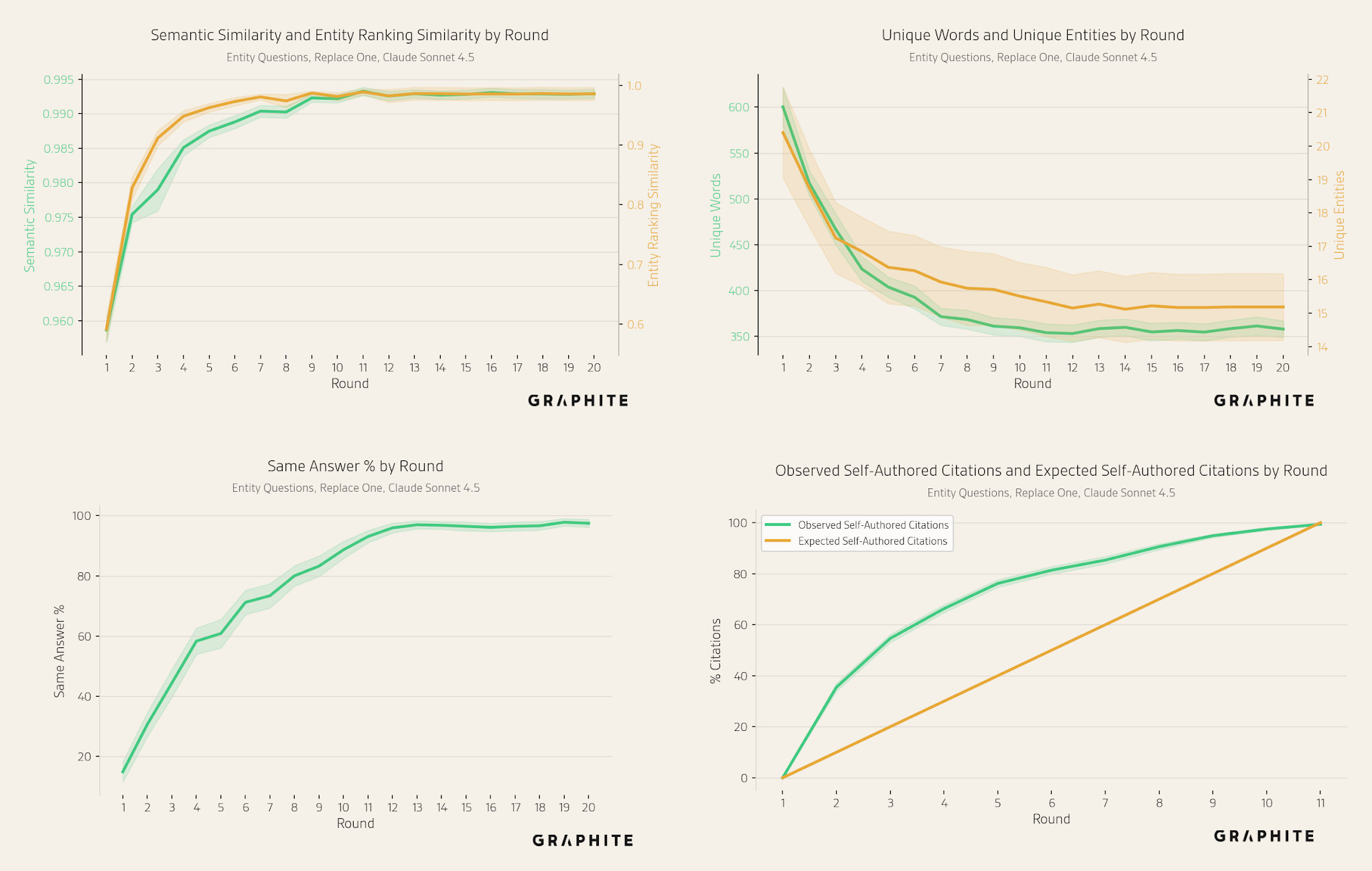
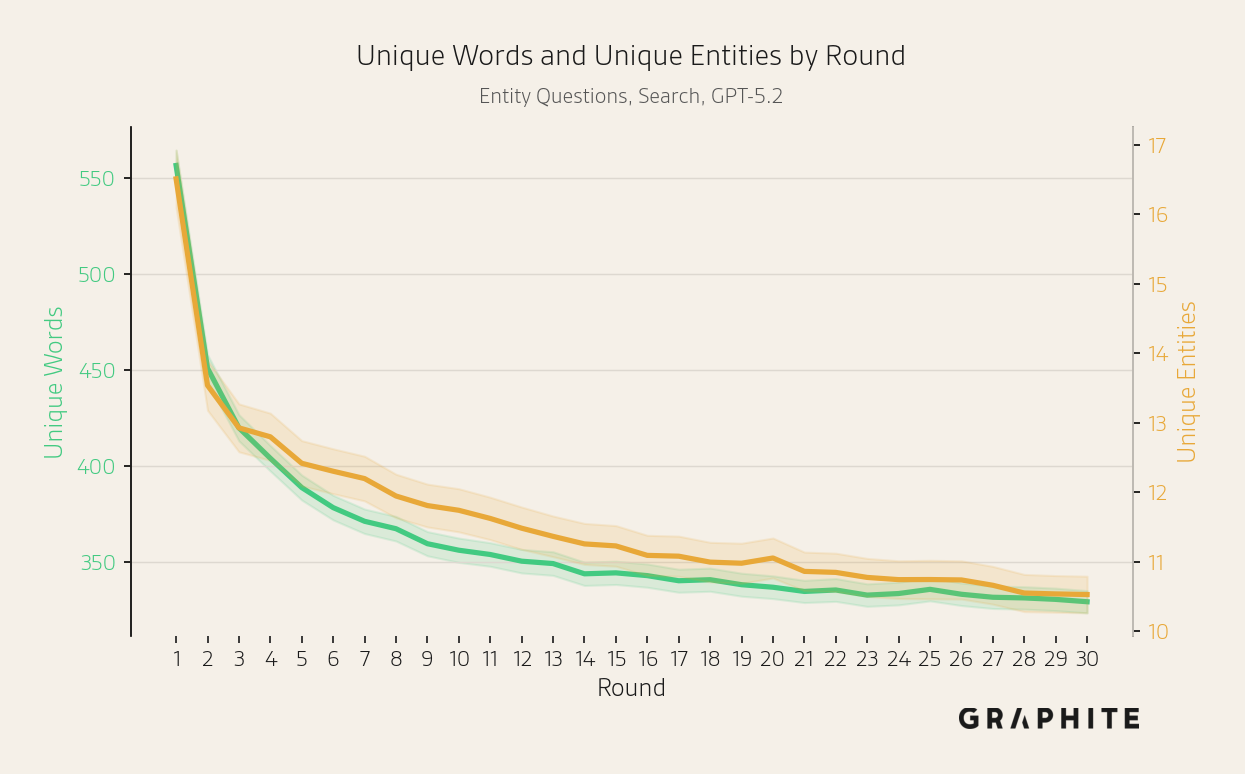
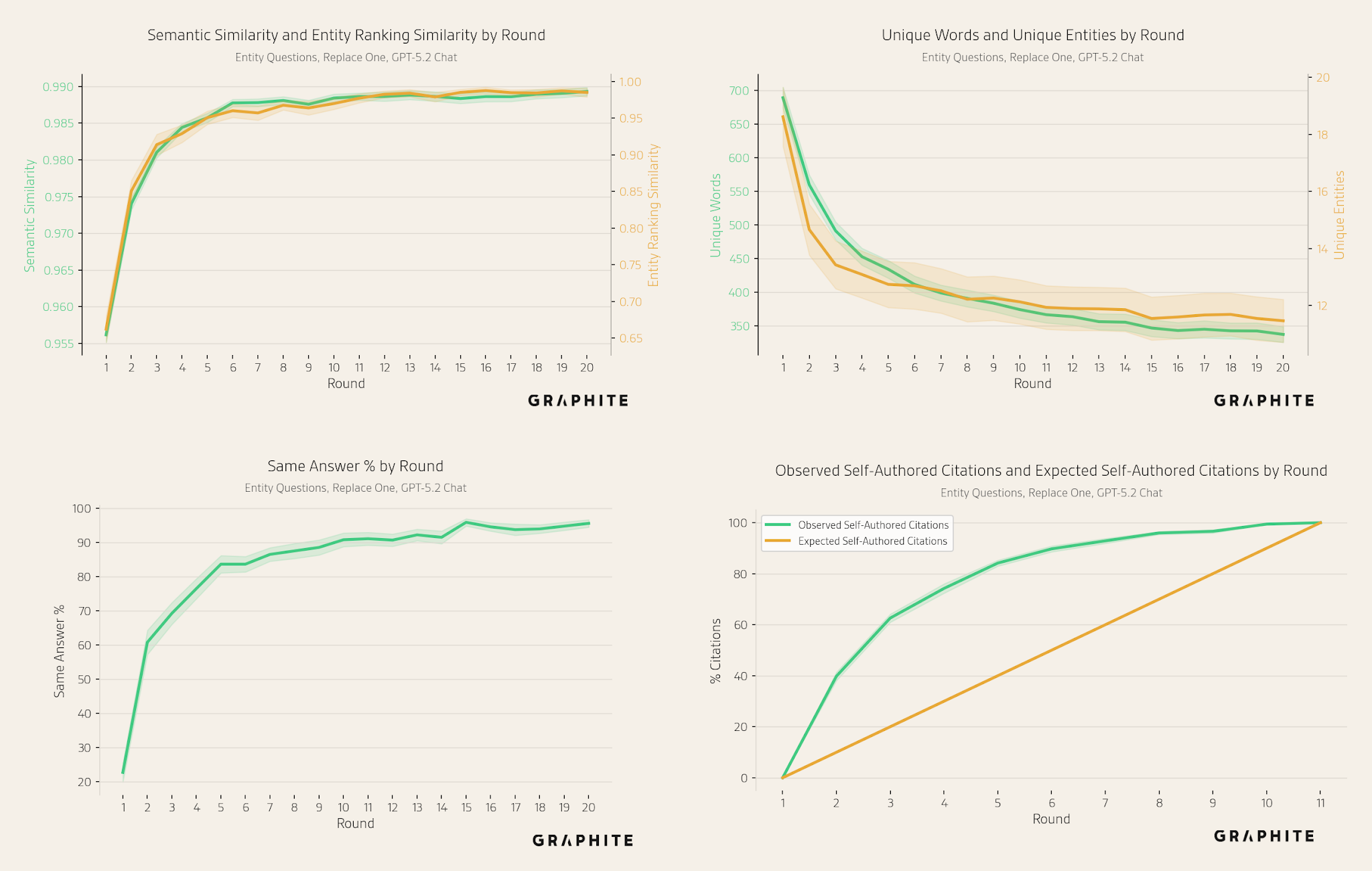
The unique sets of entities and words mentioned across responses decrease over rounds, indicating a decline in response diversity.
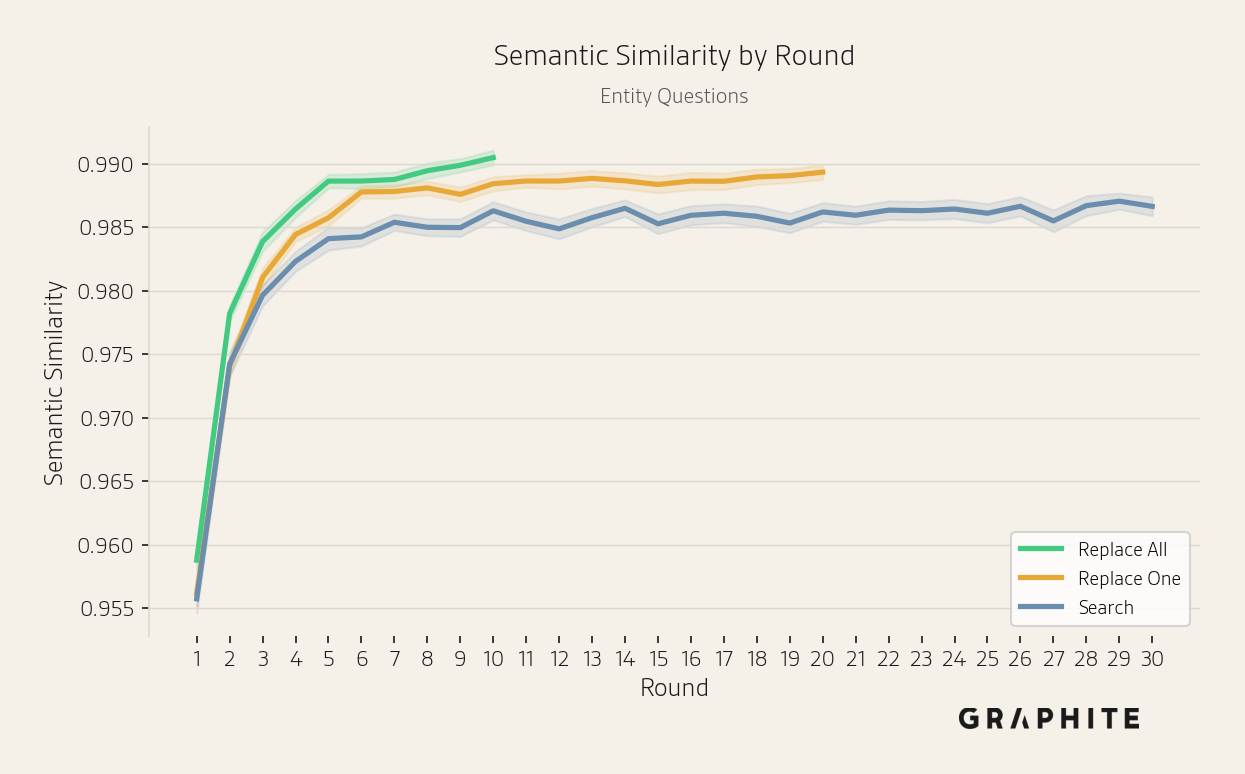
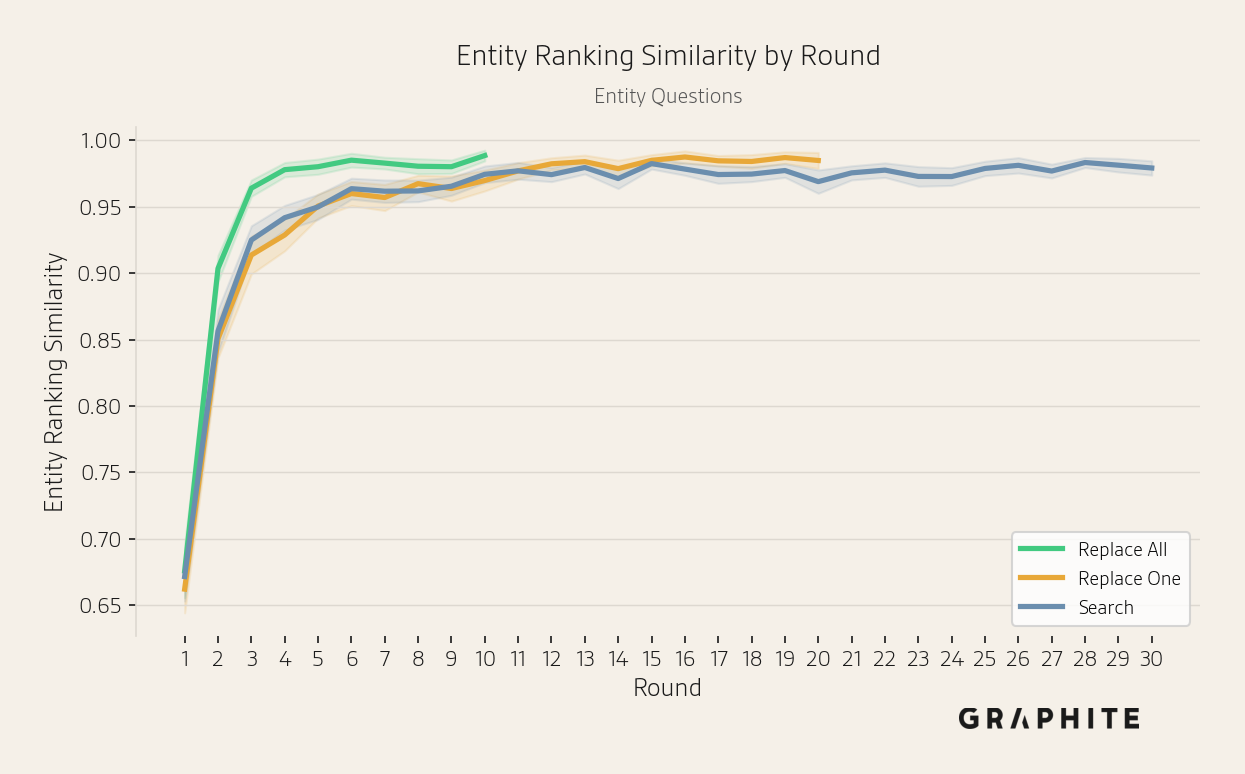
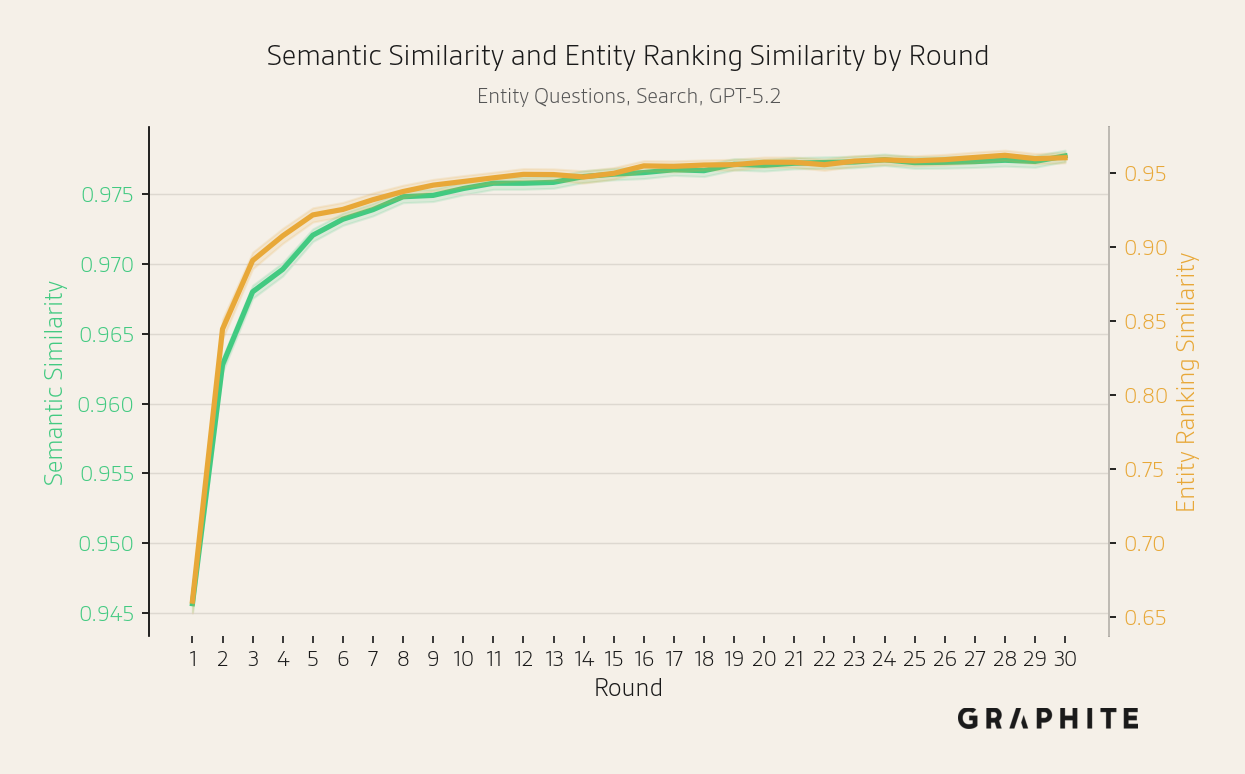
The semantic and entity ranking similarities among pairs of responses generated in the same round increase across rounds.
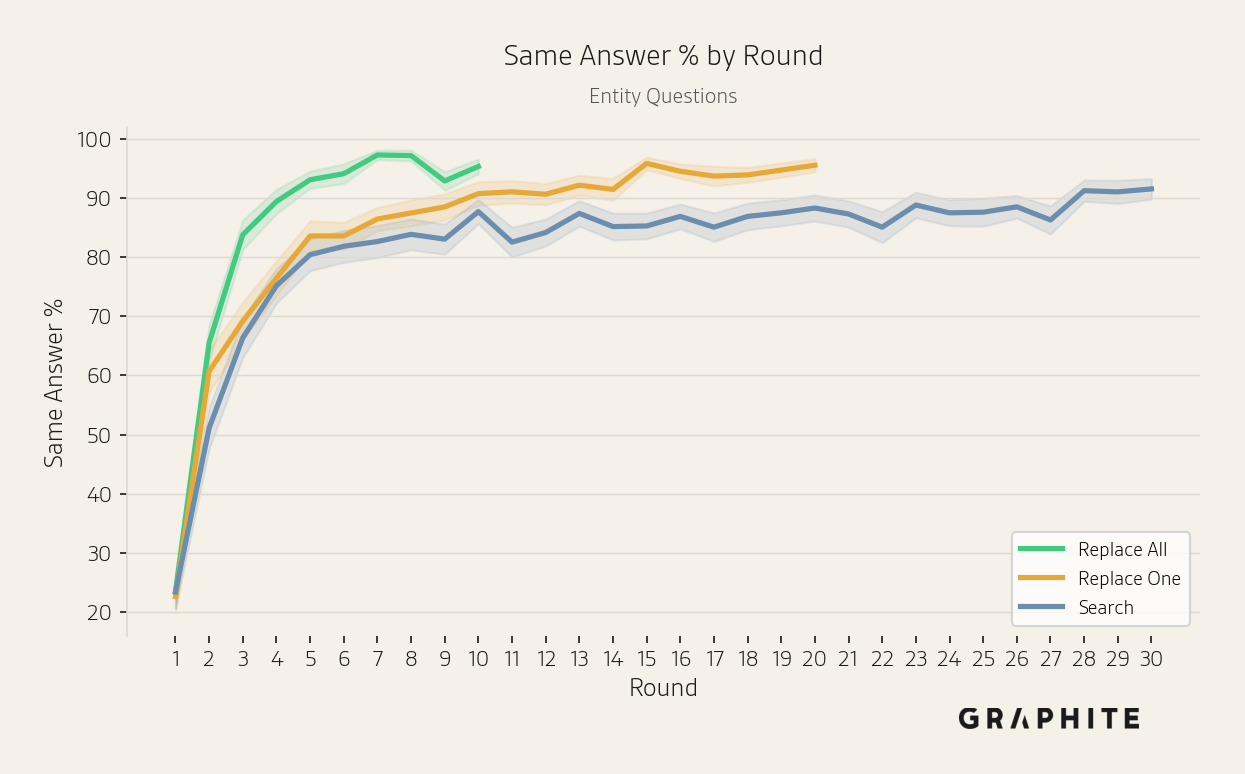
The same answer percentage increases, from less than 30% in Round 1 to over 90%.
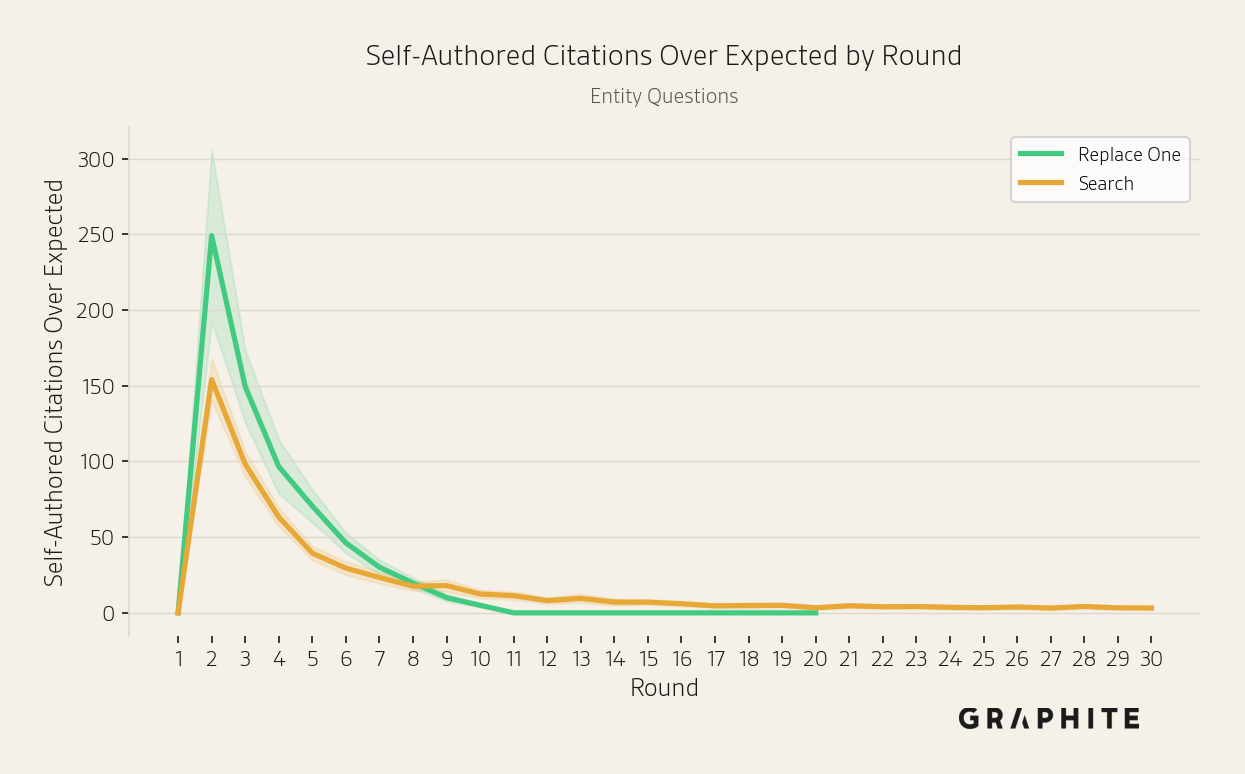
The percentage of self-authored citations increases and is generally higher than expected based on their proportion of the reference pool.
