
In June 2024, the authors first described how randomness works in AI and proposed frameworks to measure brand performance in AI as part of a Reforge Webinar. Specifically, we proposed running multiple prompts multiple times to estimate the probability distribution of a brand's presence in responses, now commonly referred to as “visibility.”
Since then, over 70 tools have launched to measure visibility. Nearly every company we speak with is using one of these tools to measure its performance.
However, there is increasing scrutiny about how accurate these tools are and confusion about how randomness in AI works.
In this paper, we build on our previous work to demystify how randomness works in AI. We explain that AI often provides different responses to the exact same prompt because randomness is built into how Large Language Models (LLMs) generate text, and show that measuring AI responses is no different from measuring everyday stochastic processes such as the weather or commute times. By applying basic statistics to a sample of responses, we can successfully estimate a brand's visibility and position.
Key Takeaways
1. AI responds randomly, but the randomness is predictable. Responses are generated from a probability distribution, and the generative process is easy to understand even without a technical background.
2. Measuring visibility is straightforward. We need to generate multiple responses, but as few as 10 is enough for a quick estimate for entity comparison prompts.
3. Measuring position is also straightforward. Again, a sample of 10 responses is enough for a quick estimate.
4. For cases that require more precision, we can use statistical tools to assess the accuracy of position and visibility estimates, and use sequential sampling to efficiently determine the right number of responses, based on the desired precision and our risk tolerance.
5. Responses from APIs, logged-out accounts, and logged-in accounts can vary significantly. Prompt tracking tools track either logged-out accounts or use APIs. This means that while prompt tracking tools provide directional data, they should not be used as ground truth.
How to Measure Visibility and Position
1. Do not rely on a single response. Instead, run each prompt at least 10 times for a quick estimate.
2. For more precise estimates, rather than gathering large numbers of responses by default, use sequential sampling: add responses iteratively until the confidence interval is sufficiently tight.
3. Use confidence intervals or statistical tests to decide if changes are real (make a copy of the provided sheet). Generally, be skeptical of small differences in visibility and position, especially for responses that do not use web search.
4. Track weekly or biweekly. If tracking daily, take care not to interpret noise as signal.
5. Use a new chat for each prompt and disable memory.
6. Focus on the right metric for your situation:
- Visibility (how often a brand appears) is the best initial metric, especially if your brand is not yet consistently mentioned.
- Position (how prominently a brand appears when it does appear) matters more when a brand already appears frequently, and the focus is on its placement relative to competitors.
7. Supplement prompt tracking tools by also manually gathering responses from AI with a logged-in account.
About the Authors
Gregory Druck is Chief AI Officer at Graphite.io, where he leads a team of scientists and engineers building AI tools for growth and researching how AI is reshaping marketing. Previously, he was the Chief Data Scientist at Yummly, where he built NLP and computer vision systems for the smart kitchen. Prior to Yummly, he was an NLP and search researcher at Yahoo! Research, with internships at Google and Microsoft. He earned a Ph.D. from the University of Massachusetts Amherst, where he worked on semi-supervised and active machine learning with Andrew McCallum.
Ethan Smith is CEO of Graphite.io, a research-driven growth agency that works with companies like Webflow, Adobe, and Upwork. He is an adjunct professor at IE Business School and teaches SEO and AEO at Reforge. His research has been published in ACM, Axios, Financial Times, and The Atlantic. Prior to founding Graphite, Ethan was a growth advisor to Masterclass, Robinhood, and Honey. Ethan was a research assistant focused on human-computer interaction and psychology at UC Santa Barbara and University College London.
LLMs Typically Generate Different Responses to the Same Prompt
How does ChatGPT respond to “What are the best flavors of ice cream?”
If we ask multiple times (making a new chat each time), we get different responses. Here are three distinct responses from gpt-5.2-chat-latest using the OpenAI API. We highlight the flavors that occur only in a single response in red and those that occur in two responses in blue.
We generate 200 responses and show the top 30 most frequently mentioned flavors (after grouping similar flavors) below, with the percentage of responses in which they occur, also known as visibility. Some flavors, such as vanilla, chocolate, and cookies & cream have a visibility of 100%, meaning they appear in all responses. Others, like fudge brownie and coffee, have visibility of 94% and 49%, respectively. Long-tail flavors (outside the top 30), such as s’mores and earl grey, have visibility of 4% and 1%, respectively. In total, there are 57 unique flavors in the 200 responses. We show the top 30 in the plot below.