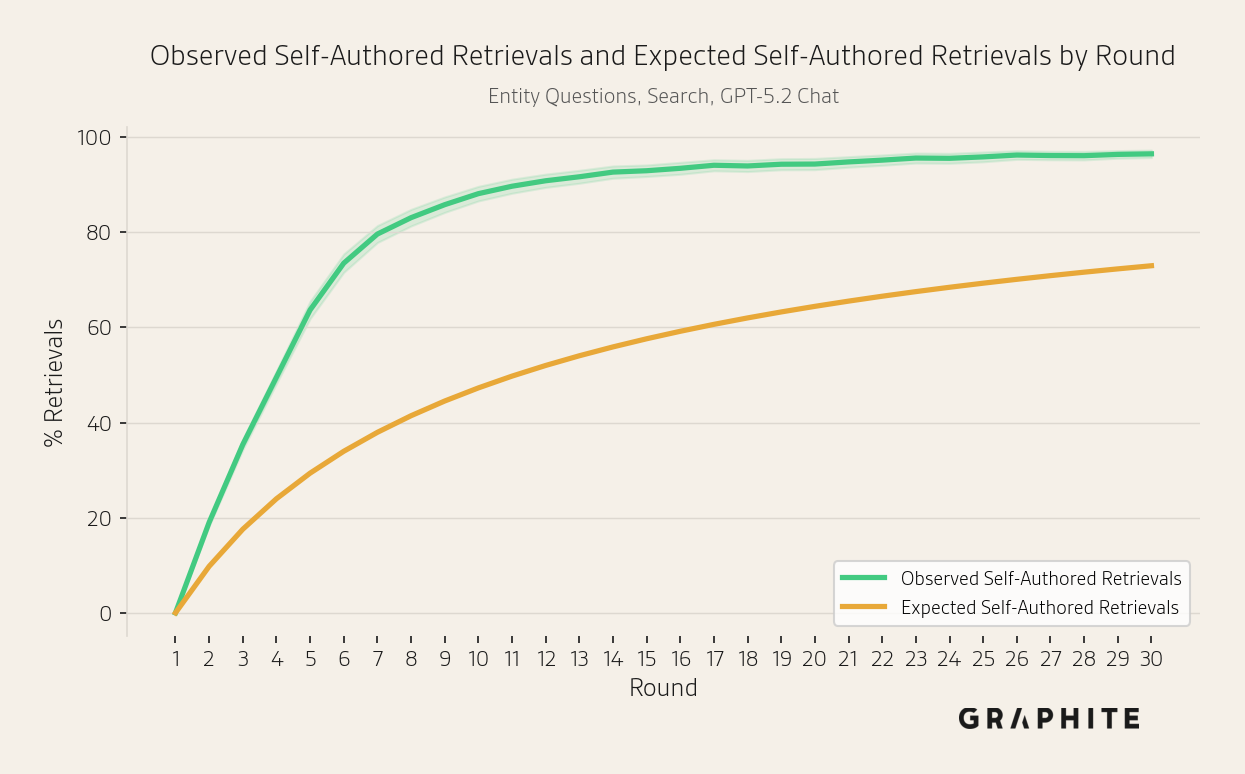
As with citations, in the Search simulation more self-authored references are retrieved than would be expected by chance. Note that there is no retrieval in the Replace All and Replace One simulations.
Editorial Questions
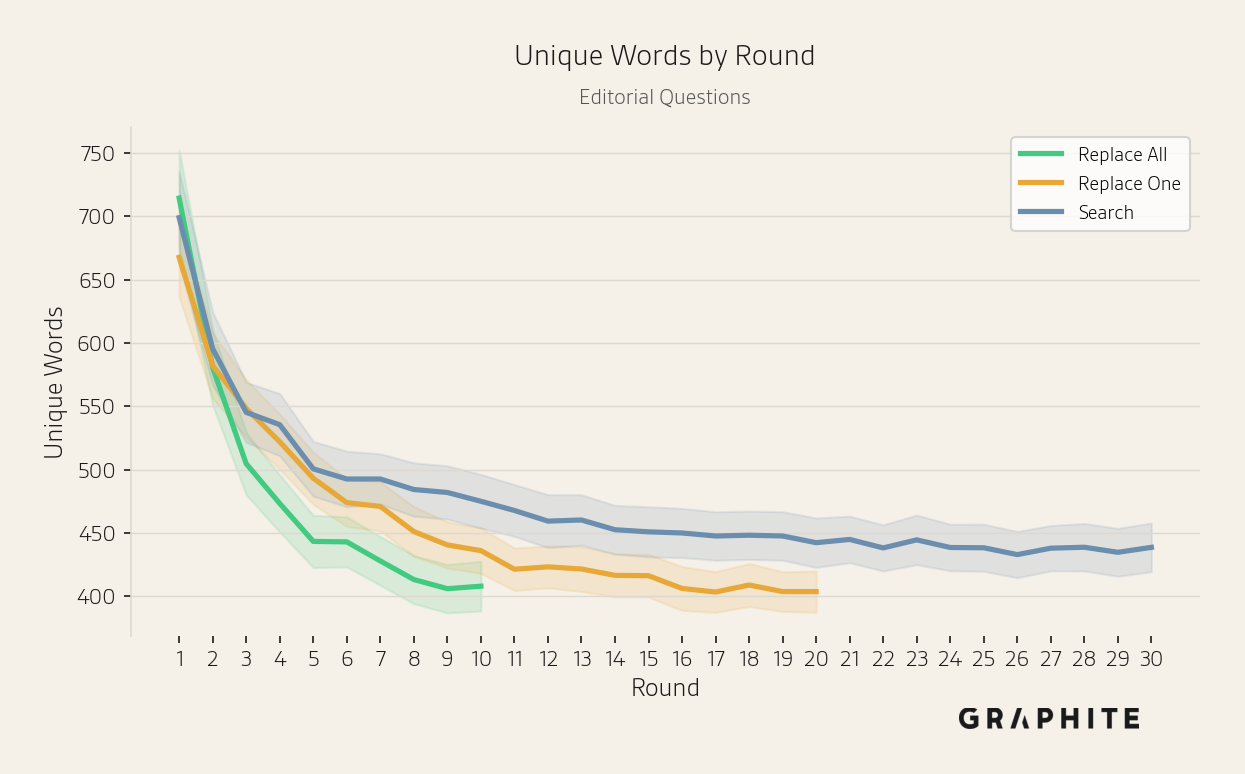
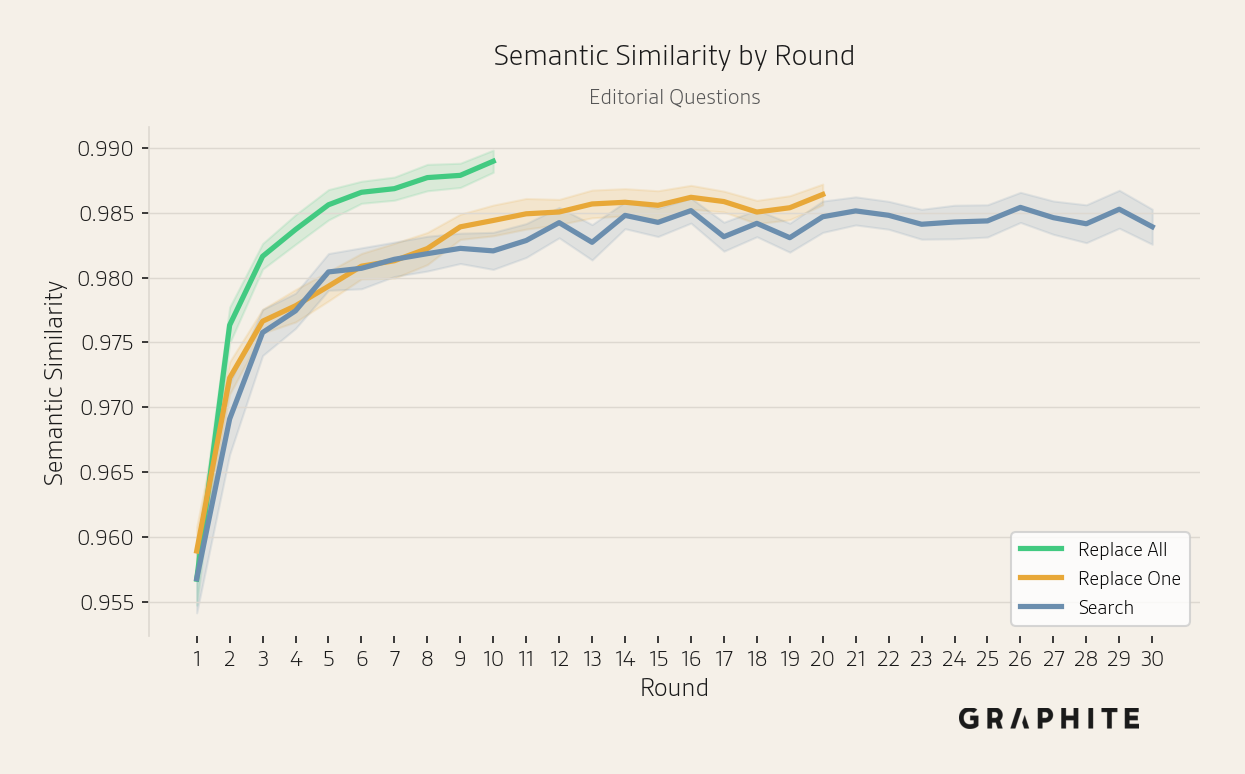
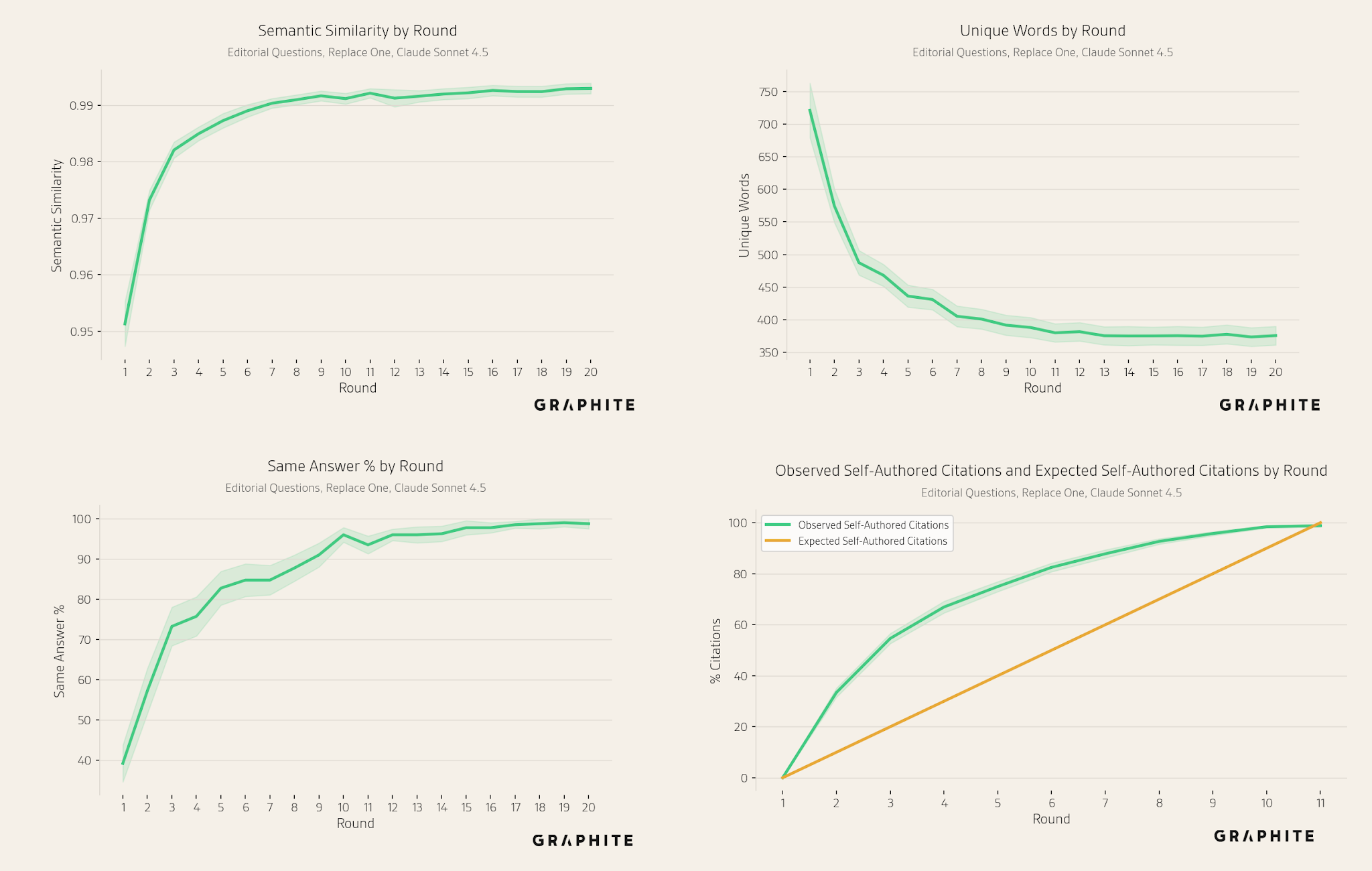
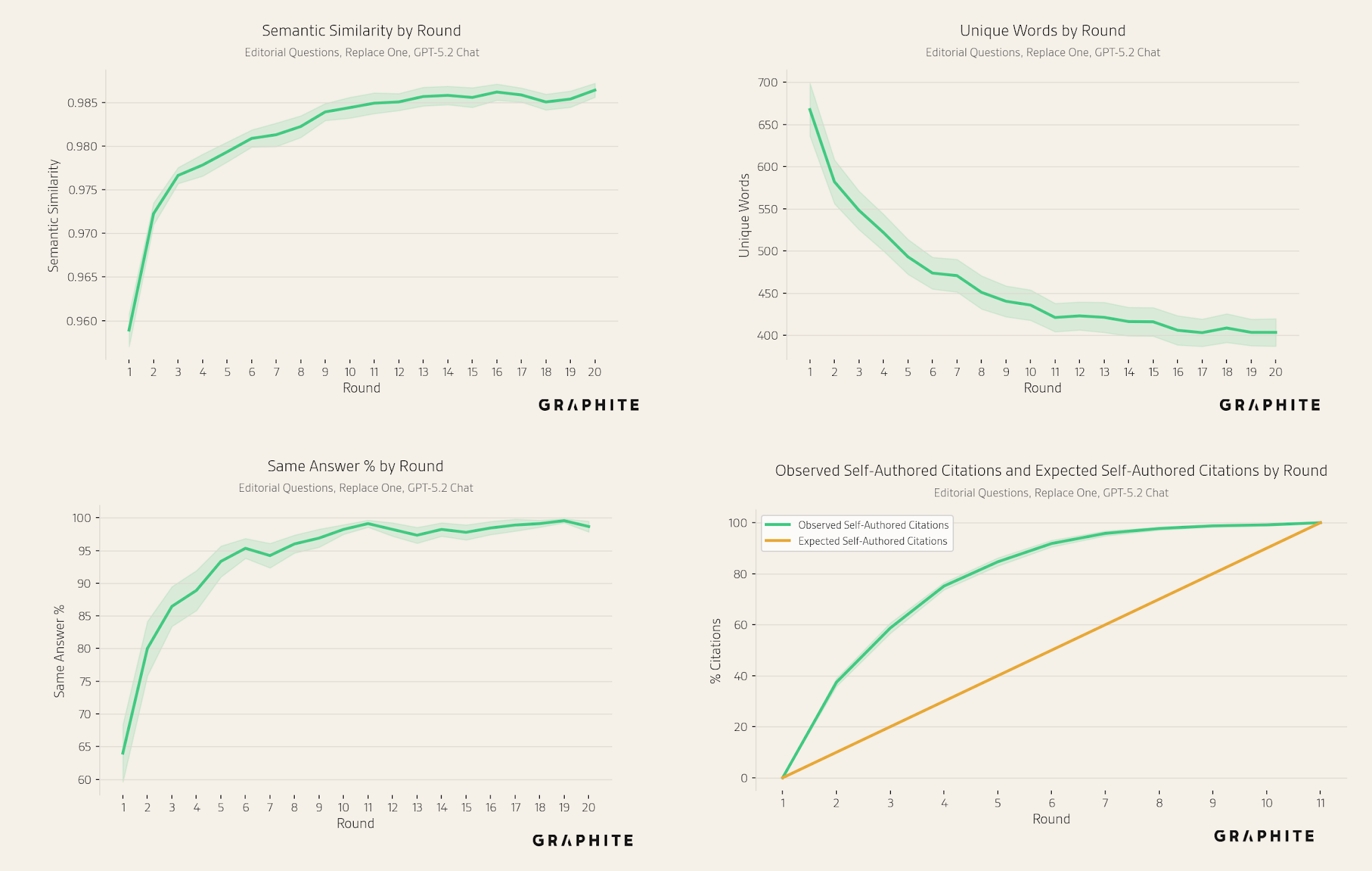
Semantic similarity increases, while the number of unique words decreases, across all simulations.
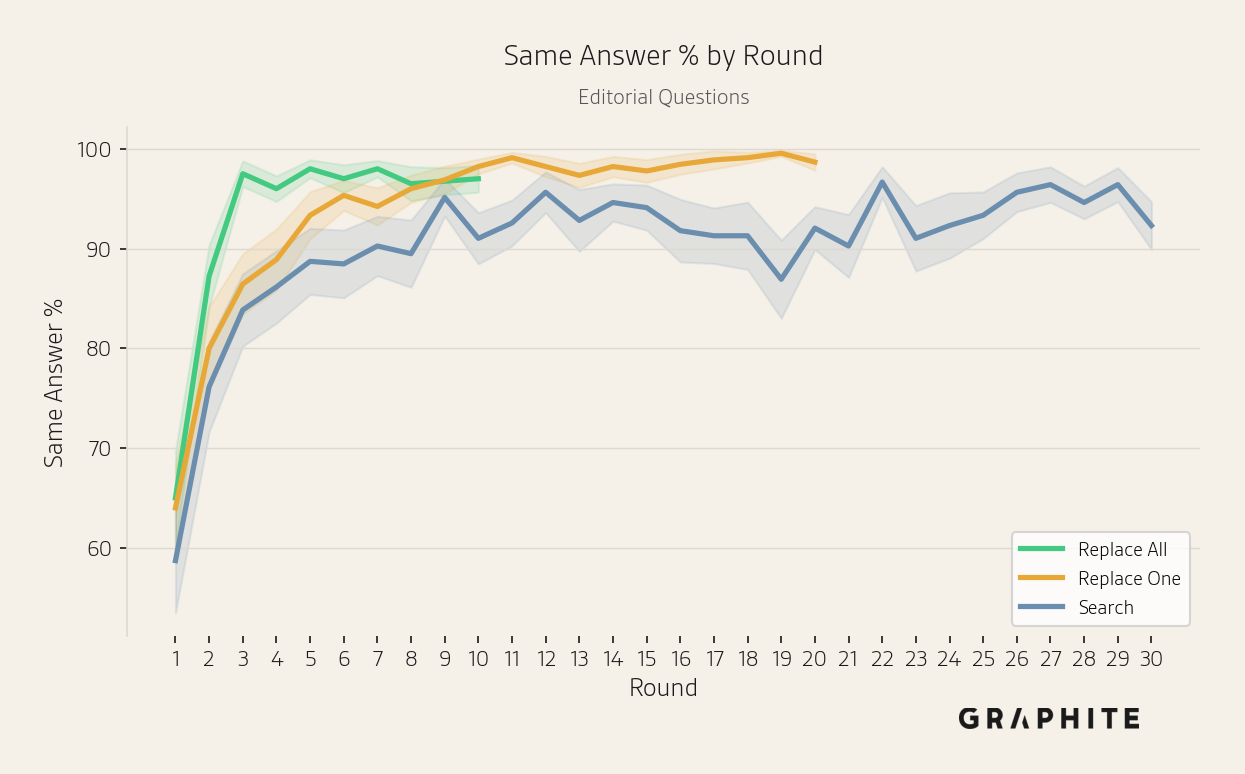
The same answer percentage increases over rounds.
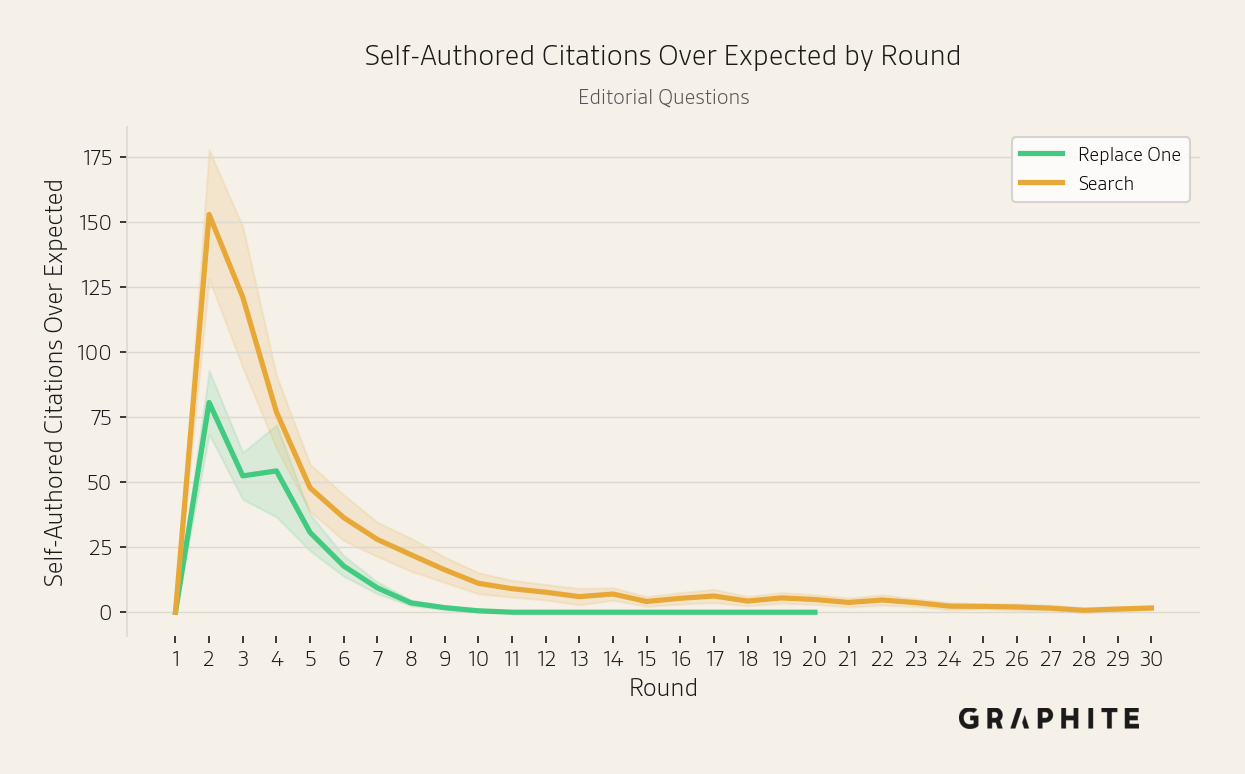
Self-authored references are again disproportionately cited.
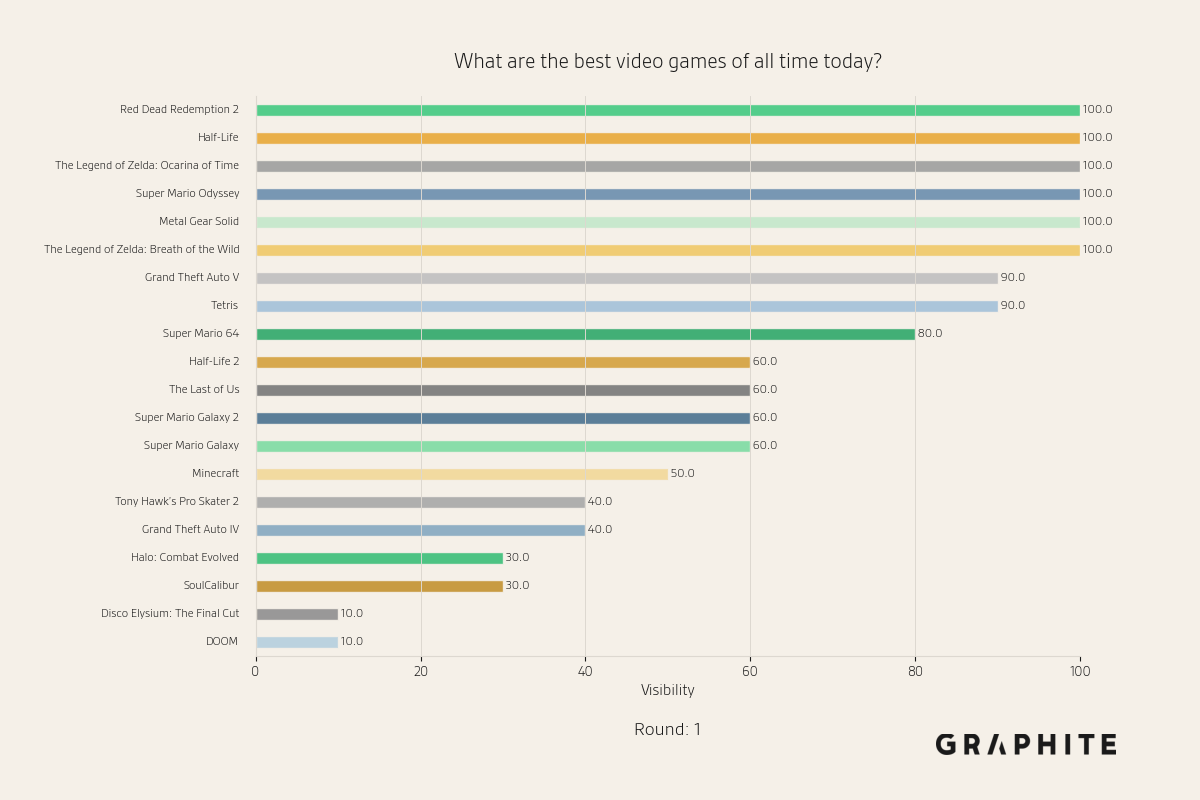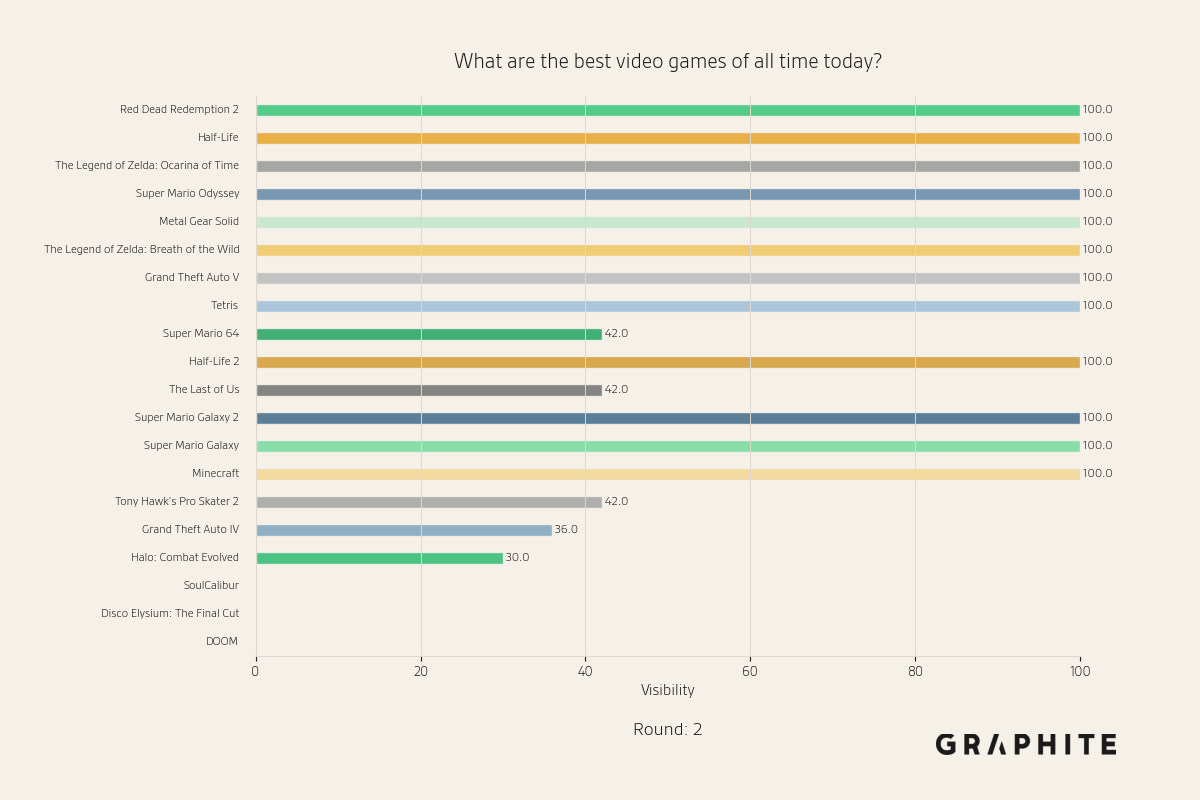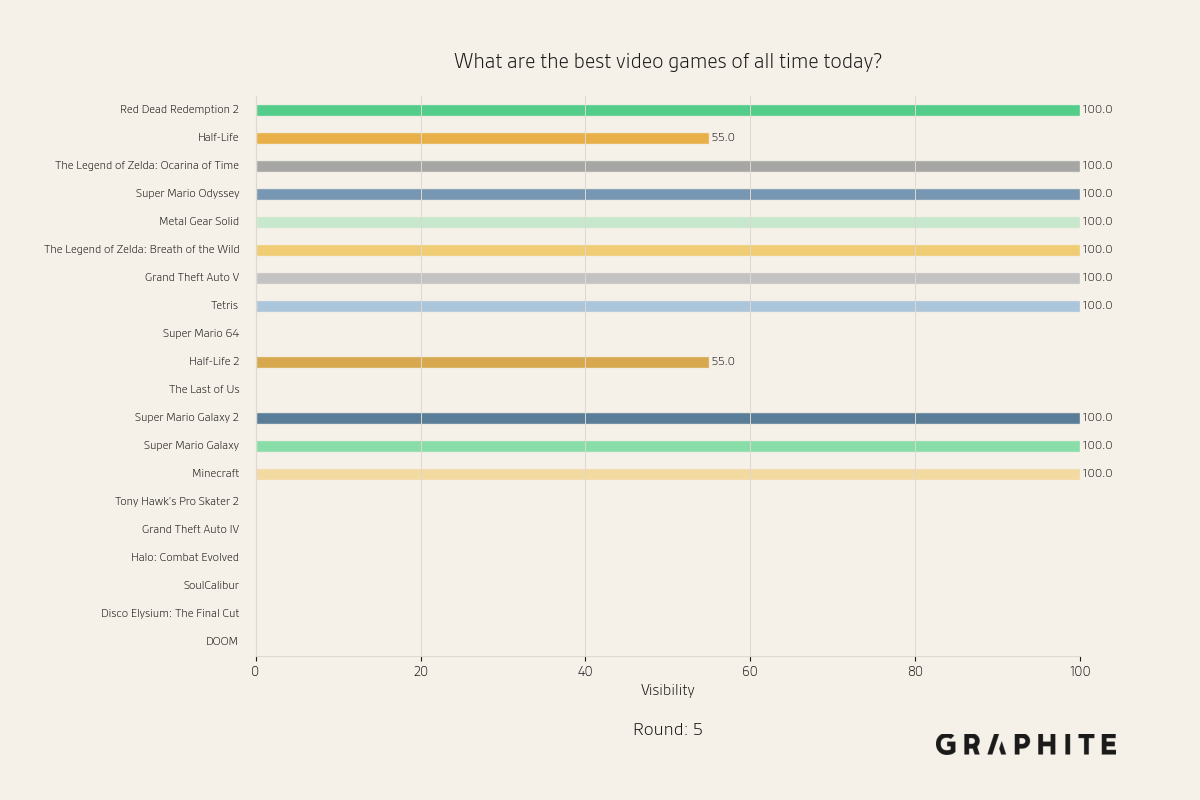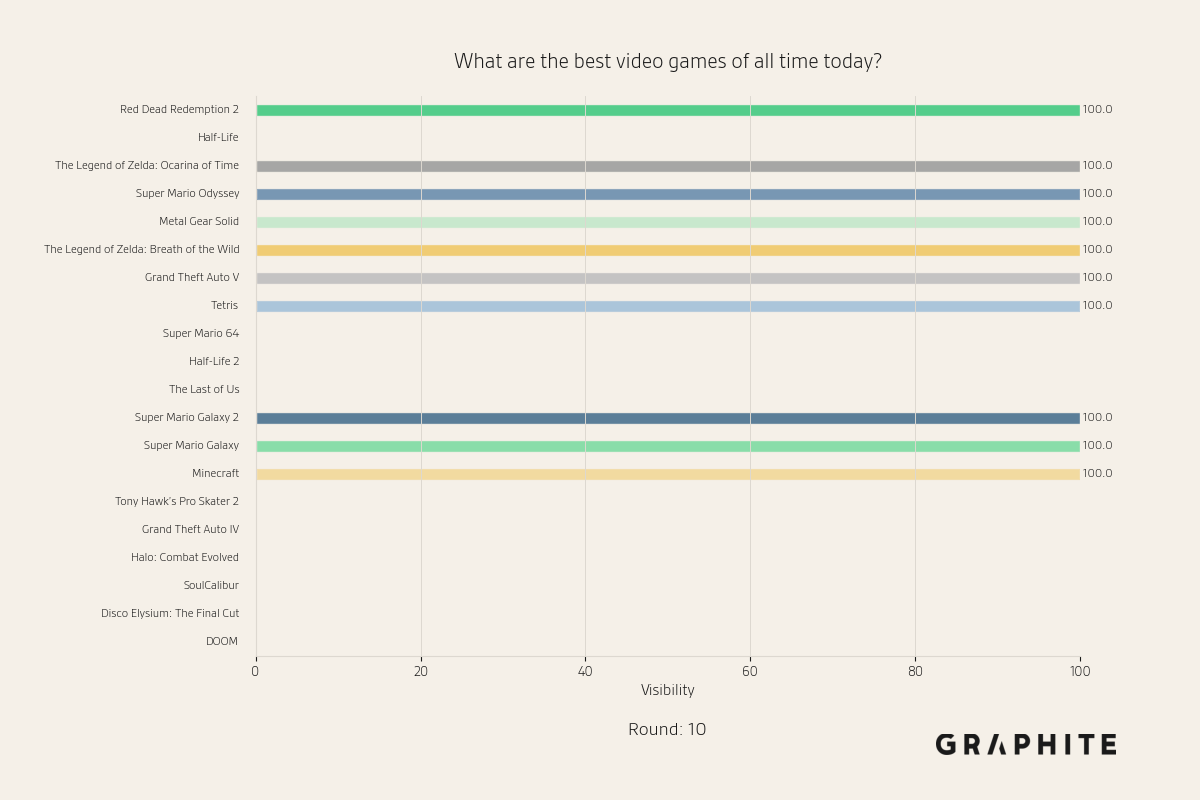
Below are visibility snapshots for entities during the Replace All simulation for the question “What are the best video games of all time today?”
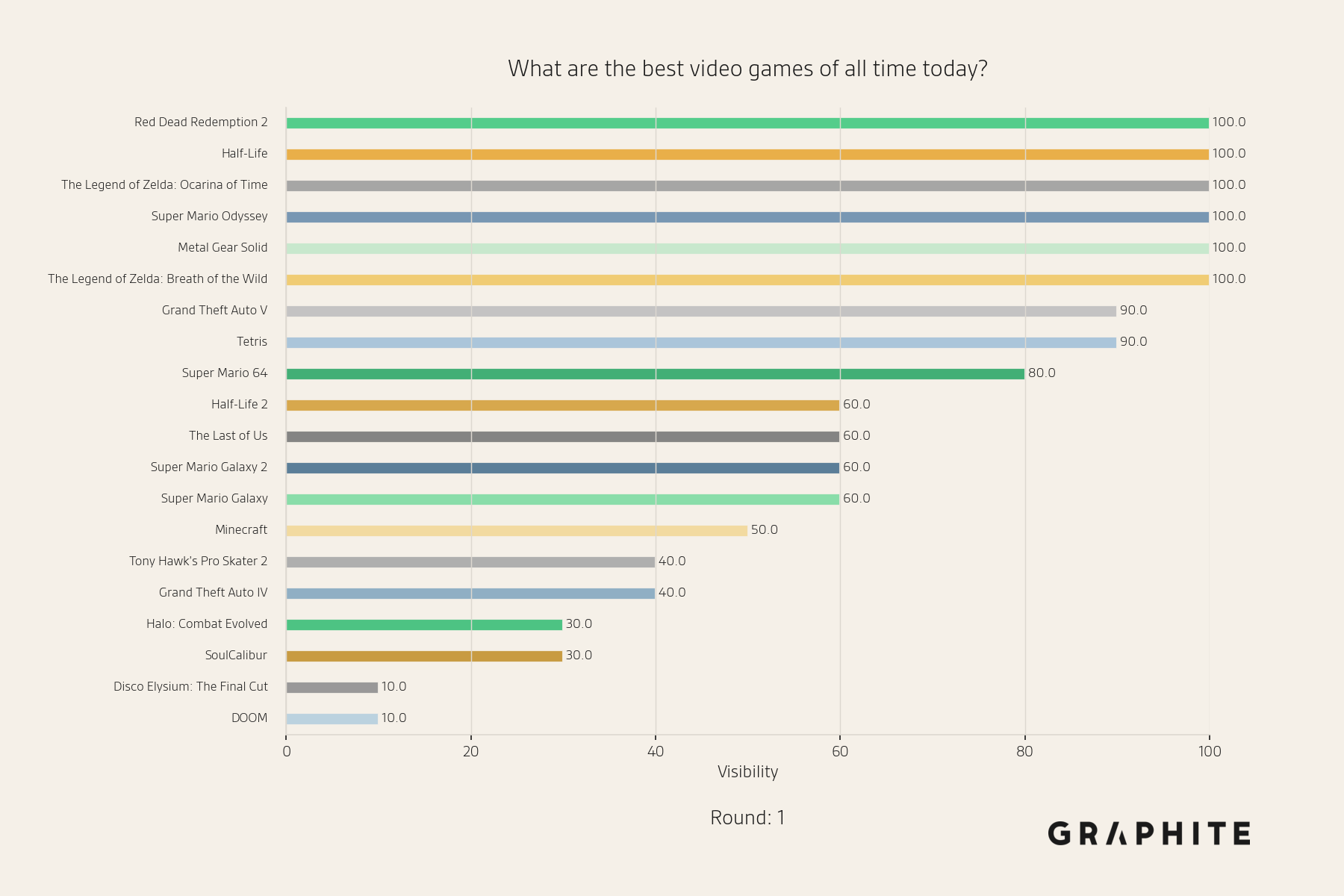
In the first round, in which the original references are used to generate responses, we observe a wide distribution of entities. Some, like Red Dead Redemption 2, are mentioned in 100% of responses (10/10). Others, like DOOM, are mentioned in only 10% of responses (1/10).
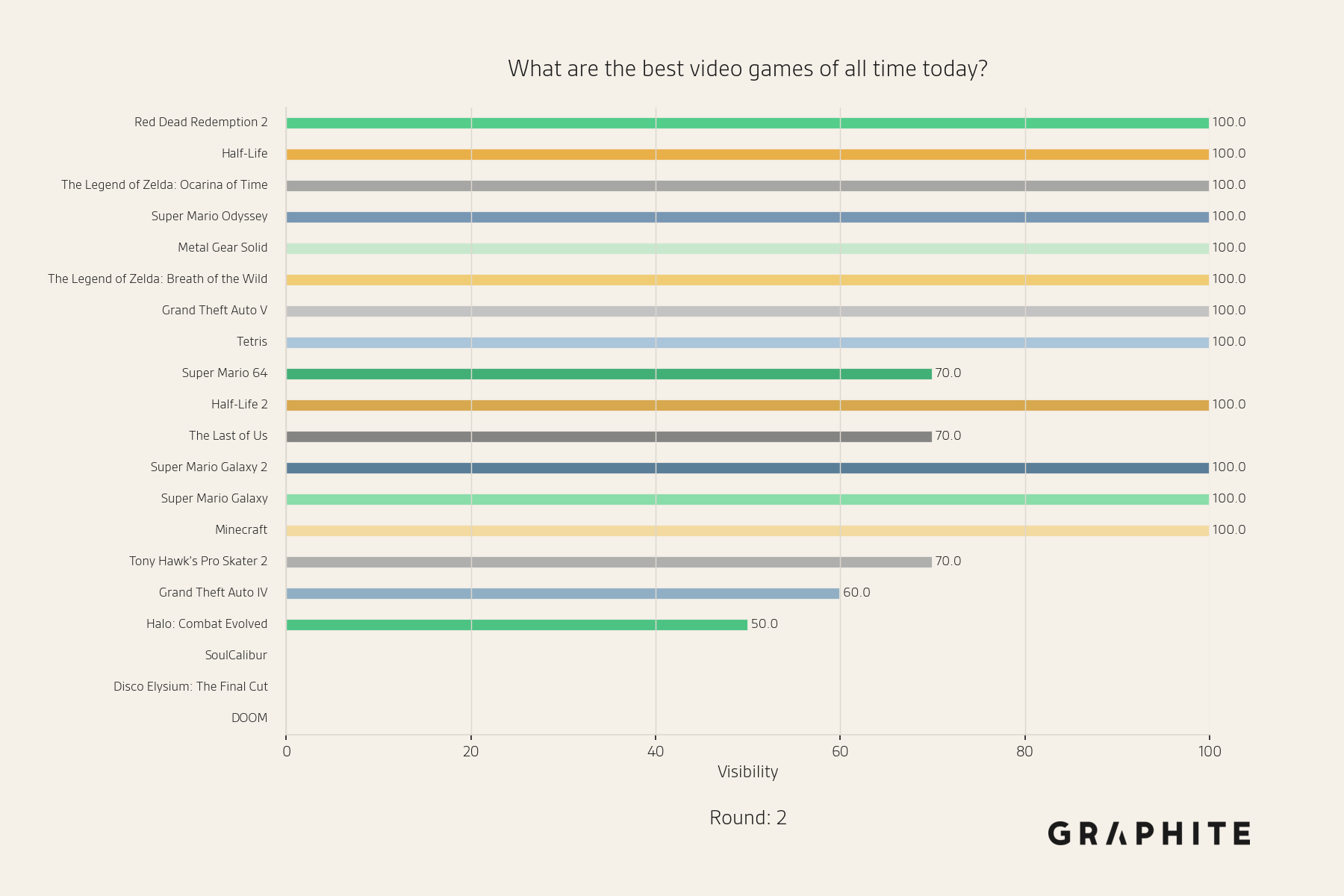
After converting the model’s first-round answers into articles and using them as references, the distribution begins to shift.
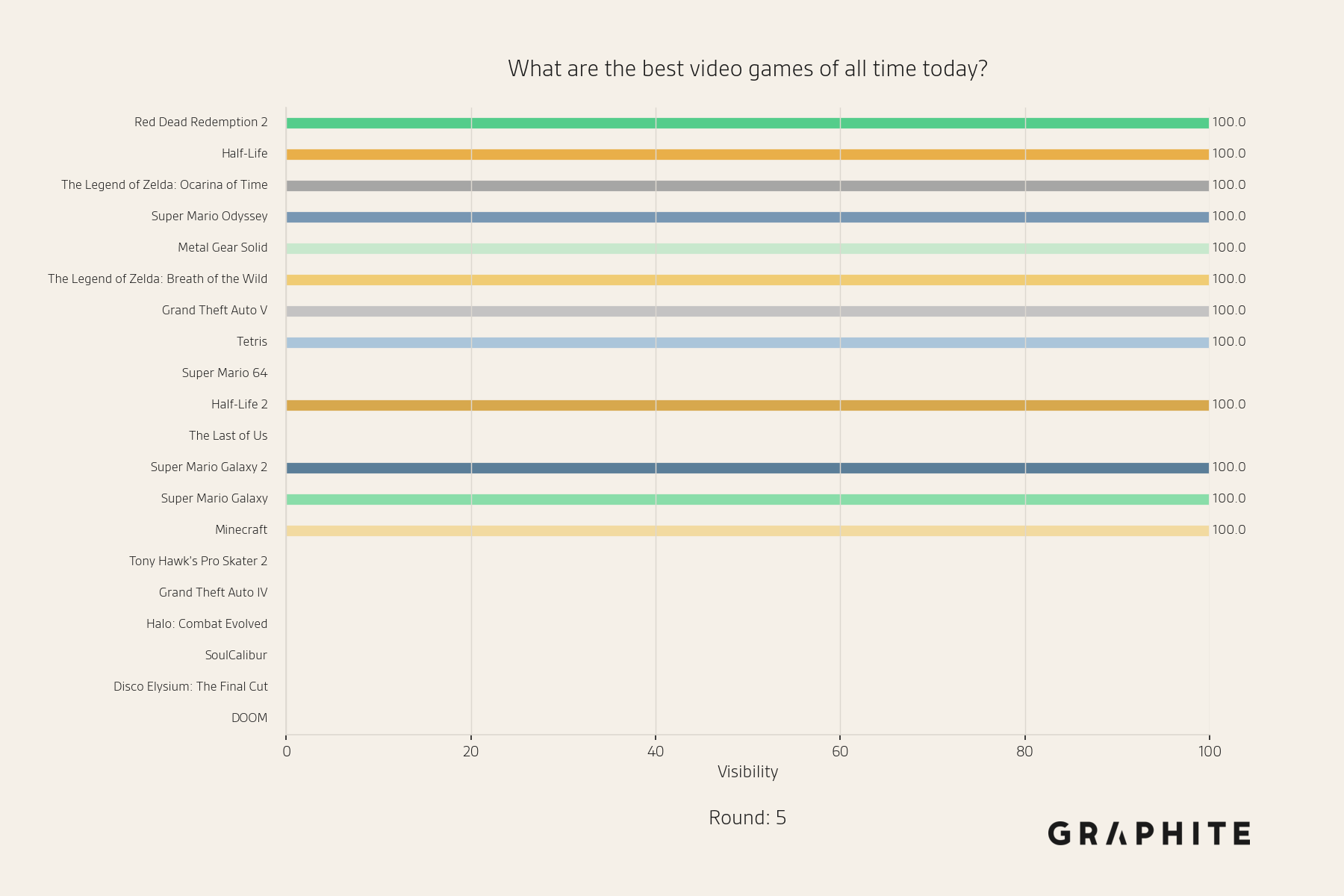
By the fifth round, the distribution is very different; all entities either always appear or never appear.
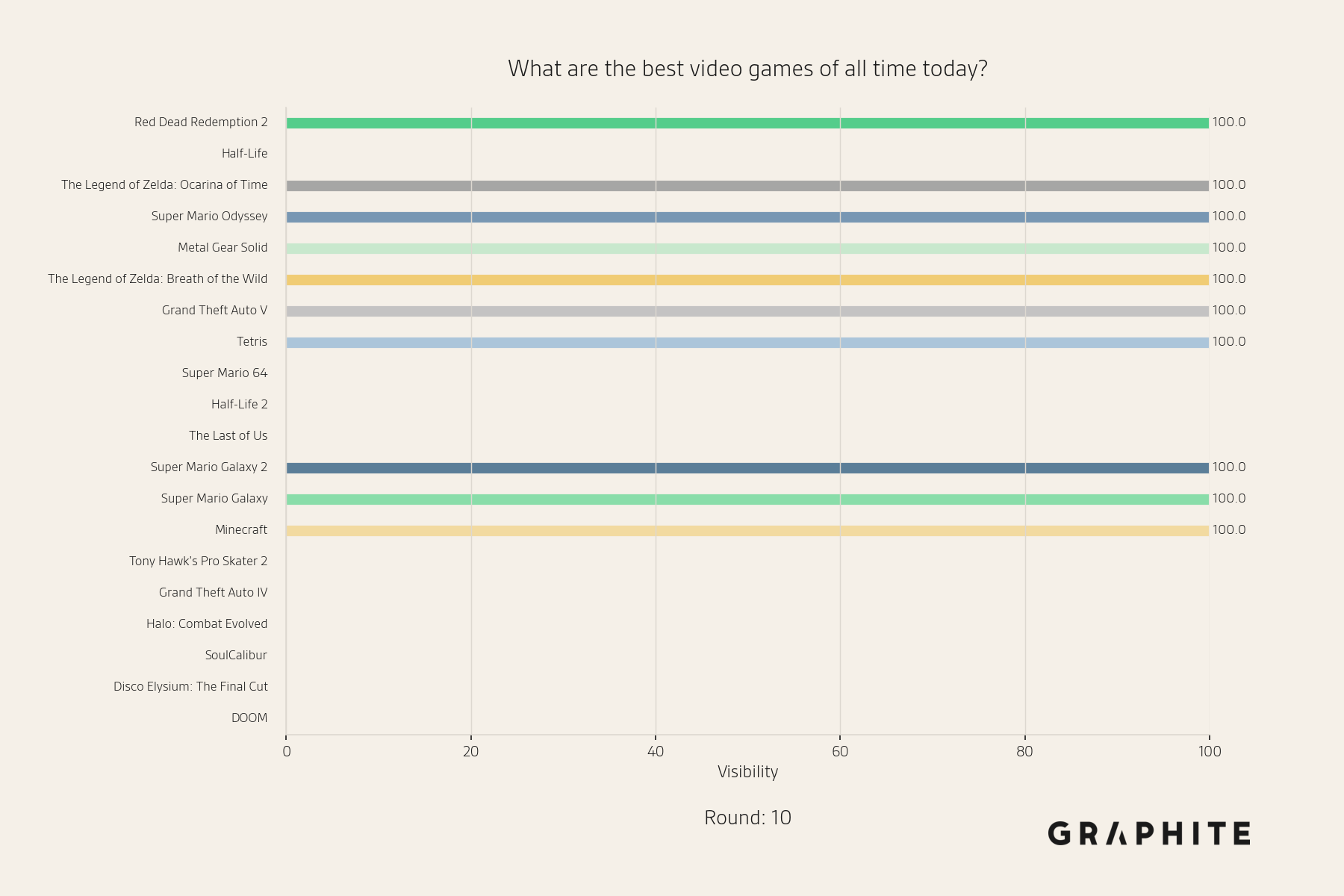
By the tenth round, more entities drop out, including “Half-Life”, which at the beginning of the simulation had 100% visibility. This demonstrates the random nature of AI search collapse.
Next, we examine the actual responses to this question at rounds 1 and 10 (the final round).

Round 1: The first few games are the same, but after that, the answers differ.

Round 10: While the answers have slightly different formatting, the games mentioned are exactly the same, and in the same order, and the text is nearly word-for-word identical.
Similar to model collapse via retraining, at the end of the simulations, responses now differ quite a bit from the original responses. Rather than having a variety of words and entities in different orders, the words are almost the same, and the same set of entities is mentioned in the same order. Some entities with 100% visibility initially drop out completely.
Comparison of Models
Next, we compare the results of the Replace One simulation using different models. To ensure a fair comparison, we restrict to the questions that appear in both the ChatGPT and AI Overview datasets. This yields 41 Entity Questions and 45 Editorial Questions. This means the results here vary from those presented in the Experiment Summary and the Appendix. Note that we use different initial references for GPT-5.2 Chat (from the ChatGPT UI) and Gemini 3 Pro and Claude Sonnet 4.5 (from Google AI Overviews), because we wanted to pair each model with references it would actually use. However, this means there may be differences in the quality of references.
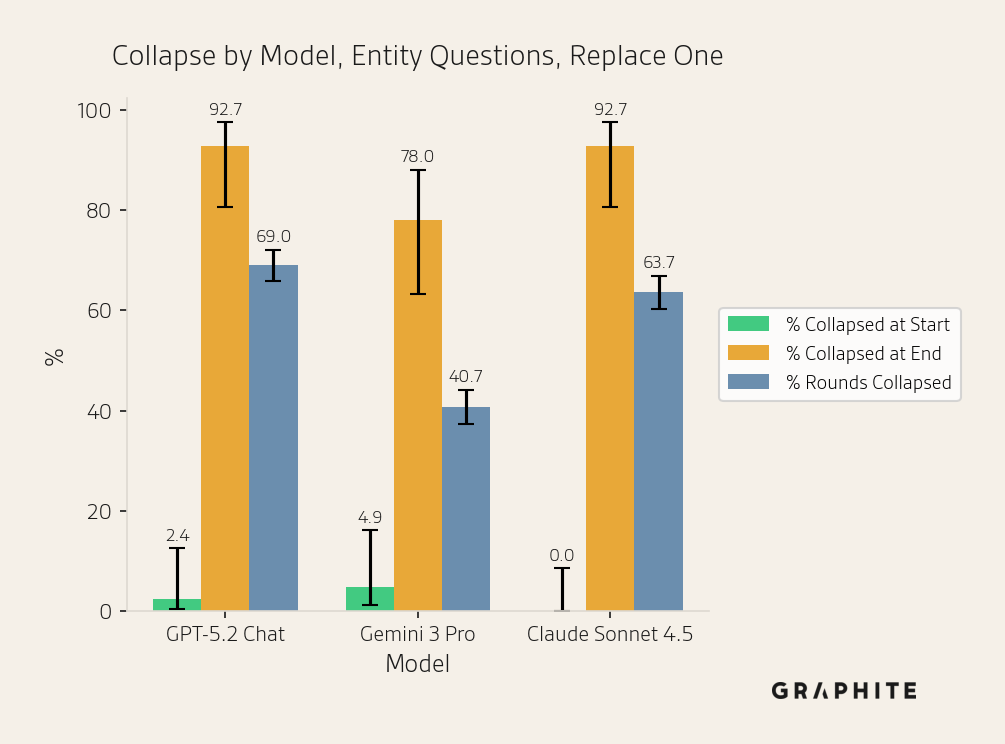
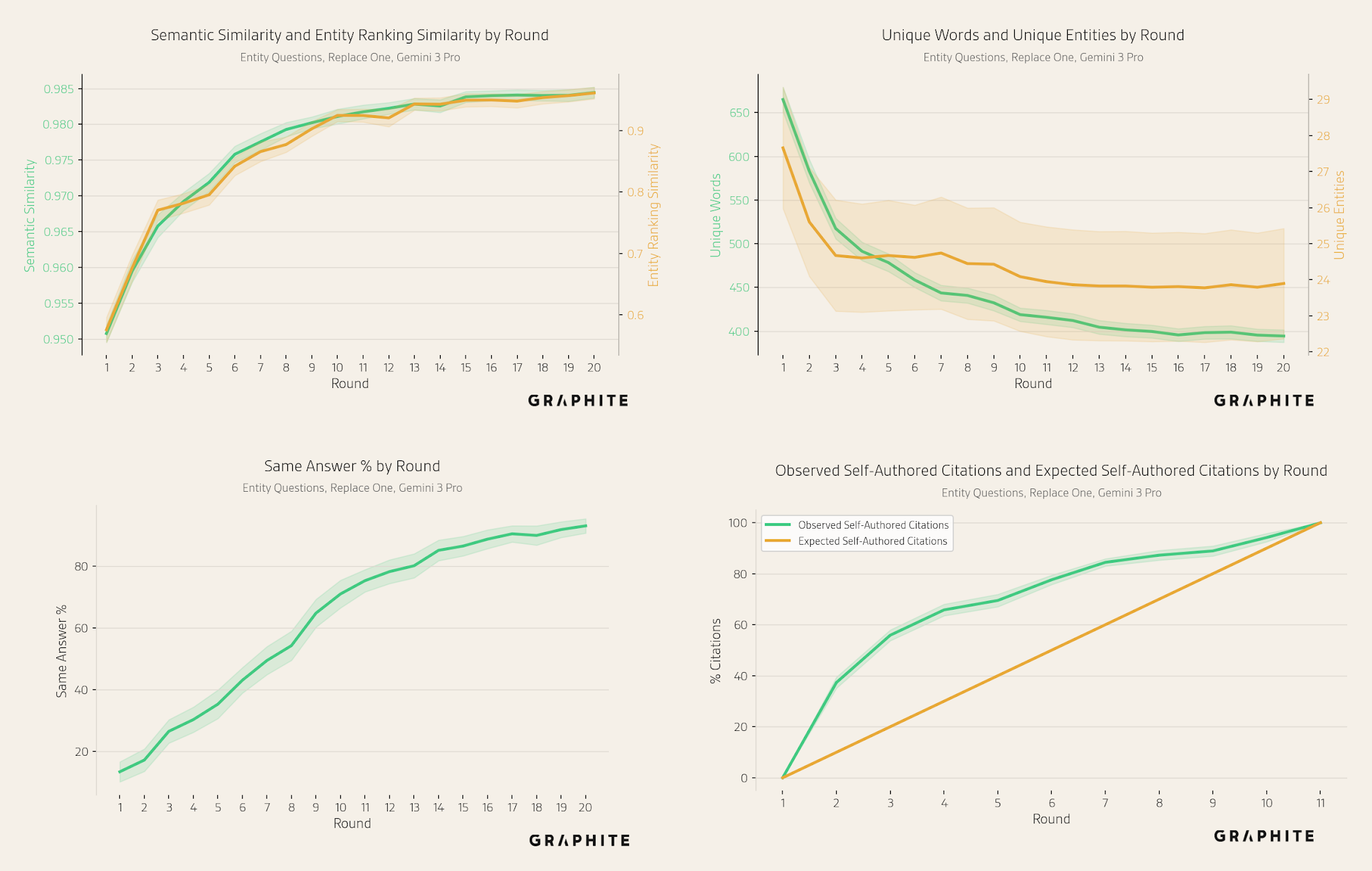
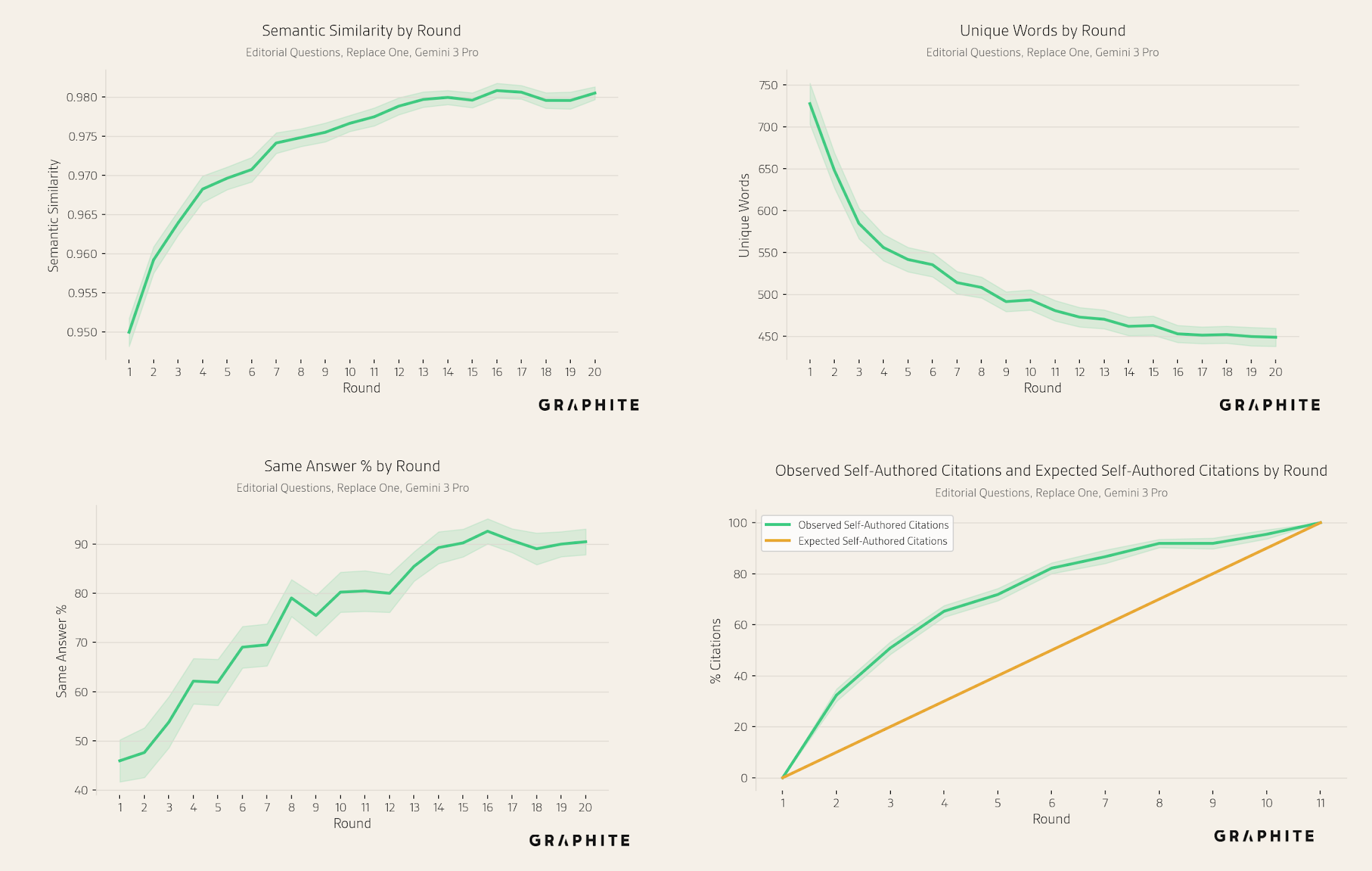
Overall, we observe collapse with all three models, demonstrating that AI search collapse is not specific to OpenAI models. Gemini 3 Pro has lower collapse rates (though in most cases with overlapping confidence intervals) and a smaller drop in unique entities per round.
We next review the individual metrics.
Entity Questions
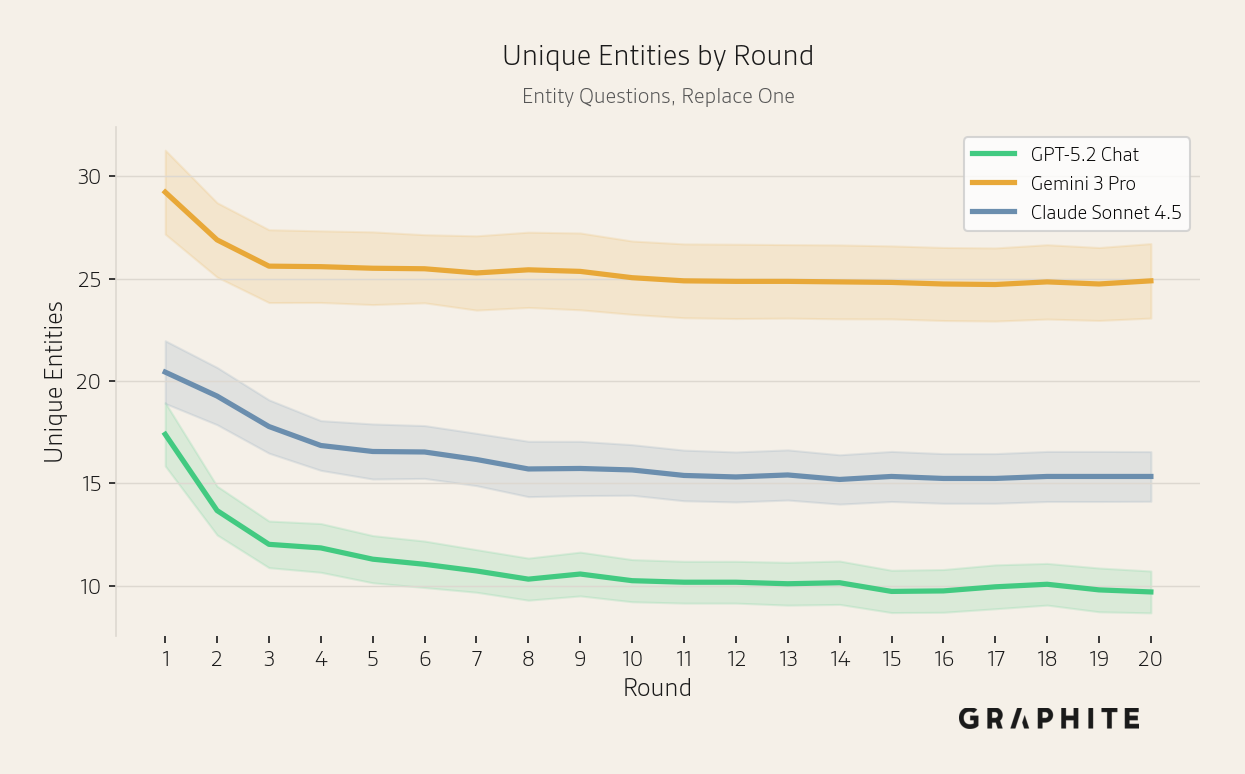
Notice that the three models return very different numbers of entities. Claude and Gemini tend to be more comprehensive than GPT-5.2 Chat, including more entities. However, the mean number of unique entities per round decreases with all models.
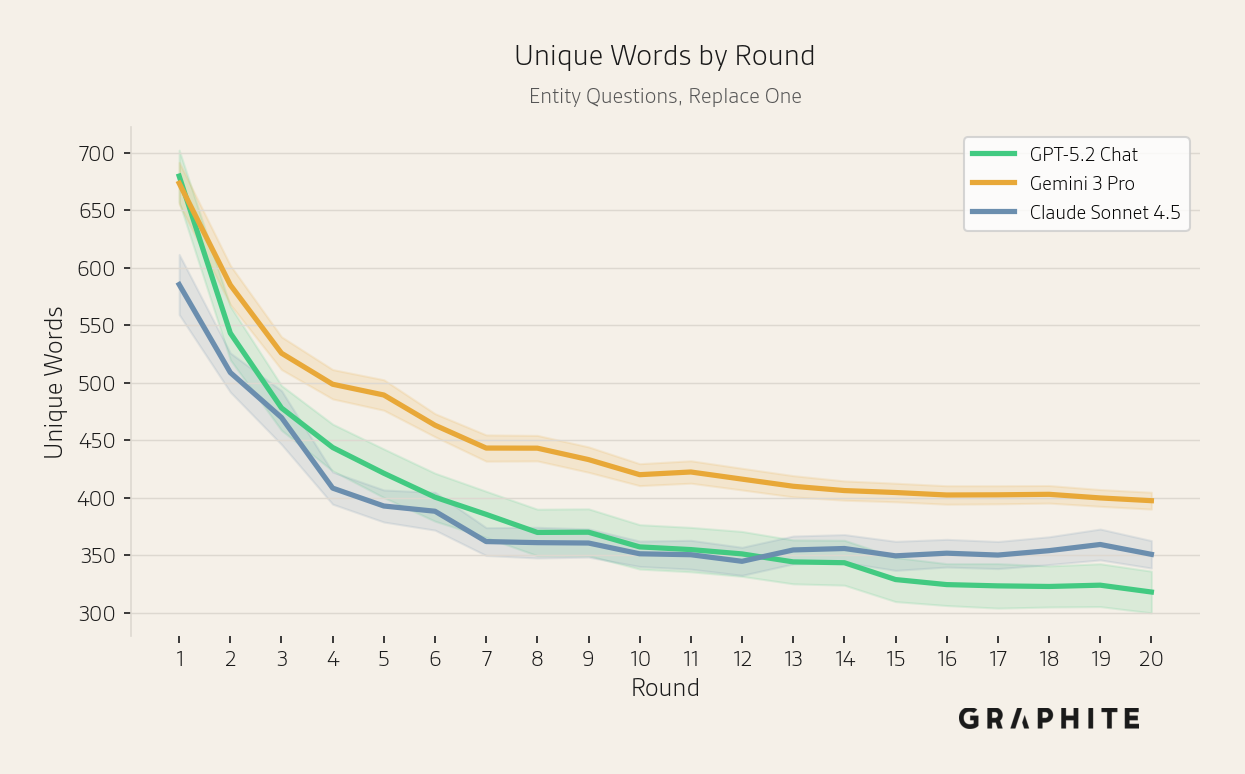
The mean number of unique words per round also decreases with all models.
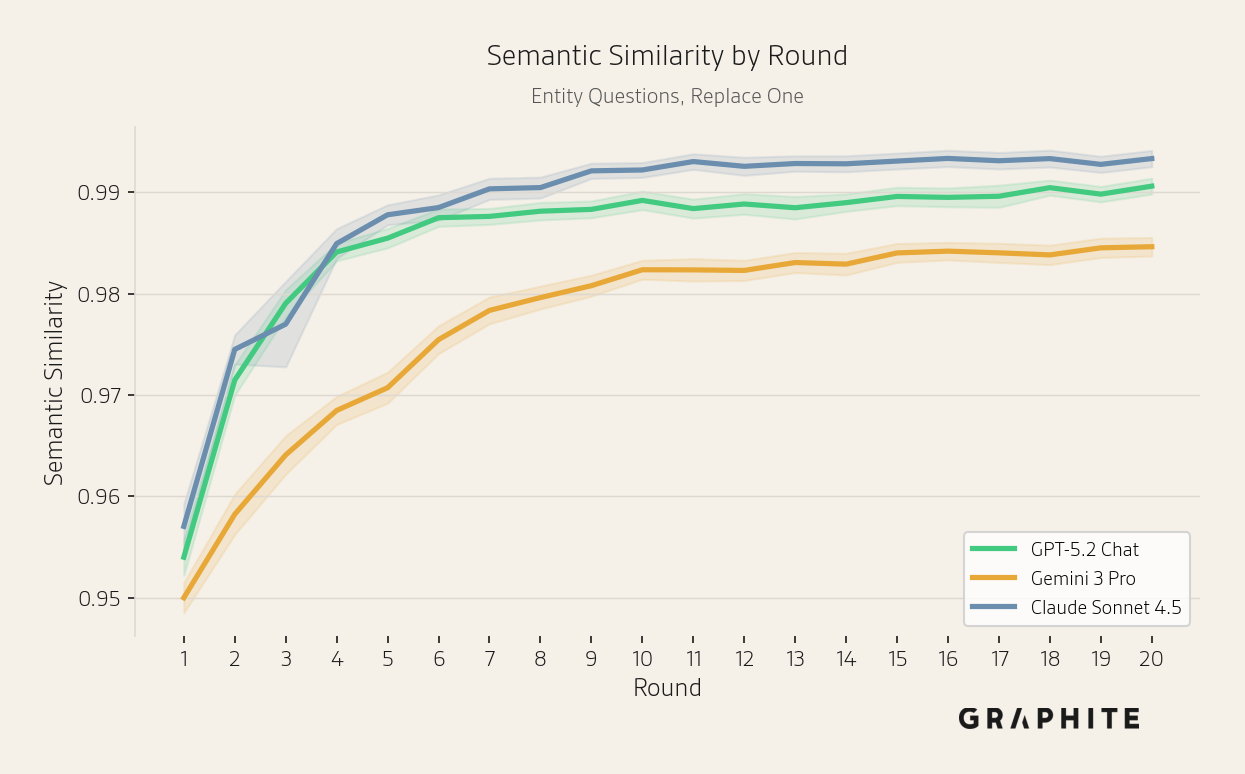
The mean semantic similarity of the responses increases for all models, though more slowly for Gemini 3 Pro.
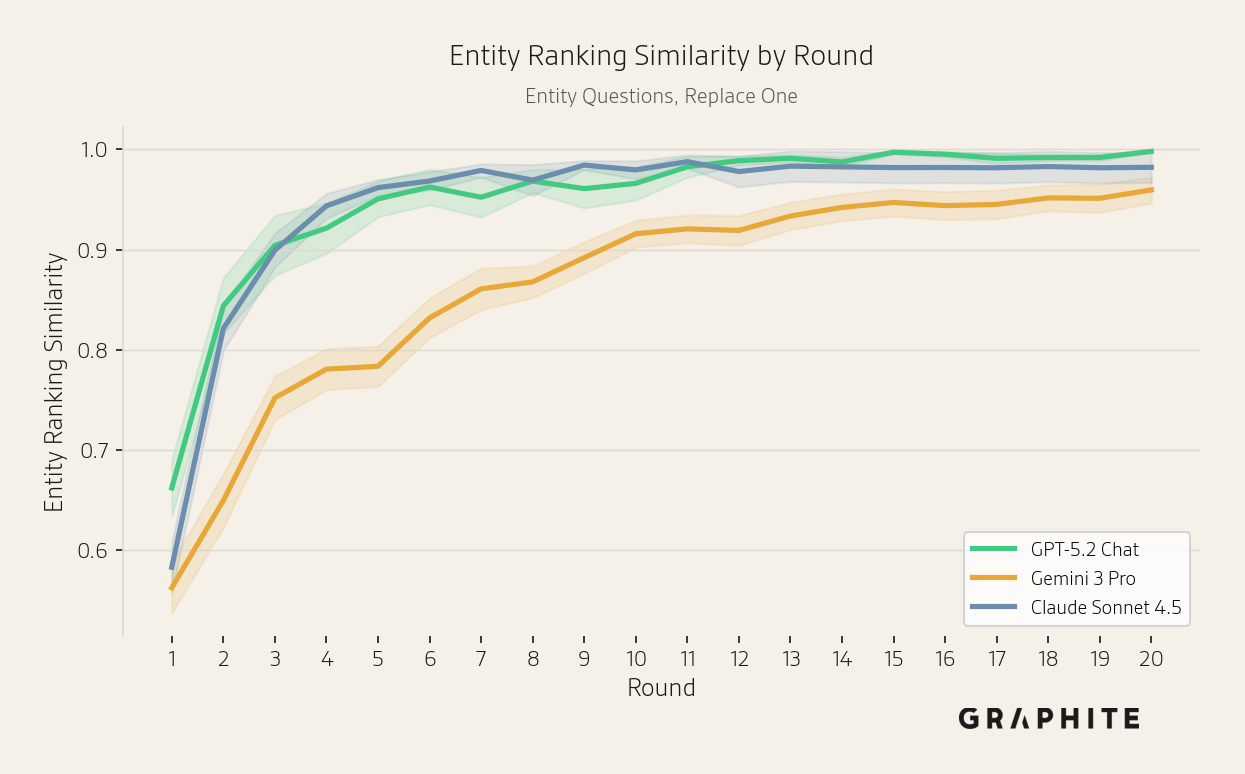
The entity ranking similarity of the responses increases at a similar rate across all models.
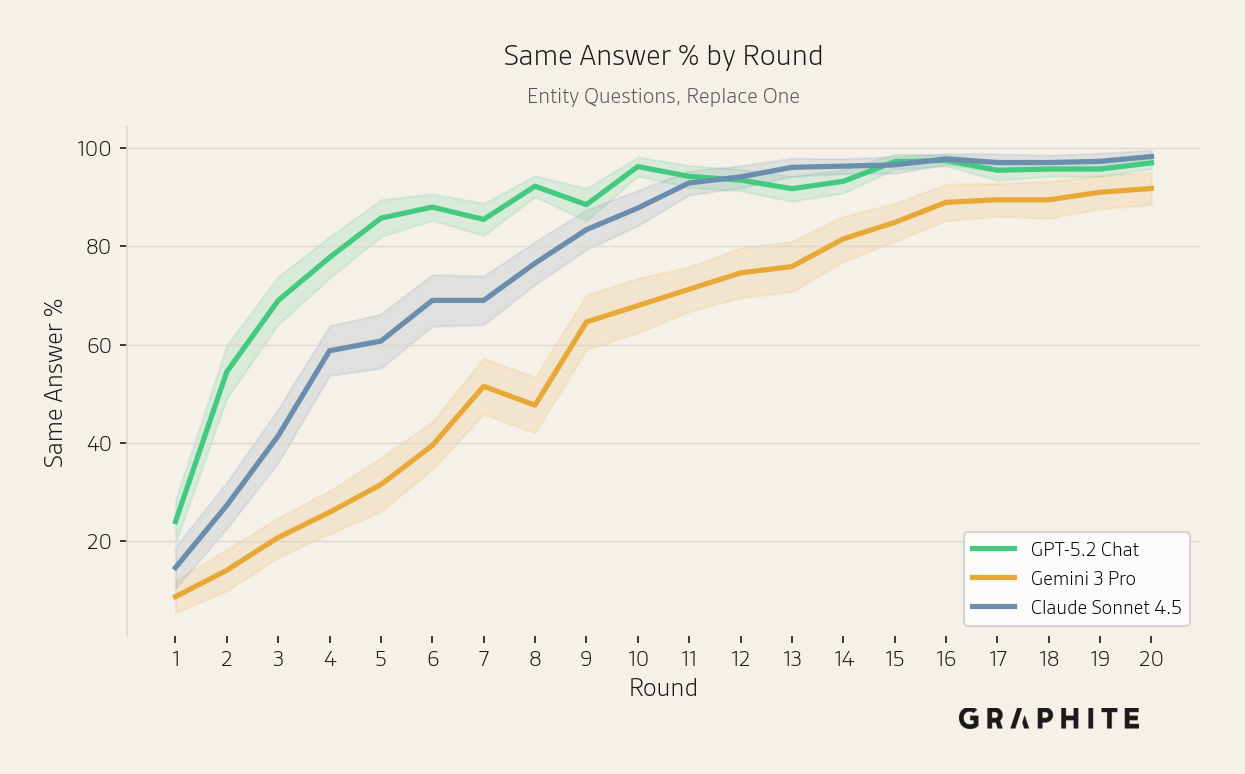
The same answer percentages also increase over the course of the simulation, though more slowly for Gemini 3 Pro and Claude Sonnet 4.5.
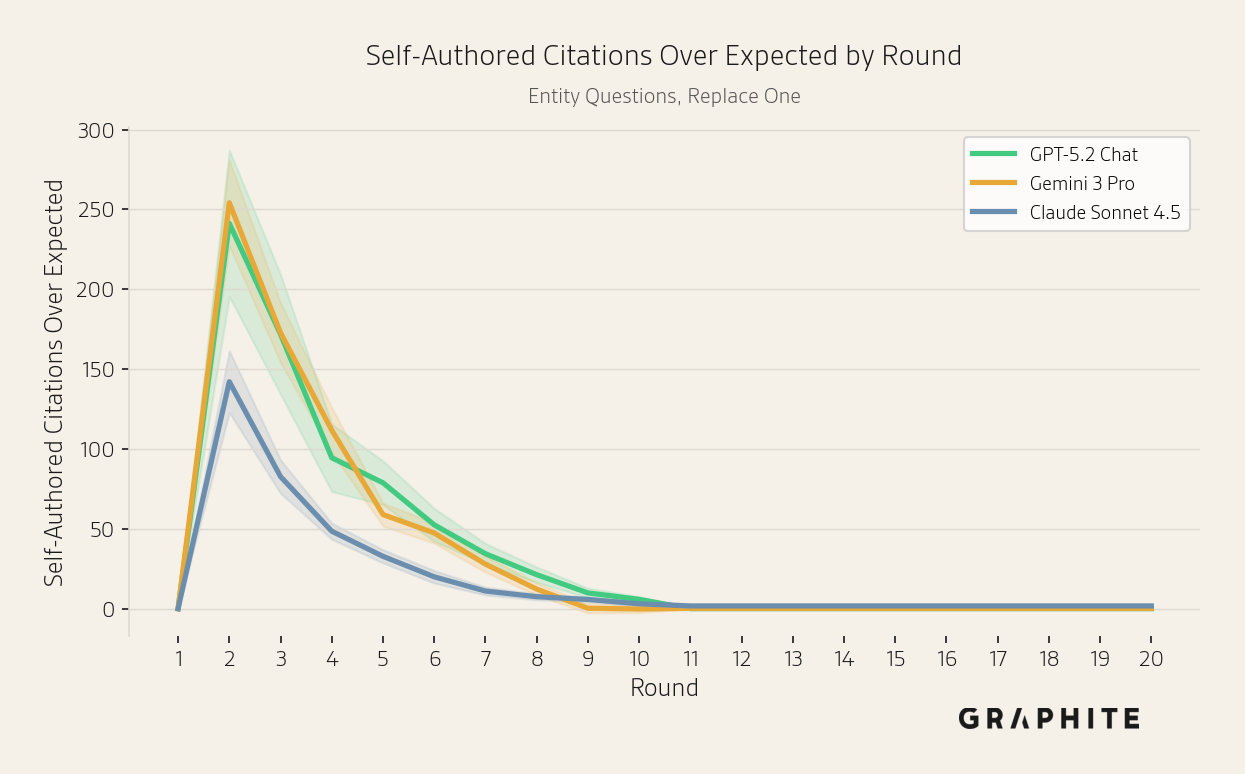
Self-authored references are disproportionately cited by all models.
Editorial Questions
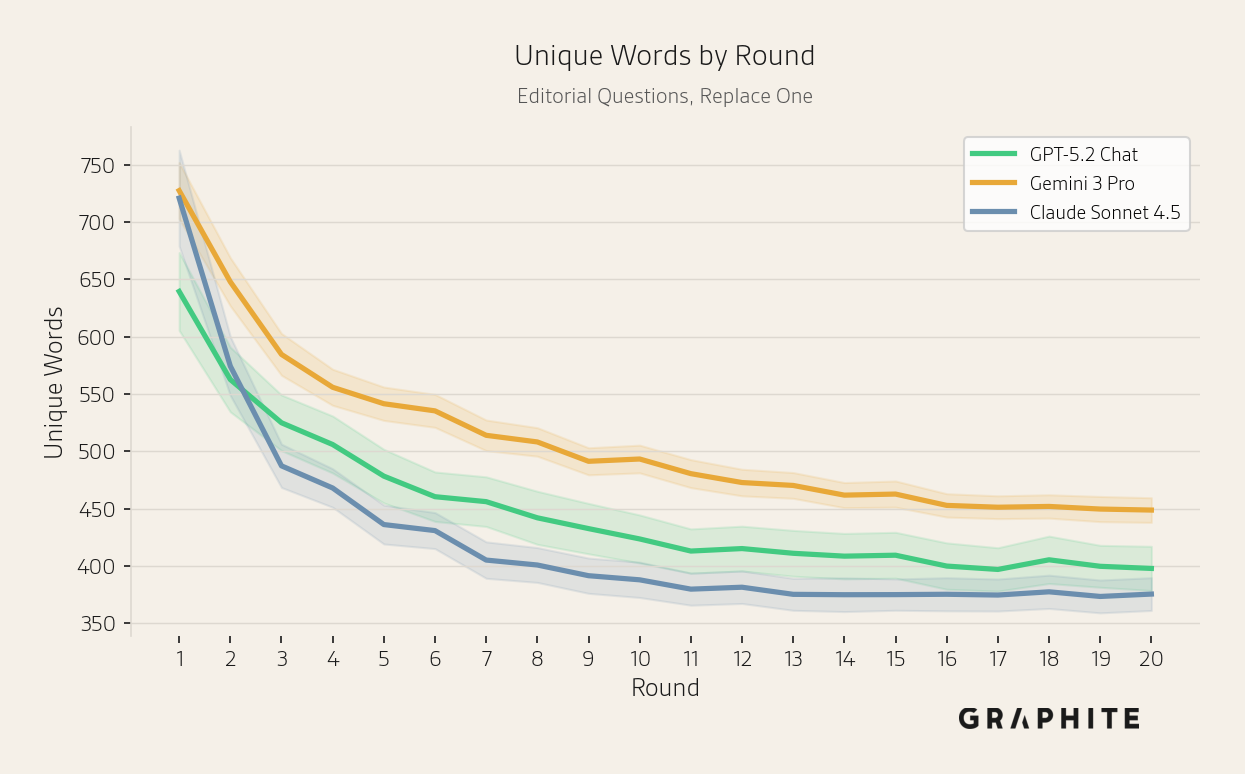
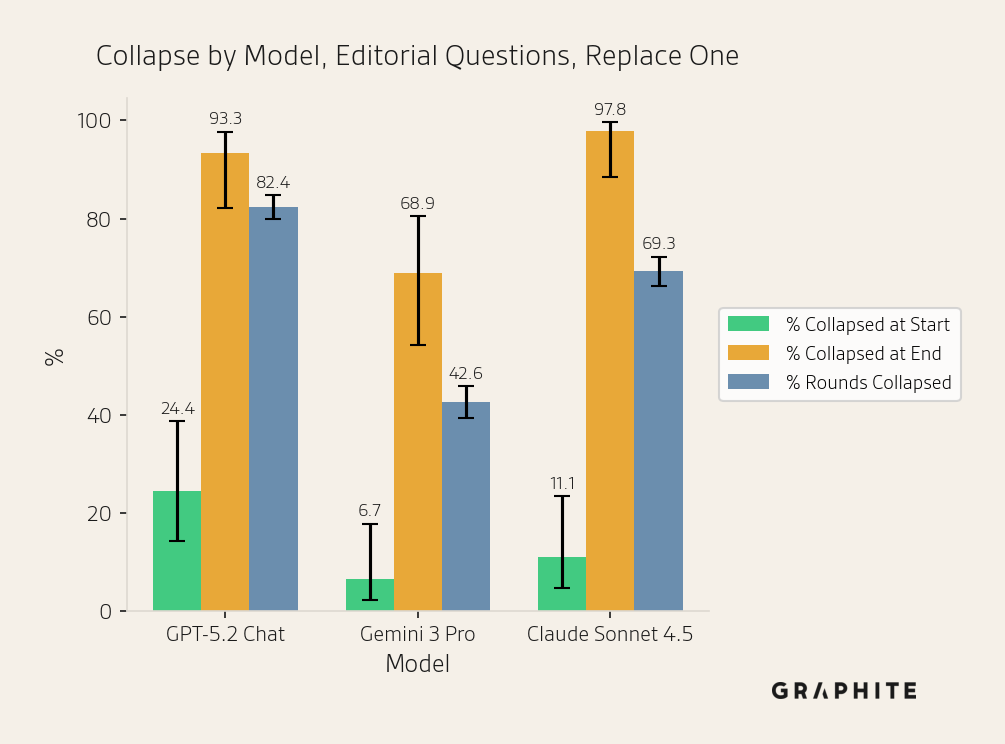
For Editorial Questions, similarly, the number of unique words decreases with all models.
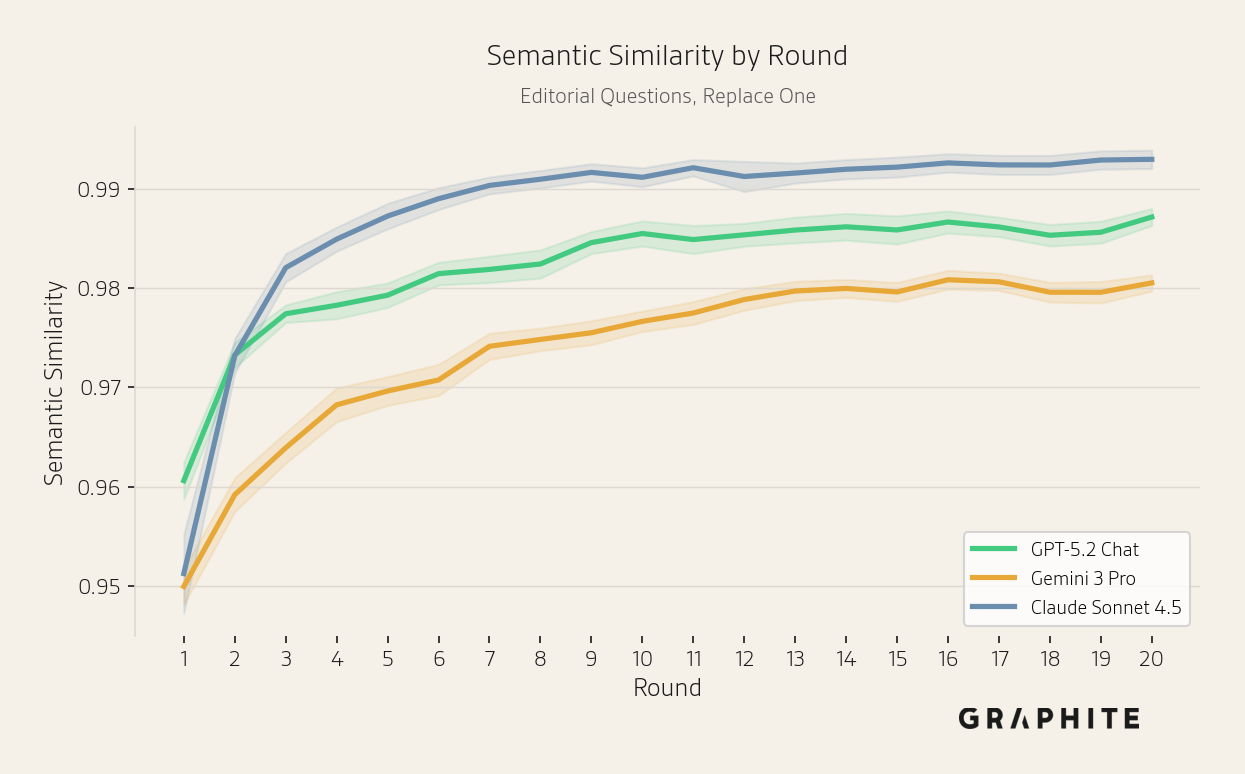
The semantic similarities increase with all models, though more slowly for Gemini 3 Pro.
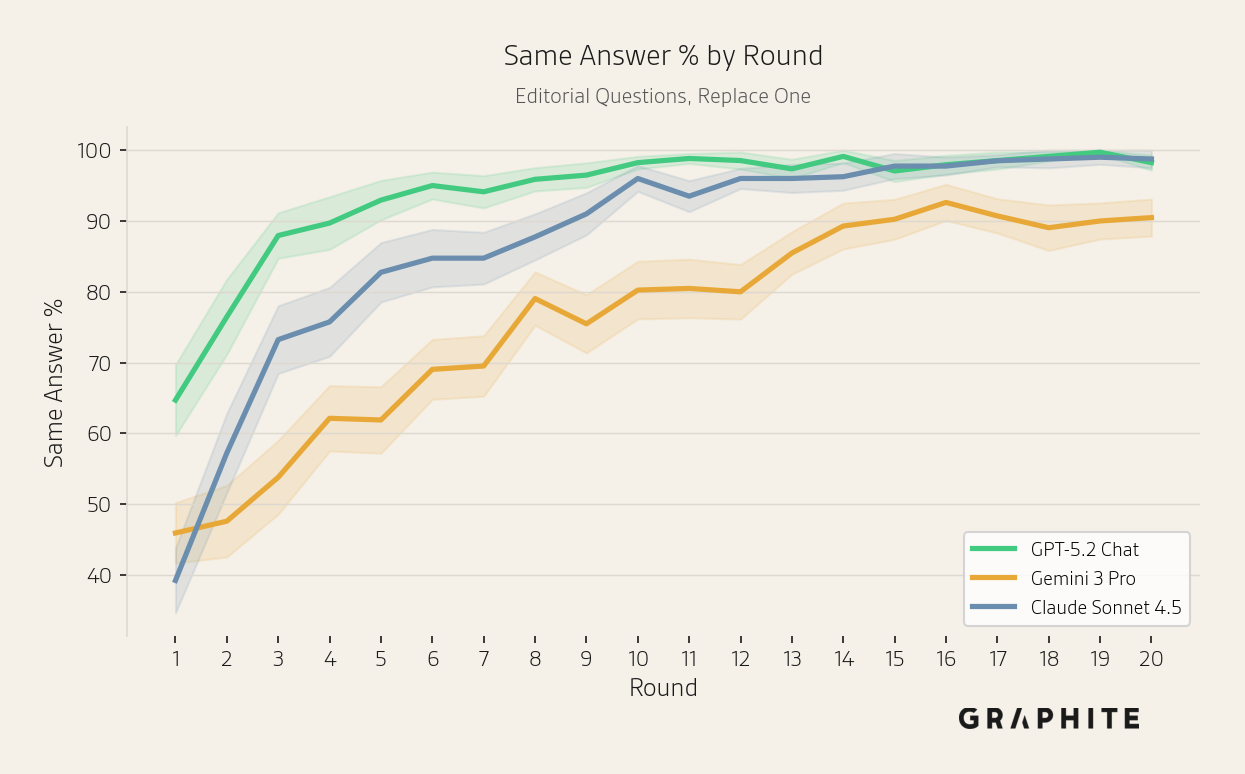
The same answer percentages also increase over the course of the simulation, though more slowly for Gemini 3 Pro.
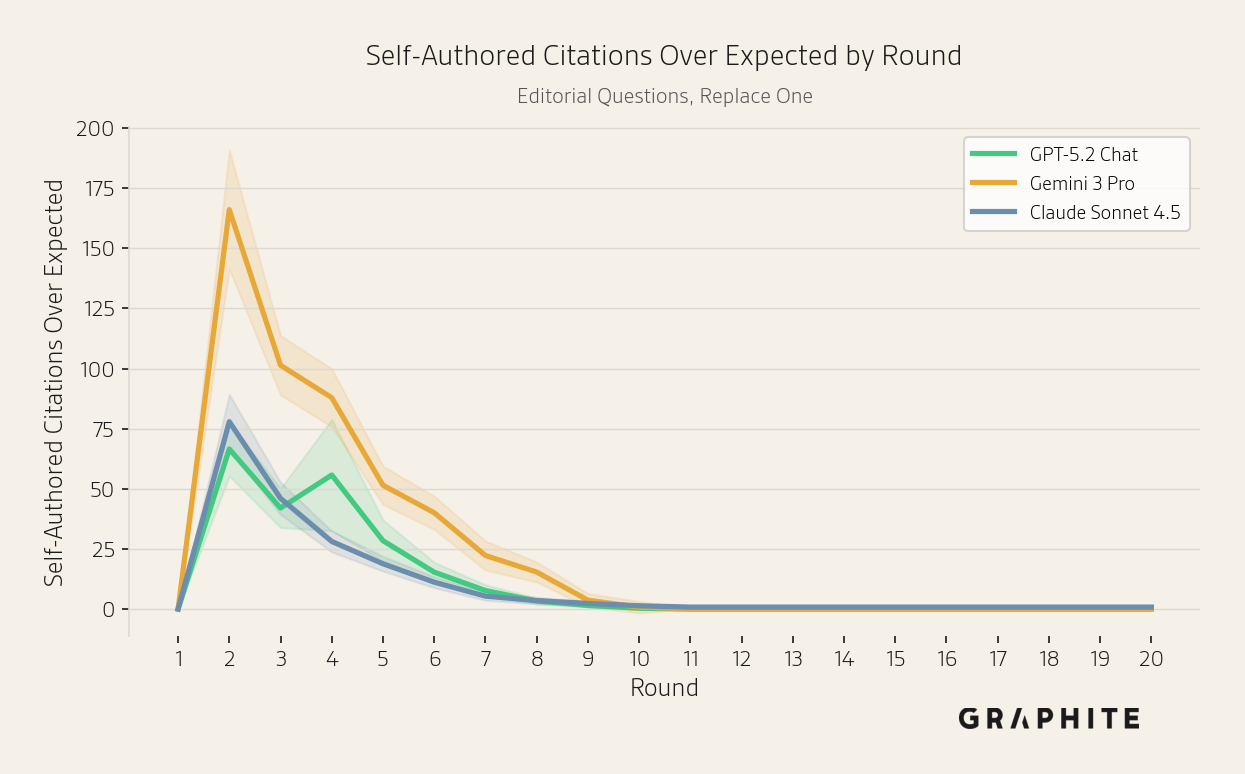
Self-authored references are disproportionately cited by all models.
Larger-Scale Experiments
Finally, we conduct larger-scale experiments with the Search simulation using GPT-5.2 to ensure that our results generalize to many questions. Note that these experiments use GPT-5.2 rather than GPT-5.2 Chat, but the two model variants give similar results.
We run the search simulation on 742 additional Entity Questions that we did not include in the experiments thus far. The results are consistent with the experiments presented previously.

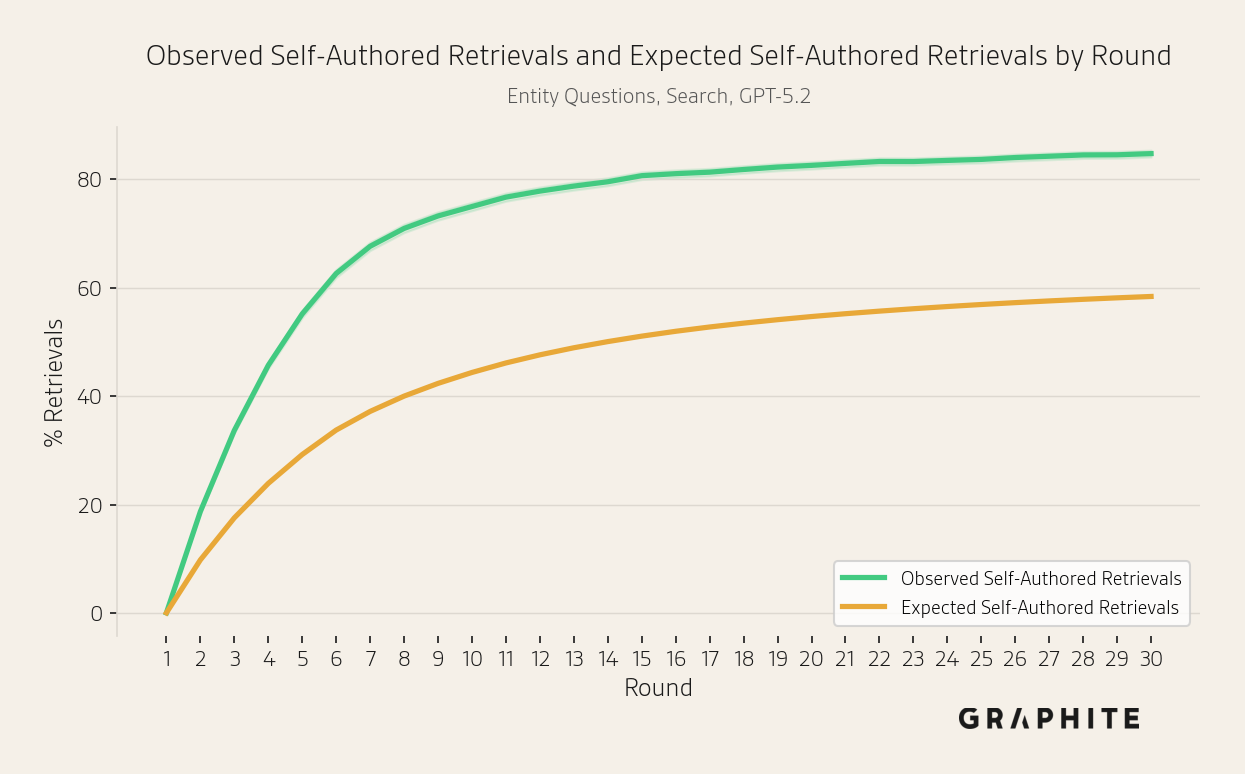
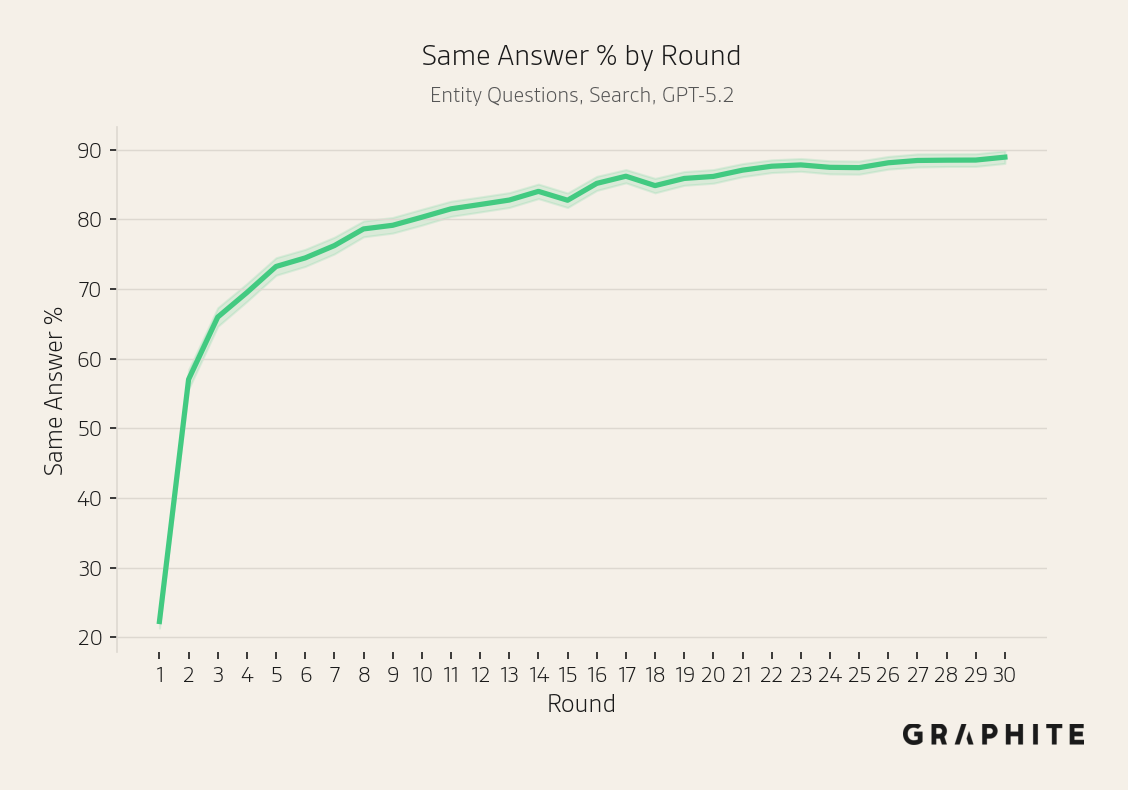
We also run simulations for the 102 additional Editorial Questions. Again, the results are consistent with the experiments presented previously.
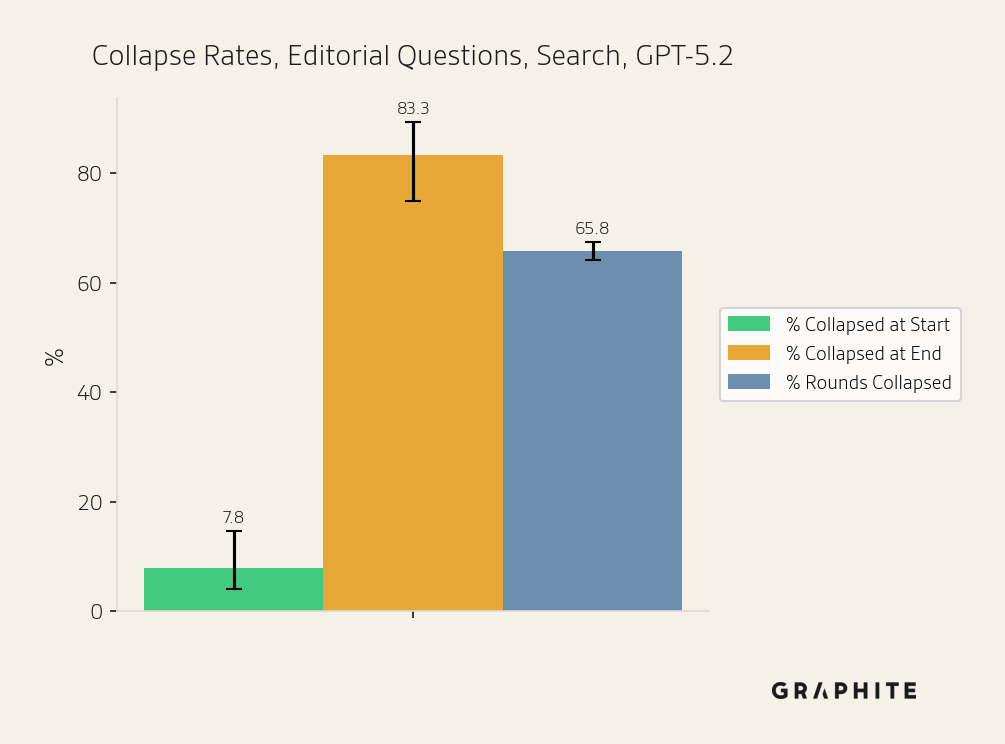
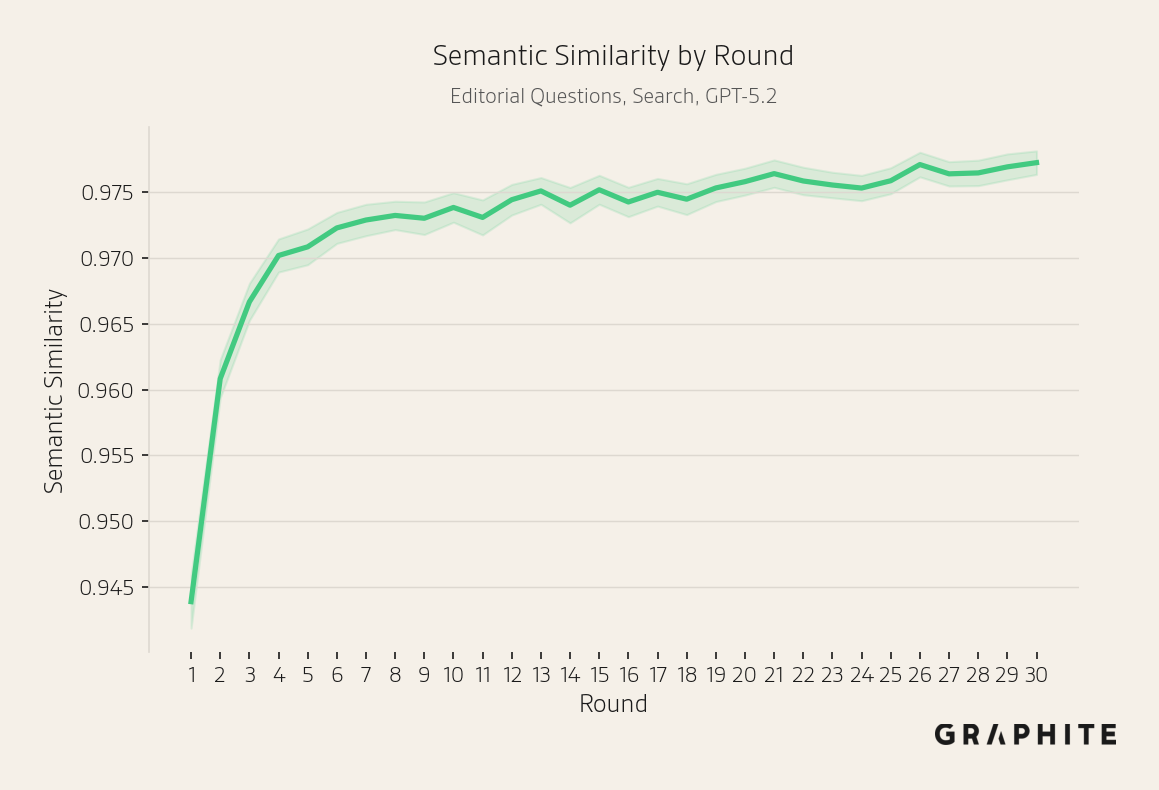
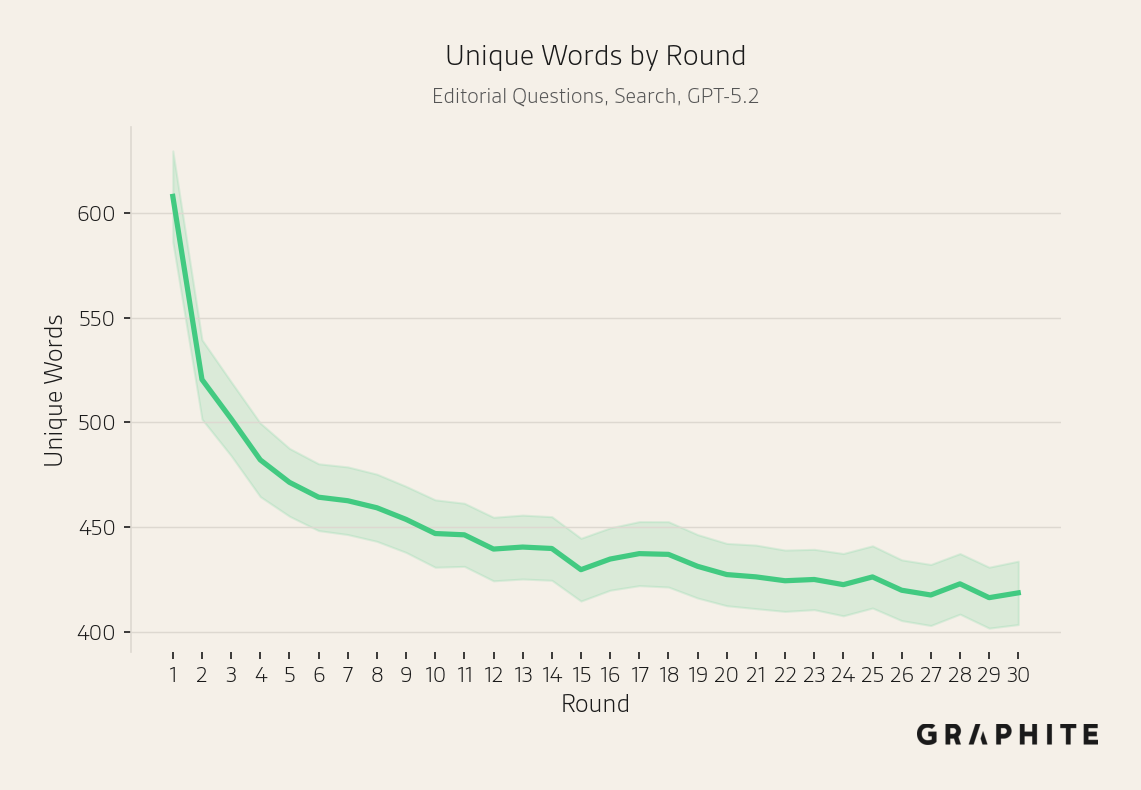
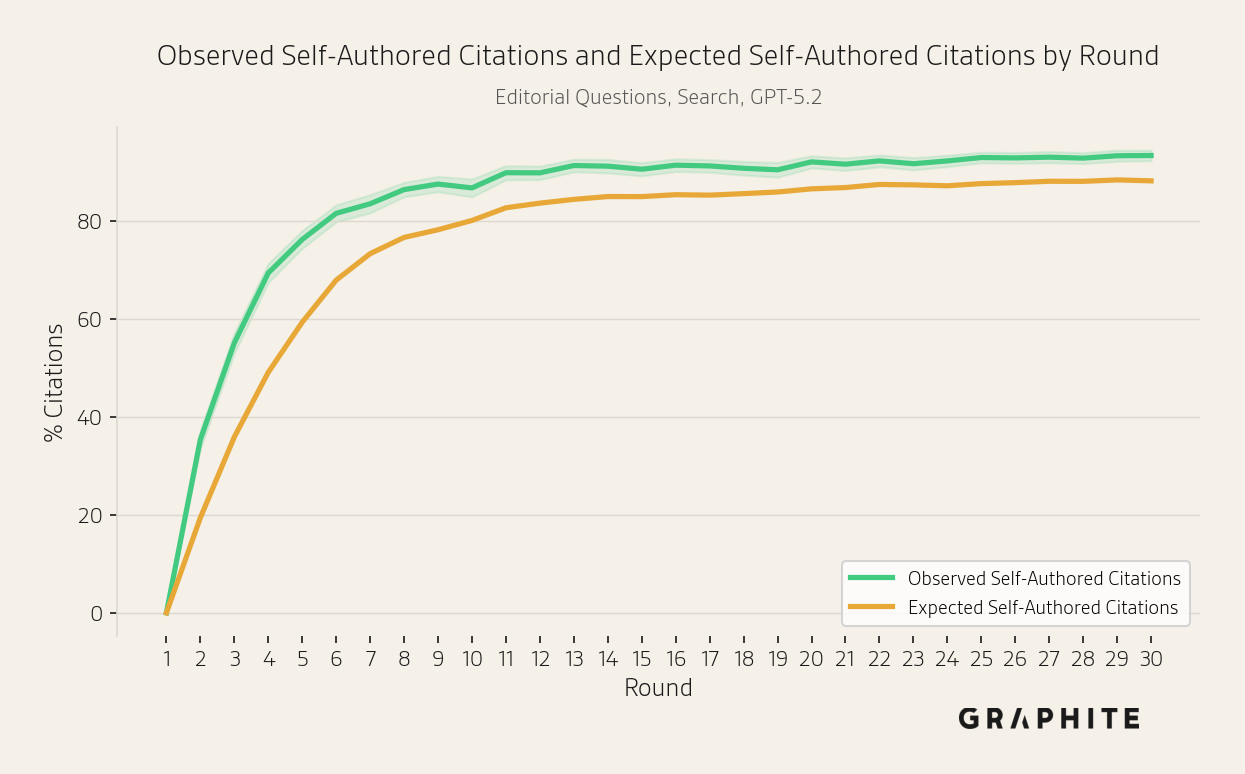
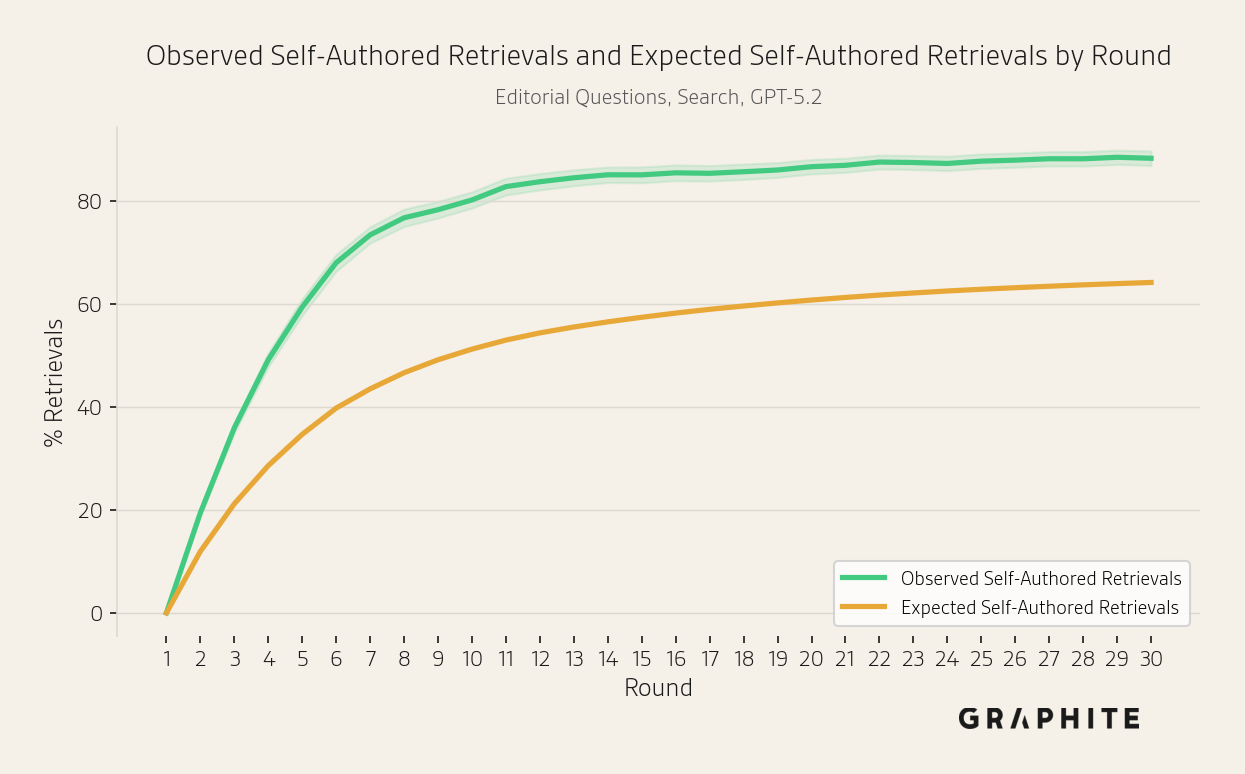
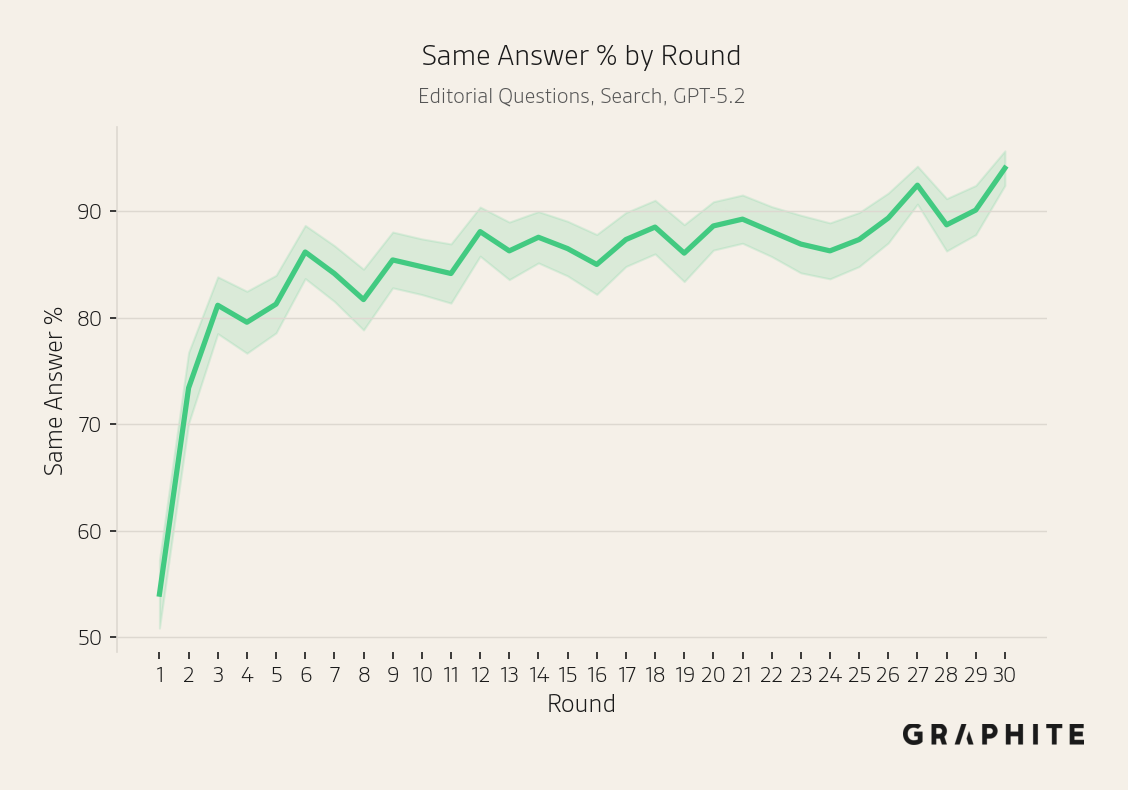
Why Do Self-Authored References Have Disproportionate Influence?
It is not surprising that the Replace All simulation often results in collapse, as it most closely mirrors the original model collapse paper. However, in the Replace One simulation, we find that collapse begins even when self-authored references constitute only a small proportion of the total reference set, even a single self-authored reference, or 10-20% of the total references. We find that these references are disproportionately cited, suggesting they exert greater influence on the response than the original references.
Is this because the references are AI-generated, or because they are self-authored? In this section, we analyze each candidate reference in round 2 of the ChatGPT Entity Replace One simulation, in which complete (unchunked) self-authored and original references compete directly for citations.
We find that 39.7% of the original references in the ChatGPT Entity dataset used in the Replace One simulation experiments are AI-generated. However, only about 3% of entity questions are collapsed at the start, before any self-authored references are added. We only observe widespread collapse when self-authored references are introduced. This suggests self-authorship, not AI generation, is the driver of collapse in our simulations. We test this more thoroughly below.
Self-authored references are cited far more often than original references, both AI-generated and human-written. We saw evidence of this in the Self-Authored Citations Over Expected metric in our experiments, and we investigate it in more detail here. We use GPTZero to classify original references as human-written or AI-generated. AI-generated originals have a citation rate of 9.4%, only modestly higher than that of human-written originals (7.4%), while self-authored references have a citation rate of 38.9%. (We verified the same pattern holds in the Search simulation and on Editorial questions.)
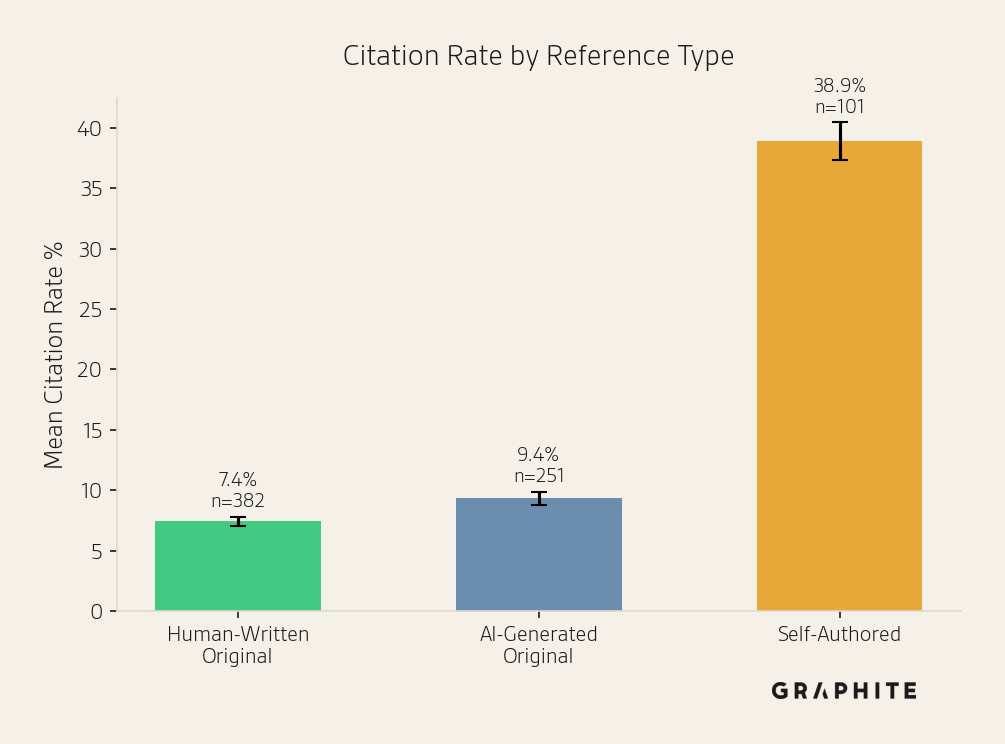
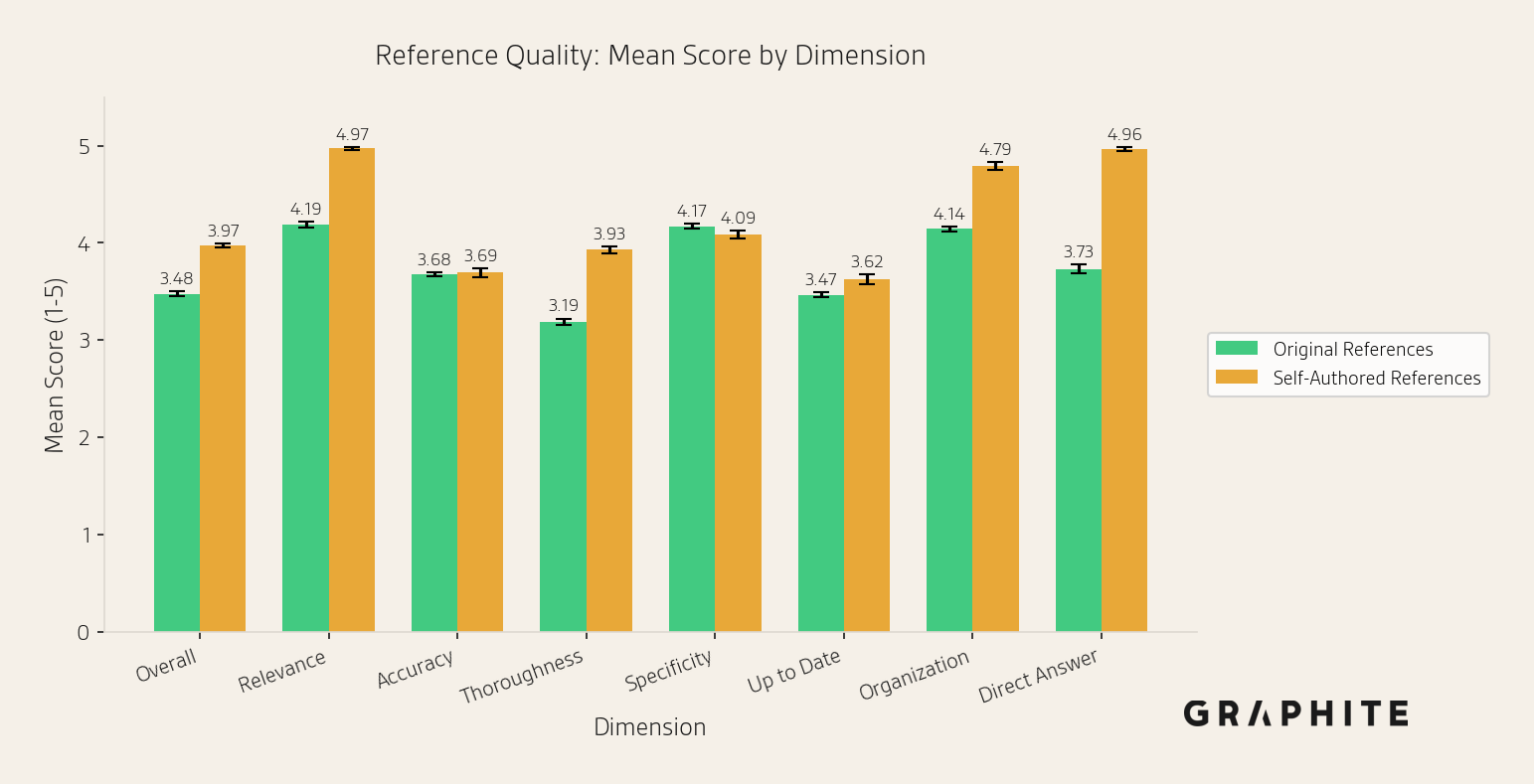
One explanation is that self-authored references are simply higher quality. To test this, we use GPT-5.2 to independently score each reference on eight dimensions, each on a 1–5 scale: overall, relevance, accuracy, thoroughness, specificity, up to date, organization, and direct answer. Note that although LLM-as-judge is subject to bias, here we explicitly want to know what the LLM thinks, since it is the LLM choosing which references to cite.
Self-authored references do score higher on most dimensions, with the largest gaps on direct answer (+1.23), relevance (+0.78), thoroughness (+0.74), organization (+0.65), and overall (+0.49). The two types are roughly tied in accuracy and up to date, and original references have a slight edge in specificity.
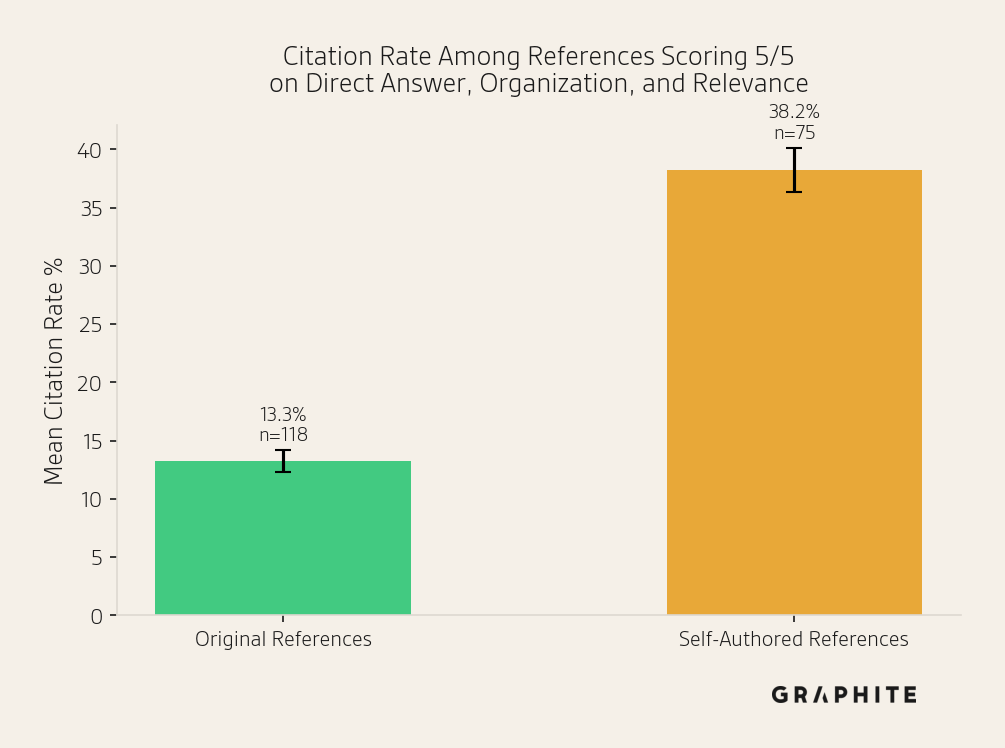
To control for this quality advantage, we restrict to references the judge scored 5/5 on the three dimensions where self-authored references most consistently scored highest: direct answer, organization, and relevance. Even within this subset (n = 193: 75 self-authored, 118 original), self-authored references are cited at 38.2% compared to 13.3% for original references, a 2.9x gap.
As a stronger test, we fit a linear regression model to predict the citation rate using indicators of whether a reference is self-authored or an original AI-generated reference, as well as the eight quality scores. Being self-authored increases the citation rate by 0.26 (95% bootstrap CI: [+0.23, +0.29], p < 0.001), whereas being an AI-generated original has no effect (−0.01, not significant). After controlling for all eight quality dimensions, self-authorship alone adds about 26 percentage points to a reference's citation rate, while AI generation adds none.
Self-authored references are not cited more often only because they are higher quality or AI-generated. While it is possible there is another important attribute of the self-authored references we did not control for that explains the gap, the results suggest self-bias. Prior work showed that LLMs prefer their own generations. From these experiments, we cannot tell whether the model prefers these references because their content matches its reasoning (how it would answer given similar references) or because of their style. In future work, we could add a reference that states a different answer, or test whether one model over-cites another's generated references.
This does not mean that the AI-generated references already being cited by AI are harmless. The collapse we observe in our simulations is driven by the self-authored references we introduce, but we do not test iteratively adding other types of AI-generated content, and it is possible that doing so could also lead to collapse.
In the Search simulation experiments, we also find that self-authored references are disproportionately retrieved. The retrieval mechanism itself may favor them due to higher semantic similarity with the query. We leave a deeper investigation of these mechanisms to future work.
What Types of Prompts Collapse?
We aggregate all the Search simulation experiments using the Entity Questions dataset and examine several factors to see which are correlated with collapse. Specifically, we examine statistics of the generations in the initial round, using only the original references. The factors most correlated with collapse are the number of unique entities and the mean length of responses.
name | Pearson correlation | p |
|---|---|---|
unique entities | -0.342 | 1.32e-24 |
length of responses | -0.245 | 5.31e-13 |
unique words | -0.223 | 6.21e-11 |
same answer % | 0.151 | 1.01e-05 |
entity ranking similarity | 0.164 | 1.61e-06 |
While statistically significant, these correlations suggest other factors also contribute to collapse. However, we see that prompts with responses that are longer and contain more unique entities, essentially more varied initially, are more resistant to collapse.
Which Entities Drop Out?
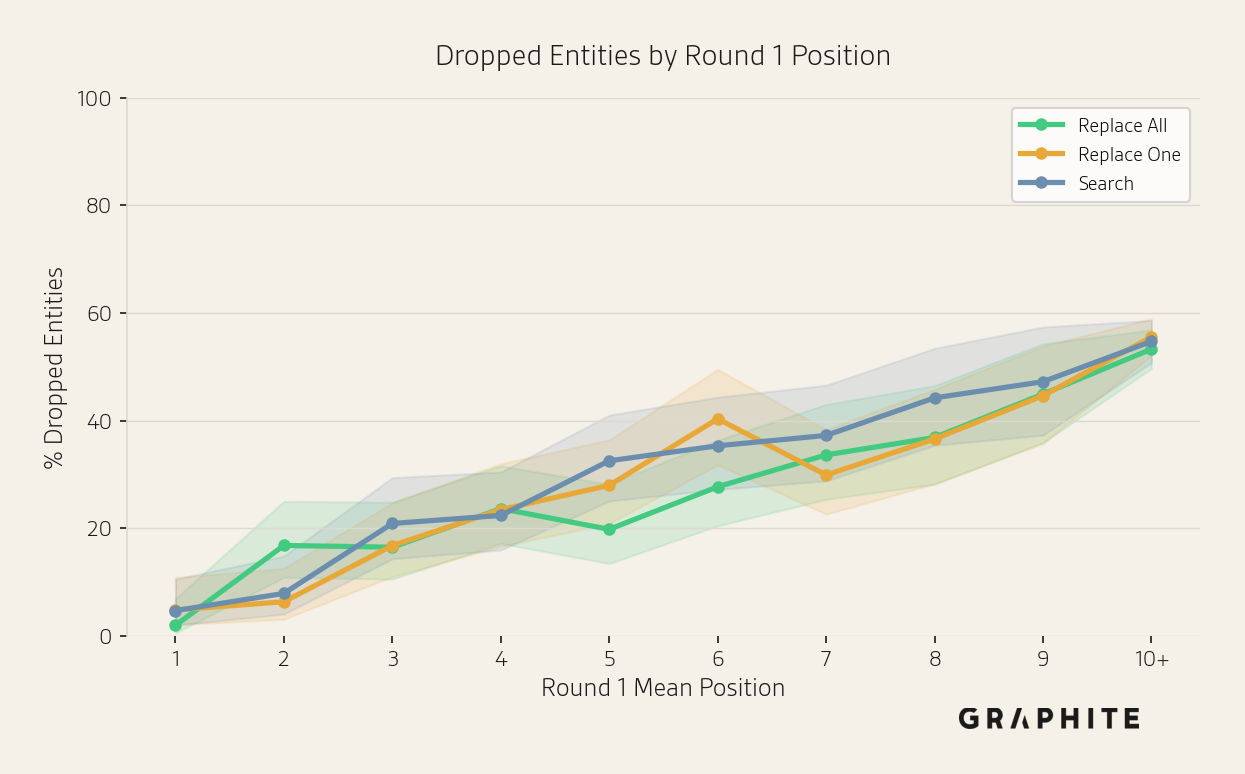
Next, we examine which entities tend to drop out of responses by the end of the simulation. We find that, as expected, the probability of an entity dropping out decreases as its initial visibility increases: low-visibility entities that appear in few responses initially drop out very frequently, whereas high-visibility entities rarely do, though even 100% visibility entities drop out about 7-10% of the time.
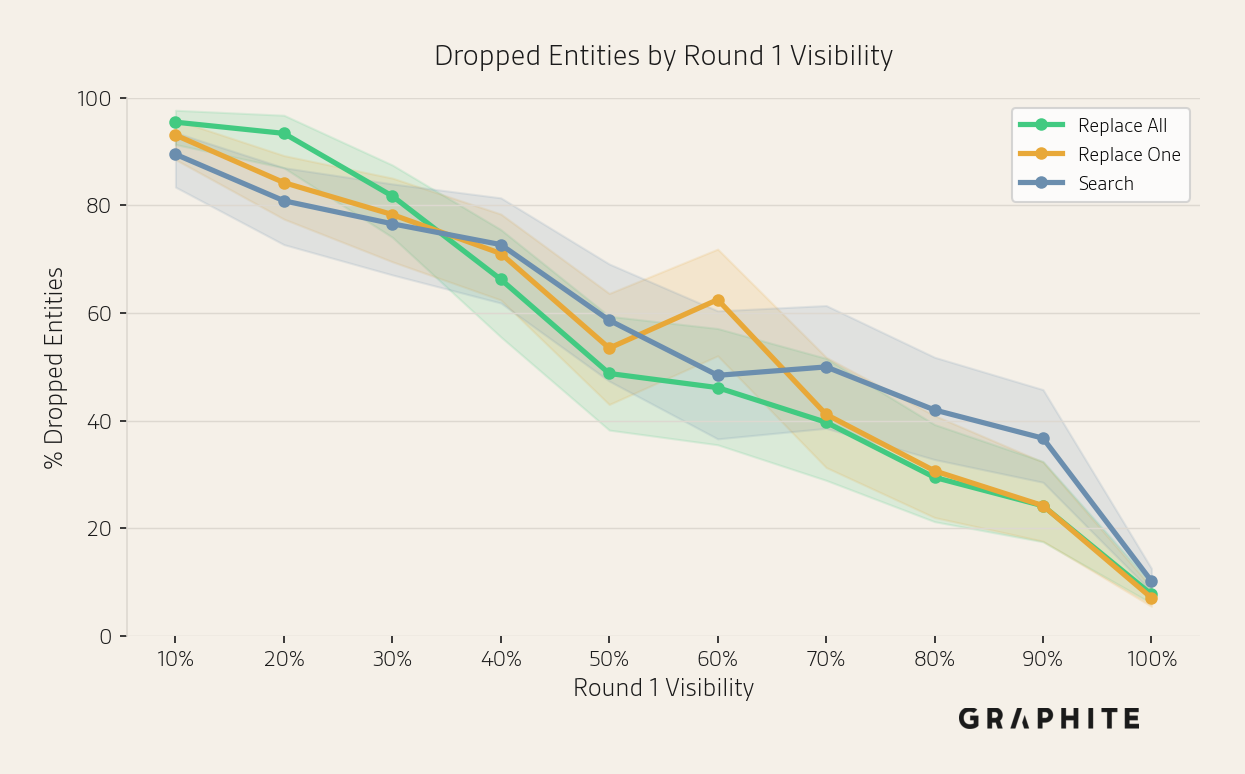
We also find a correlation between visibility and position: high-visibility entities tend to appear near the beginning of the response. (We provide data supporting this in our paper How to Track Entity Position in AI.) Therefore, better-positioned entities tend to drop out less frequently.
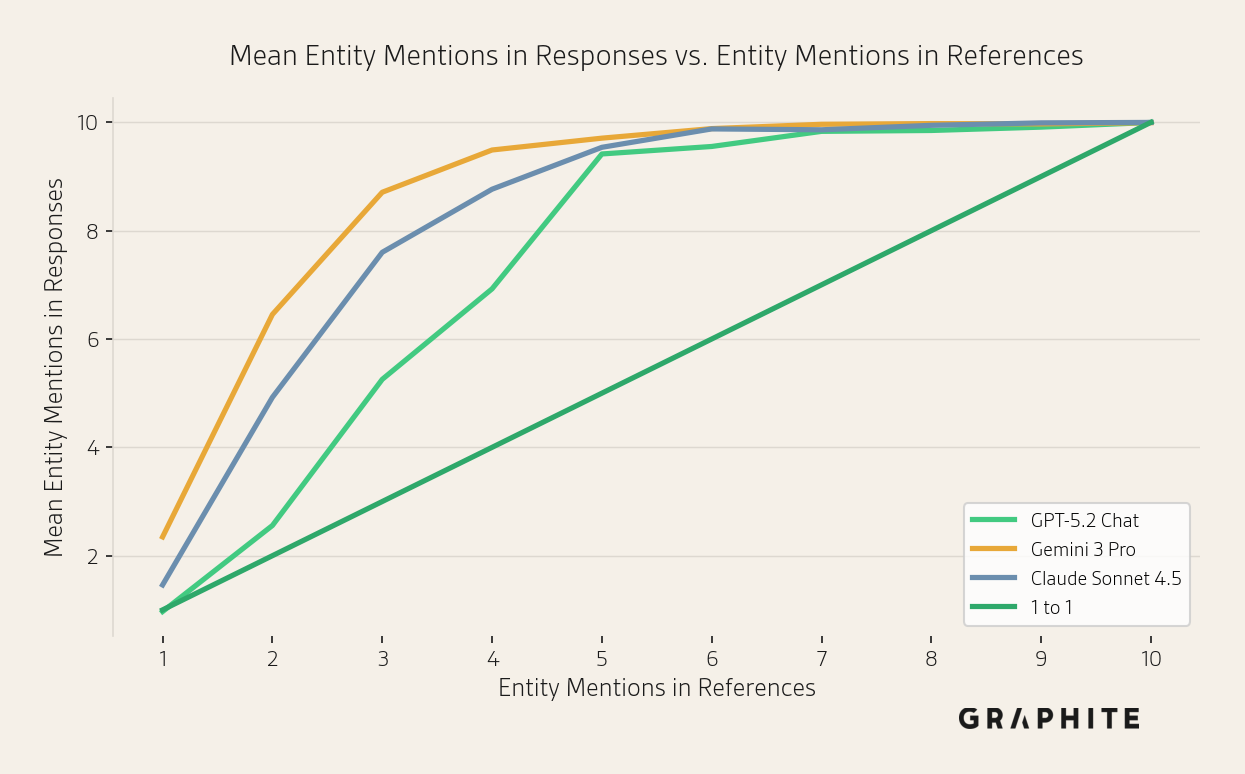
Does RAG Mirror the Input Entity Distribution?
Previously, we hypothesized that RAG does not mirror the distribution over answers in the references. In this section, we provide direct evidence that the distribution of entity mentions in responses does not necessarily reflect the distribution of entities in the references. For each entity, we plot the number of responses that mention it (y-axis) versus the number of references that mention it (x-axis). We restrict to questions with 10 references. Across all models, we generally see more responses mentioning an entity than references mentioning the entity, saturating around 5 input references. Gemini 3 Pro includes low-mention-count entities in the responses more often.
Additional Examples
Below are more animations of simulations from the Larger-Scale Experiments.
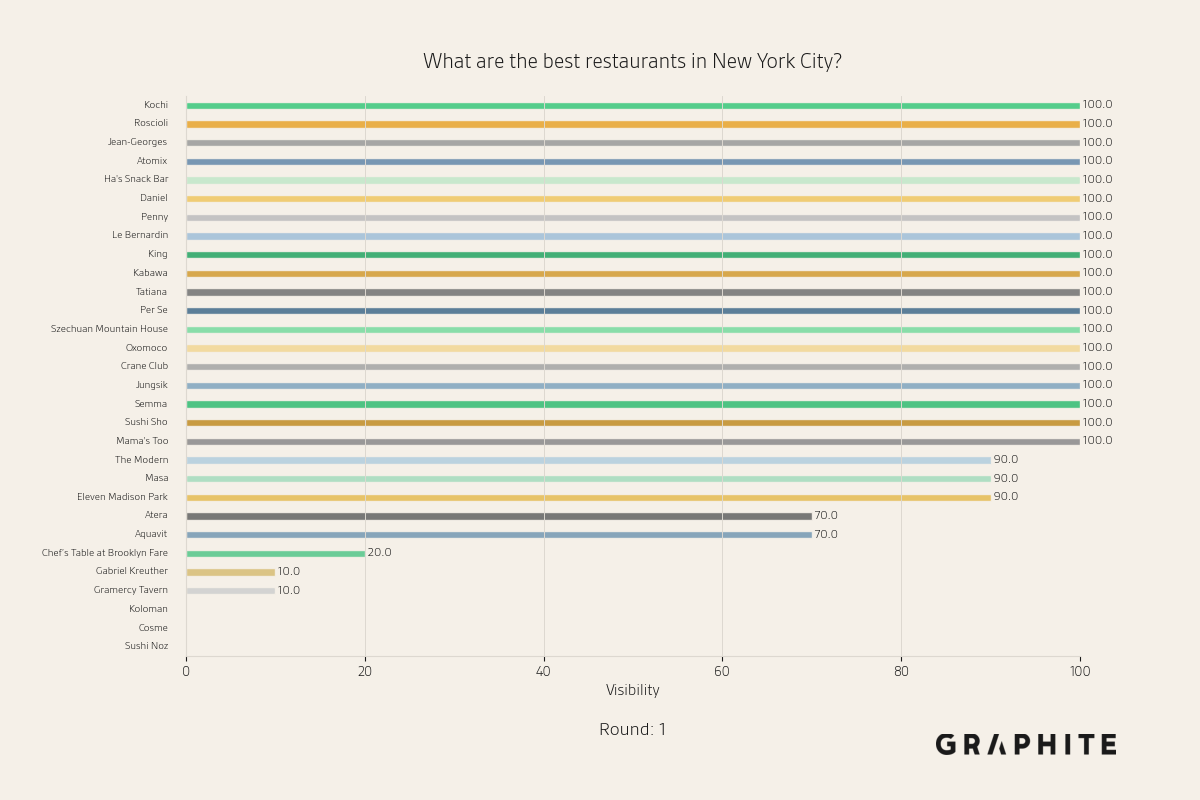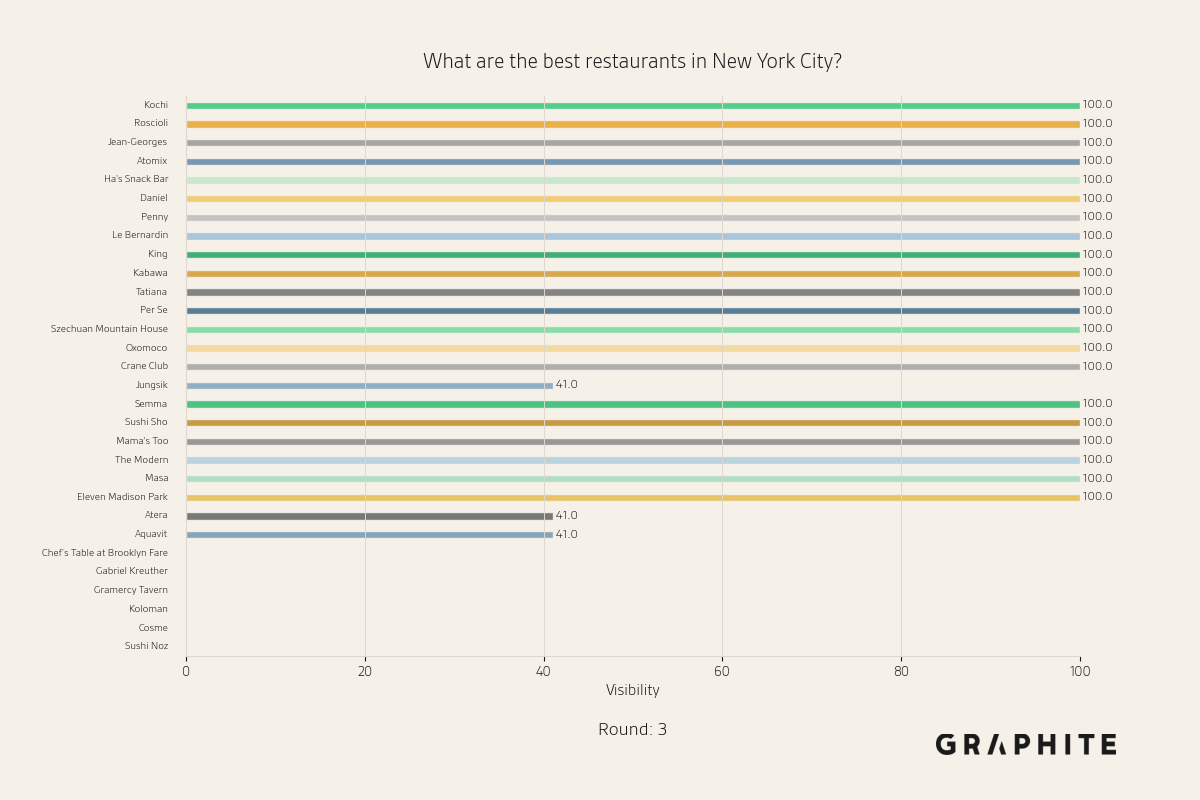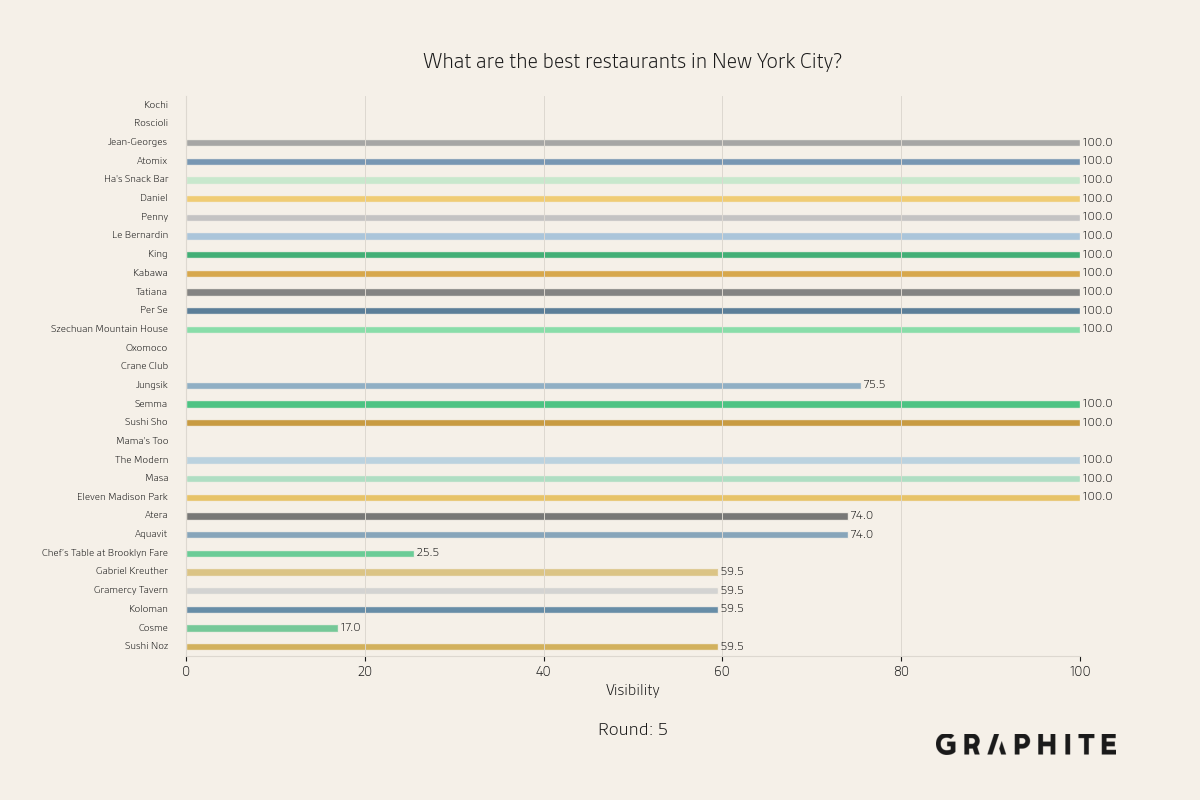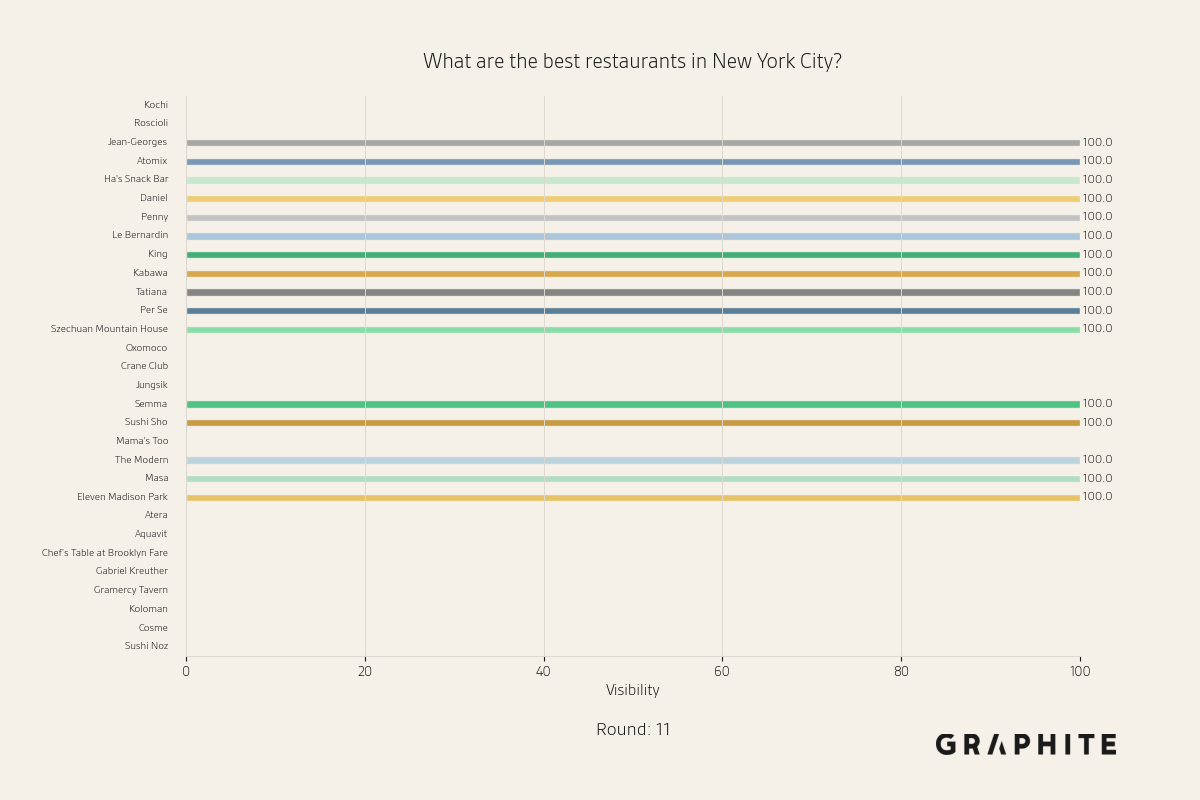
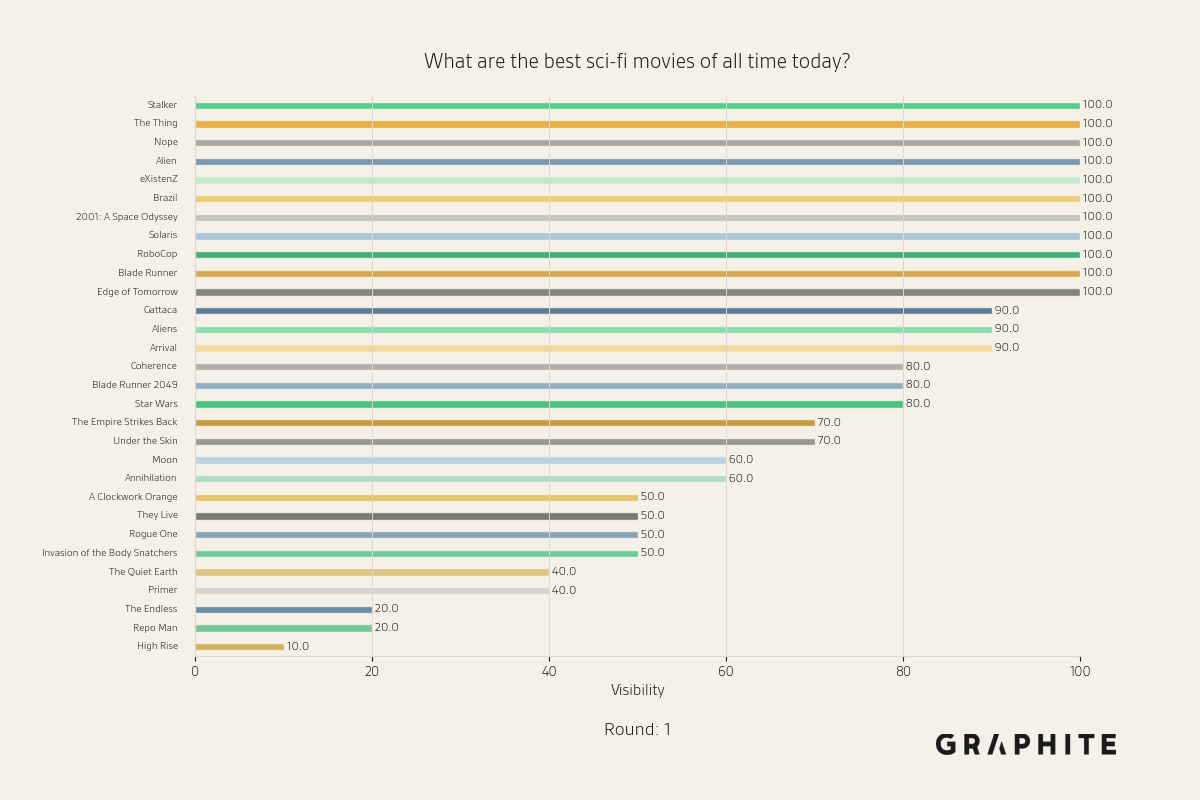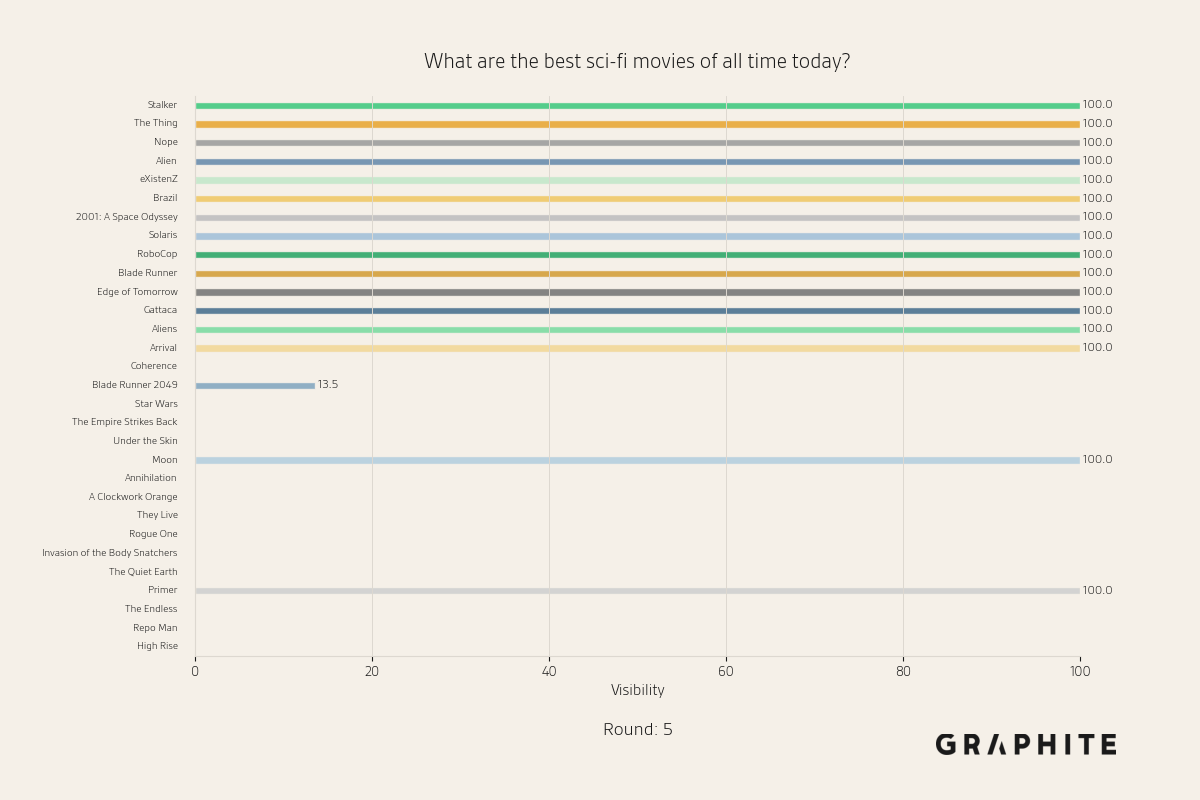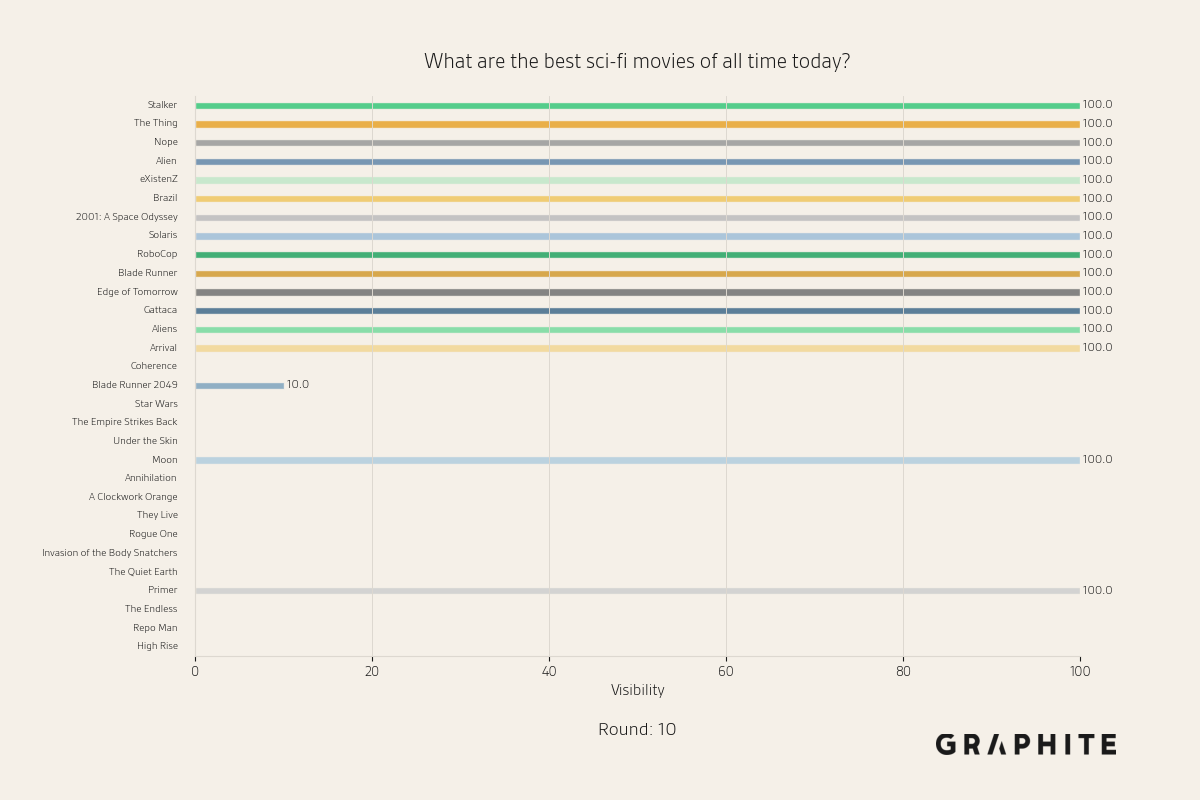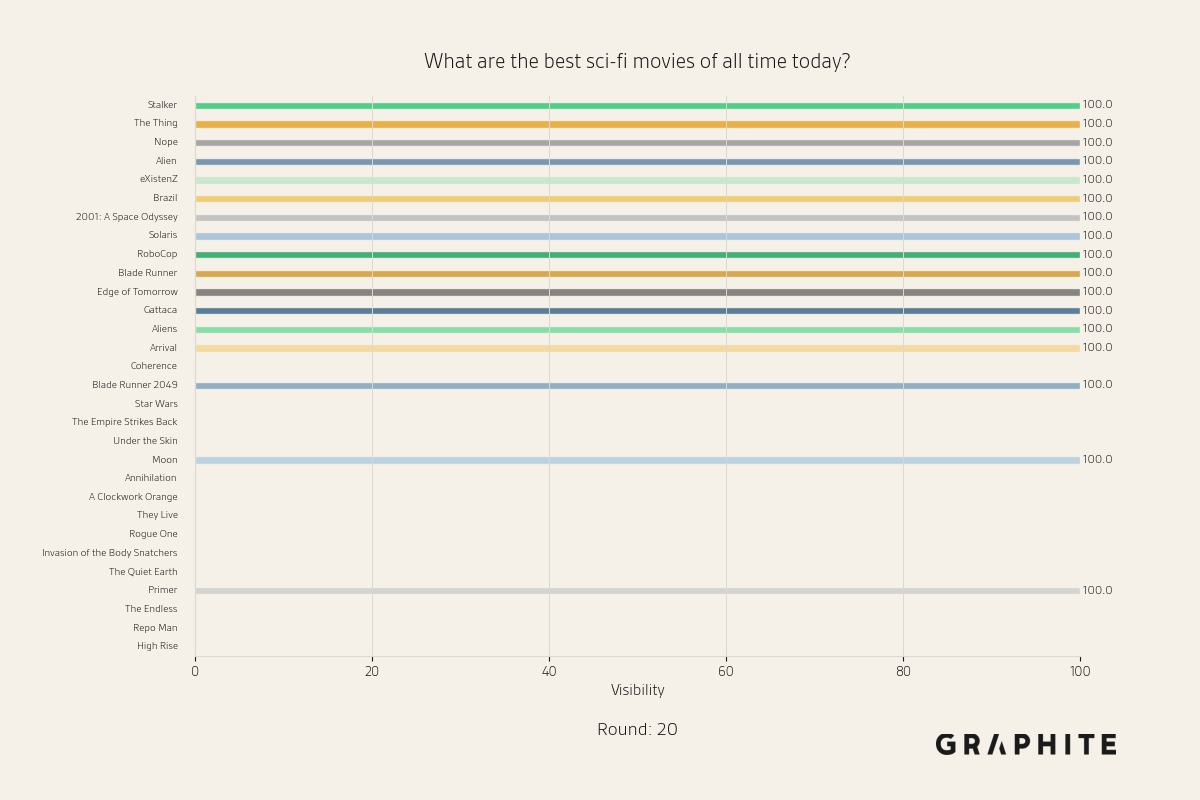
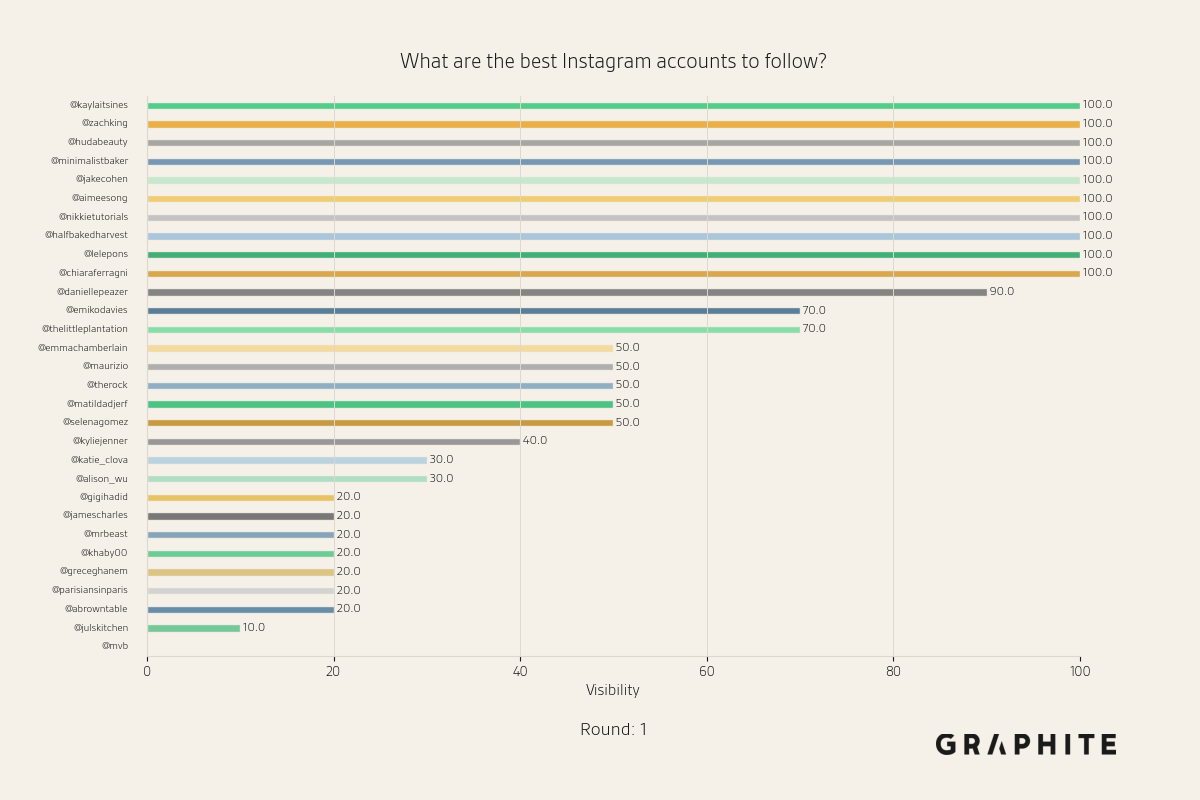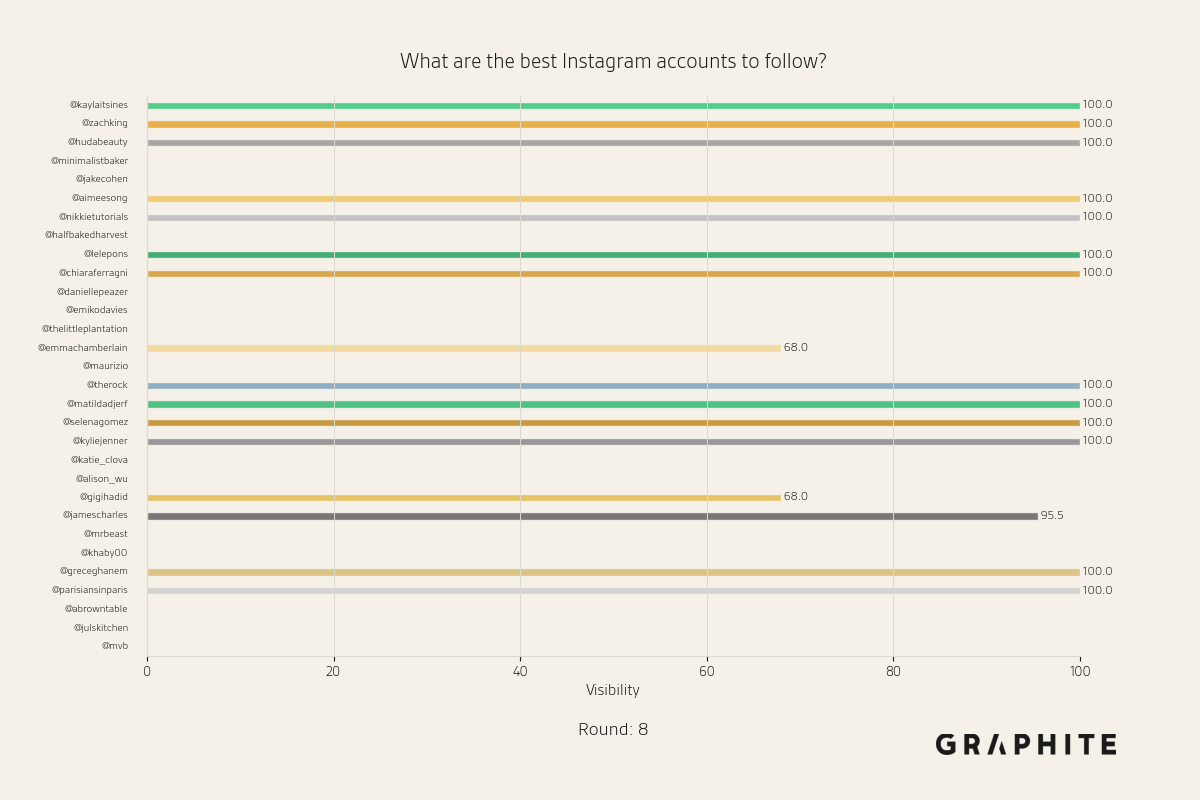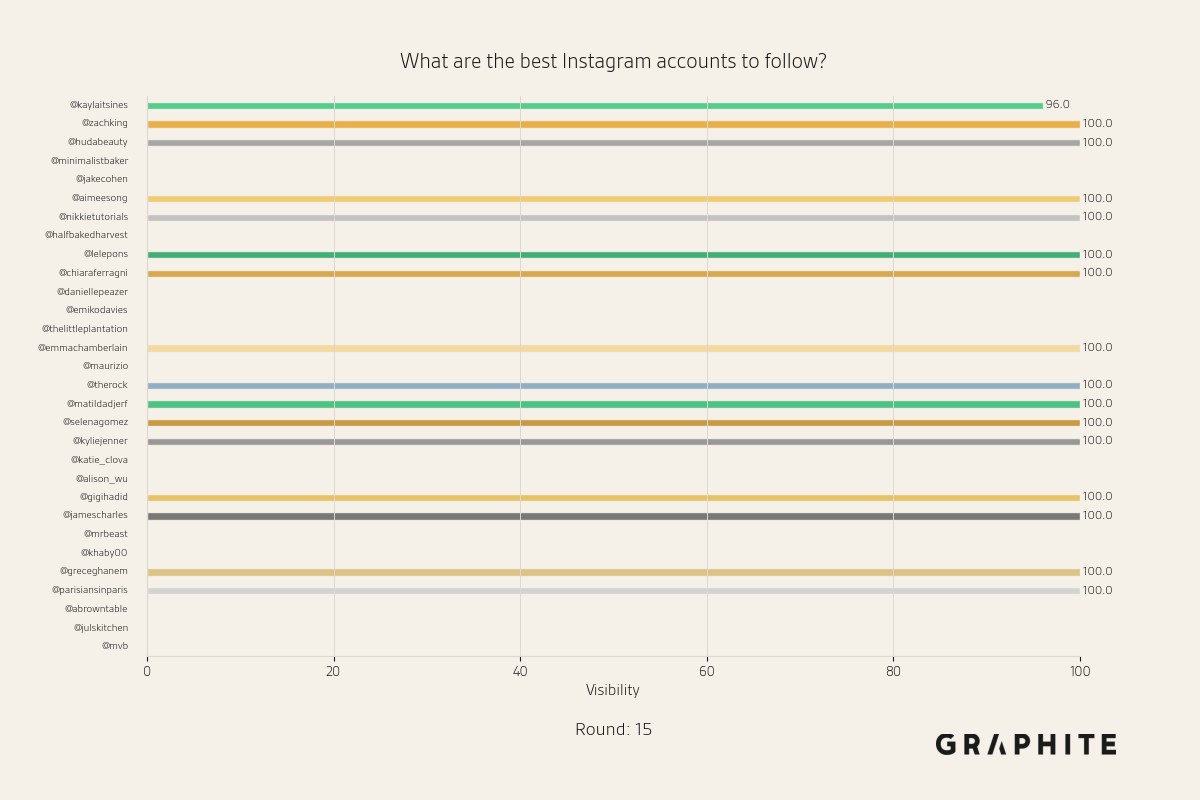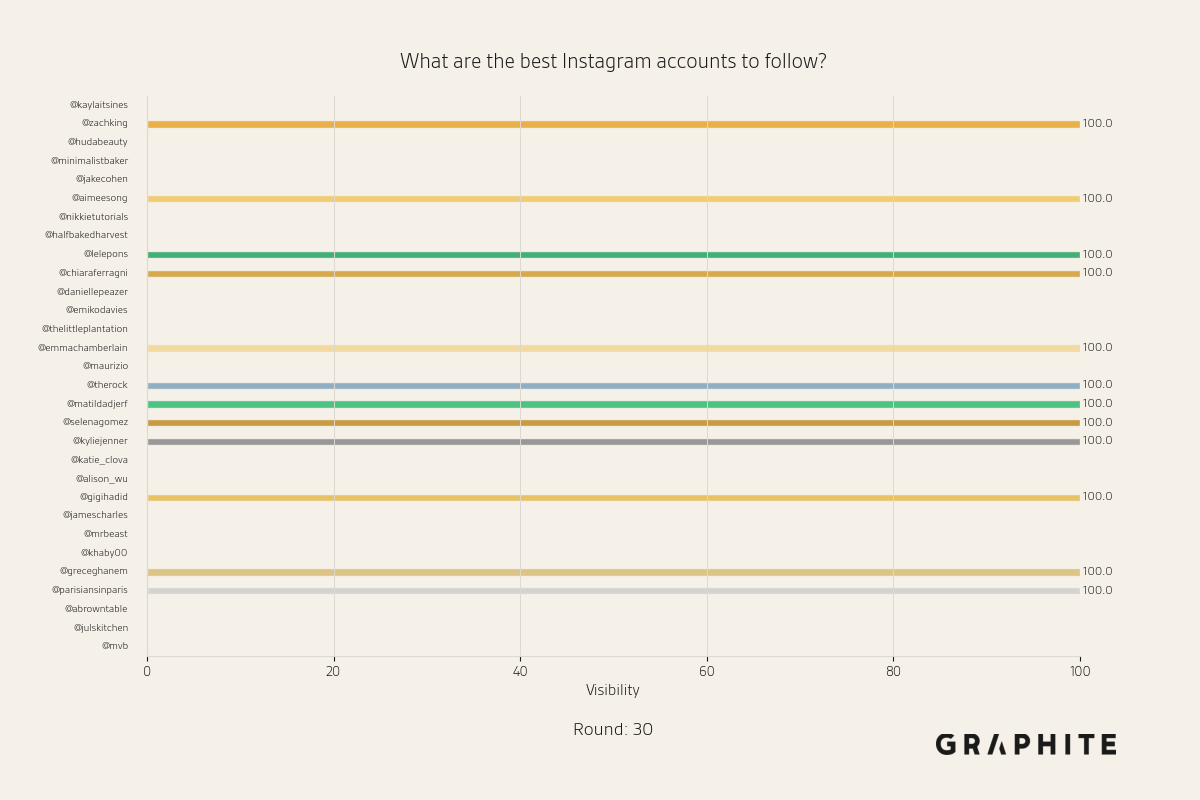
Simulation Design Choices
The simulations require configuration. We conducted 68 experiments while developing the approach to investigate AI search collapse for this report, to ensure the results were fair and not dependent on a single simulation detail. Here are some things we learned that accelerate collapse but chose not to include in the final experiments.
In early experiments, GPT-5.1 returned very short responses, resulting in short articles and quick collapse. We changed the prompt to elicit longer responses, so the average length of the original and self-authored references is similar.
We generally observed collapse across all prompts we tried, though we did not experiment with prompts explicitly designed to prevent collapse; we plan to study this in future work.
In the Search simulation, larger chunk sizes increase the rate and probability of collapse. The fact that smaller chunks lead to less collapse supports the hypothesis that self-authored references have disproportionate influence because they provide a direct and complete answer. However, the results we report here use the default chunk size.
Initially, we used raw responses as references, which led to more rapid and frequent collapse. However, we were concerned that this was unfair because the self-authored and original references looked very different, so we decided to convert them into articles.
In early experiments, we used smaller models to reduce costs, and in some cases, their responses collapsed more quickly. We chose to use larger frontier models that power consumer-facing AI systems for the experiments in this report.
Can We Mitigate AI Search Collapse?
In practice, there may be ways to mitigate collapse:
- Filter out AI-generated references during retrieval
- Diversify search results to filter out near-duplicates
- Encourage the model to favor diversity or fall back to its parametric knowledge via the system prompt or fine-tuning
We do not know precisely how commercial AI systems work, so these mechanisms may already be in place. However, whether these mitigations will be effective remains an open question.
Diversifying search results would only help if there is diverse, relevant information online; in some cases, a lack of diversity indicates real consensus, which can be challenging to distinguish.
AI Detection
Filtering out AI-generated references could mitigate the risk of collapse, since self-authored articles are AI-generated. Are AI companies already doing it?
As discussed in the Datasets section, we find that as of June 2026, 42.7% of the references for prompts in our dataset are AI-generated. While it does not appear that ChatGPT is filtering out AI-generated references now, would this be an effective strategy generally?
While AI detection algorithms are accurate at distinguishing purely AI-generated content from human-written content, their performance on AI-generated, human-edited content is less well studied. Additionally, identifying AI-generated content is likely to become more challenging as models improve.
We may be able to predict self-authorship directly by comparing a reference to an AI’s answer, but this is more specific and challenging than standard AI detection. Note also that we find that simply being AI-generated may not drive collapse, as self-authored references have more influence than AI-generated original references.
And as we have seen, even a single self-authored reference can trigger collapse, so even a small number of false negatives could be problematic.
Knowledge Collapse
The self-authored references in our simulations are also AI-generated: the text was written by AI, and the substance is its own answer.
There is also potential for a different type of collapse if many writers use AI as a thought partner while writing, and the substance of their article comes from AI, even if they write or edit the final text. For example, a writer covering “the best movie of all time” may use ChatGPT to compile a list of movies, even if they do not fully AI-generate the article. The article is not self-authored by our definition, yet the substance is still the model's answer. This is a form of what others have called knowledge collapse.
AI detection would not help here. A human-written article based on the model's answer may drive collapse but would not be flagged.
A similar dynamic occurs without AI when humans read the same sources or rely on Google's top results while researching an article. But the cost of creating that content is much lower with AI, making it easier to flood the internet with derivatives.
Limitations
Our simulations seed each question with original references retrieved from consumer AI tools in January 2026. We find that 38.9% are already AI-generated, and we cannot directly identify which are self-authored, the subset that seems to drive collapse. Any self-authored content already in the seed pool would only reduce the contrast we measure, so our collapse and disproportionate-influence results are conservative.
We do not test iterative addition of other types of AI-generated content, and doing so could also lead to collapse.
Our simulations suggest that retrieving self-authored articles leads to collapse, but we do not definitively prove that AI search collapse is already happening. As discussed, there may already be mechanisms in place intended to mitigate collapse, though it is unclear whether they will be successful.
We focus on information-seeking prompts, especially those involving comparisons of named entities. It is possible that collapse behaves differently on other types of prompts.
Conclusion and Future Work
AI-generated content is already prevalent online, and AI systems are retrieving it. Our simulations show that responses collapse when AI retrieves self-authored articles. This result is consistent across models, question types, and simulation designs we explore. Surprisingly, even a single self-authored reference can trigger collapse, because such references disproportionately influence the response. Whether current or future mitigations can prevent AI search collapse in practice remains an open question.
Future work, some of which is already in progress, includes studying collapse under agentic search, the effectiveness of mitigations, experimenting with one model retrieving another’s authored references, and how collapse may affect other types of prompts.
References
Druck, G., & Smith, E. (2026). Demystifying Randomness in AI. Graphite. https://graphite.io/five-percent/demystifying-randomness-in-ai
Druck, G., & Smith, E. (2026). How to Track Entity Position in AI. Graphite. https://graphite.io/five-percent/how-to-track-entity-position-in-ai
Farahani, M., & Johansson, R. (2024). Deciphering the Interplay of Parametric and Non-parametric Memory in Retrieval-augmented Language Models. EMNLP 2024. https://arxiv.org/abs/2410.05162
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS 2020 (Advances in Neural Information Processing Systems 33, pp. 9459–9474). https://arxiv.org/abs/2005.11401
OpenAI (2023). GPT-4 Technical Report. https://arxiv.org/abs/2303.08774
Panickssery, A., Bowman, S. R., & Feng, S. (2024). LLM Evaluators Recognize and Favor Their Own Generations. NeurIPS 2024. https://arxiv.org/abs/2404.13076
Paredes, J. L., Druck, G., & Smith, E. (2025). AI Content in Search & LLMs. Graphite. https://graphite.io/five-percent/ai-content-in-search-and-llms
Paredes, J. L., Druck, G., Benson, B., & Smith, E. (2026). AI Now Writes as Many Online Articles as Humans Do. Graphite. https://graphite.io/five-percent/ai-now-writes-as-many-online-articles-as-humans-do
Peterson, A. J. (2024). AI and the Problem of Knowledge Collapse. arXiv:2404.03502. Published in AI & Society, 2025, 40(5), 3249–3269. https://arxiv.org/abs/2404.03502
Shumailov, I., Shumaylov, Z., Zhao, Y., Papernot, N., Anderson, R., & Gal, Y. (2024). AI models collapse when trained on recursively generated data. Nature, 631(8022), 755–759. https://doi.org/10.1038/s41586-024-07566-y
Singh, A., Ehtesham, A., Kumar, S., & Khoei, T. T. (2025). Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG. https://arxiv.org/abs/2501.09136
Wang, T., Horiguchi, A., Pang, L., & Priebe, C. E. (2025). LLM Web Dynamics: Tracing Model Collapse in a Network of LLMs. https://arxiv.org/abs/2506.15690
Wu, K., Wu, E., & Zou, J. (2024). ClashEval: Quantifying the tug-of-war between an LLM's internal prior and external evidence. NeurIPS 2024 (Datasets and Benchmarks Track). https://arxiv.org/abs/2404.10198
Appendix
In the Comparison of Models section, we presented experiments comparing models on questions common to both the ChatGPT and AI Overview datasets. Here we provide complete results on those datasets, including questions that are not in the intersection.
Replace One, GPT-5.2 Chat
Replace One, Gemini 3 Pro
Replace One, Claude Sonnet 4.5