The order in which the flavors appear in the responses also varies. Vanilla and chocolate are always first and second, respectively, across all 200 responses. Salted caramel always appears, but in different positions, with an average position of 7.3. In the 49% of responses in which coffee appears, its average position is 15.5.
If every answer is different, are visibility and position impossible to measure?
Visibility is Measurable
If we look only at one response (as some tools do), for example, the one in the rightmost column of the table above, we would think that s’mores appears as often as vanilla. In reality, s’mores appears in only 8 of the 200 responses, while vanilla appears in every response.
If we look at the first 10 responses instead, our visibility estimates are 100% for vanilla and 10% for s’mores, which is much closer to what we see in 200 responses. As with other statistical processes, our estimates improve as we use more data.
In the following figure, we show how the visibility values change with the number of responses. Notice how the estimates stabilize as we add responses, but with diminishing returns. The visibility estimates after 10 responses are not substantially different from the estimates with 200 responses.
Statistics also provides us with tools to compute margins of error and evaluate whether differences are significant or could be due to noise.
With an estimate of 10%, we can be 95% confident that the true visibility for s’mores is between 1.79% and 40.42%, and that the true visibility of vanilla is between 72.25% and 100.00%. Since these ranges do not overlap, we can conclude that the difference in visibility between vanilla and s'mores is statistically significant, even though we only examined 10 responses.
Position is Measurable
Position is measurable in the exact same way.
Here we visualize the position distribution for Cookies & Cream and Coffee. Cookies & Cream appears in every response, most frequently at position 5.

Coffee appears in 49% of responses and most frequently at position 16-18, though the position distribution is more spread out.

As with visibility, the average position estimates stabilize as we add responses. Here, we only consider entities with visibility greater than 10%. As we discuss later, it does not make sense to measure position with entities that appear infrequently.

“What are the best flavors of ice cream?” is also highly subjective, and AI responses vary significantly; the metrics converge much more quickly for “What is the best board management platform for nonprofits, and how do their security and compliance features stack up?”

We explore how statistics can help with prompt tracking in detail below. But first, we explain why ChatGPT responds differently to the same prompt.
How LLMs Generate Text
It is generally understood that LLM responses differ, but this is attributed to incoherence or AI “changing its mind.” The real reason is that generation involves randomly sampling from a probability distribution. We next explain how Large Language Models (LLMs) generate text.
Large Language Models
LLMs are neural networks built on the transformer architecture, trained on massive amounts of text from the internet. During training, the model learns patterns about which words tend to follow other words in different contexts. This knowledge is encoded in billions of numerical parameters called weights. After initial training, the model is further refined to follow instructions and hold conversations.
In this article, we focus on generating text from a trained LLM. While the training process is complex, the generative process is easy to understand without a technical background.
Next Word Prediction
Large language models (LLMs) generate text one token at a time. A token is a sequence of characters that is typically smaller than a word. For this article, the distinction is not critical, so we will assume token = word to make the examples easier to understand.
To generate the next word, an LLM first predicts a probability distribution over all possible words, based on the previous words. The better the word “fits” after the previous words, the higher its probability. The sum of the probabilities over all possible words is 1. Most words will have probabilities very close to 0.
For example, consider the prompt “What is the best CRM?”
Suppose that the LLM has already generated a few words of the response, and is now generating the word represented by ___.
“The best CRM is ___”
The next word is likely to be the name of a CRM. For example, we may have next word probabilities as follows:

Note that “chocolate”, which does not fit semantically or grammatically, receives a probability very close to 0.
To select the next word, the generative process randomly samples one according to this probability distribution. Think of this step as rolling a (giant) weighted die, where there is one face for each possible word, and the weight, or chance of rolling each word, is proportional to its probability. That is, since “Salesforce” has a probability of 0.31, it will be selected as the next word roughly 31% of the time, and Zoho will be selected as the next word roughly 25% of the time.
After the word is selected, it is added to the context (the preceding words), and the process is repeated. Suppose the algorithm randomly selected “HubSpot” above.
“The best CRM is HubSpot ___”
A period or a preposition (such as “for”) has the highest probability of being generated next.
Temperature
LLM APIs often have a configuration parameter called the temperature. A lower temperature value makes the probability distributions more concentrated on the most likely tokens, while a higher temperature value makes them more uniform. We can use this parameter to increase or decrease the “creativity” of the generations. However, ChatGPT and other consumer-facing AI assistants do not allow users to adjust the temperature and other sampling parameters, such as top-k and top-p, and the random seed, so we do not consider them for the remainder of this article. In our experiments, we use the default API temperature.
Inputs to Next Word Probability Calculation
The inputs to the next word probability calculation are:
- Preceding words in the context window, including
- System prompt
- User prompt
- Previous messages in the chat
- Reasoning tokens
- Personalization: messages from previous chats or model knowledge about the user
- Output of a tool, for example, content retrieved for retrieval augmented generation (RAG), or a response from a sub-agent
- Previously generated words in the response
- LLM weights
What Causes Responses to the Same Prompt to Be Different?
Now that we know how LLMs generate text, we review the factors that could lead to different responses to the same prompt.
Sampling Changes Responses
First, note that the randomness (rolling the weighted die) in the generative process above means the responses will almost always differ, even if the probabilities are identical.
Previously Generated Words Change Responses
The response could also differ if the probability distributions over the next word change. The probability distributions depend on the preceding words in the context window and the LLM weights.
Randomness Compounds (Autoregressive Stochastic Process)
Because the random selection of words changes subsequent probability distributions, the randomness in selecting each word “compounds” to change the later probability distributions. Early random selections can take the response in drastically different directions.
To illustrate this, if asking a question, and the highest probability first words are “Yes” or “No”, the following explanation or justification will be determined by that initial random selection. For example, if we ask “Is it wrong to steal food to feed your starving family?” (instructing the model to answer only yes or no, followed by a justification, to avoid the default “it depends” behavior), we see that it sometimes selects “yes” and sometimes “no” and the rest of the response depends on this choice.

Random token selections and the compounding of that randomness account for the vast majority of variation in responses.
Changes to Other Inputs
The other components that determine the probability distributions change less frequently than the random selections, which change with every generation.
We assume that the prompt is constant.
Tool Outputs and Reasoning Change Responses
Tool outputs change responses because they are added to the context. The most common example is the web search tool, which retrieves additional content from the web and adds it to the context window.
Web search results may change frequently as new content is published. However, ChatGPT, the most popular AI assistant, frequently does not use the search tool. Based on Graphite’s prompt tracking tool, in ChatGPT, about 10% of prompts trigger a web search when logged out, and about 50% do so when logged in. Search engines are also generally stable, in that the results do not change drastically day to day. For example, in our Google SERP database, on average, 6.2 of 10 results remain the same over a three-month period.
Reasoning and responses from sub-agents also change responses, though these appear less frequently in consumer-facing AI assistants.
Personalization Changes Responses
Personalization will change probabilities by incorporating additional context so that different users can expect different responses. In traditional search, personalization is limited to specific intents, like local search. But not much is known about how much personalization will affect information-seeking requests in AI. We discuss this further in the API, Logged Out, and Logged In Responses section.
System Prompt and LLM Weights Change Responses When Updated
We do not know how often the system prompt is changed, but doing so likely requires extensive testing, so we do not expect it to change very frequently.
The LLM weights also change infrequently. Pre-training the base LLM is extremely expensive and may occur only once a year. (This is why LLMs often have surprisingly distant knowledge cutoffs.) Fine-tuning is significantly cheaper, and newly fine-tuned LLMs are likely to be released more frequently; however, as with the system prompt, these releases will likely require extensive testing. In the OpenAI API, for example, new named versions of LLMs are typically released every few months, and AI companies announce major model releases. For example, GPT-5 was released on August 7, 2025, GPT-5.1 was released on November 12, 2025, and GPT-5.2 was released on December 11, 2025.
There may be slight differences in probabilities due to implementation details, hardware, non-deterministic approximations, and related factors, but we do not focus on these here.
Implications for Prompt Tracking
We now understand that LLM responses are randomly selected from a probability distribution, and we know what inputs affect that distribution. What are the implications for prompt tracking?
Recent reports have highlighted inconsistencies in prompt tracking tools. Many in the community are questioning whether visibility and position are too difficult to measure. In the following sections, we conduct experiments and provide statistical tools to empirically derive recommendations for prompt tracking.
Measure Using a Sample of Responses
Responses vary, but the underlying probability distributions are stable and measurable. To measure them, we have to prompt multiple times and take the average.
We proposed this idea in June 2024. We explained that, unlike traditional search, which has low position variance, LLM responses can vary substantially. We proposed tracking the percentage of time a brand appears relative to its competitors by running the same prompt multiple times, rather than just once, as in traditional search. Additionally, we described running different prompt variations across multiple LLMs. We suggested combining the multiple runs, prompt variants, and surfaces into a single metric we called “share of AI answers.” This is now commonly referred to as visibility: the percentage of responses in which a brand appears.
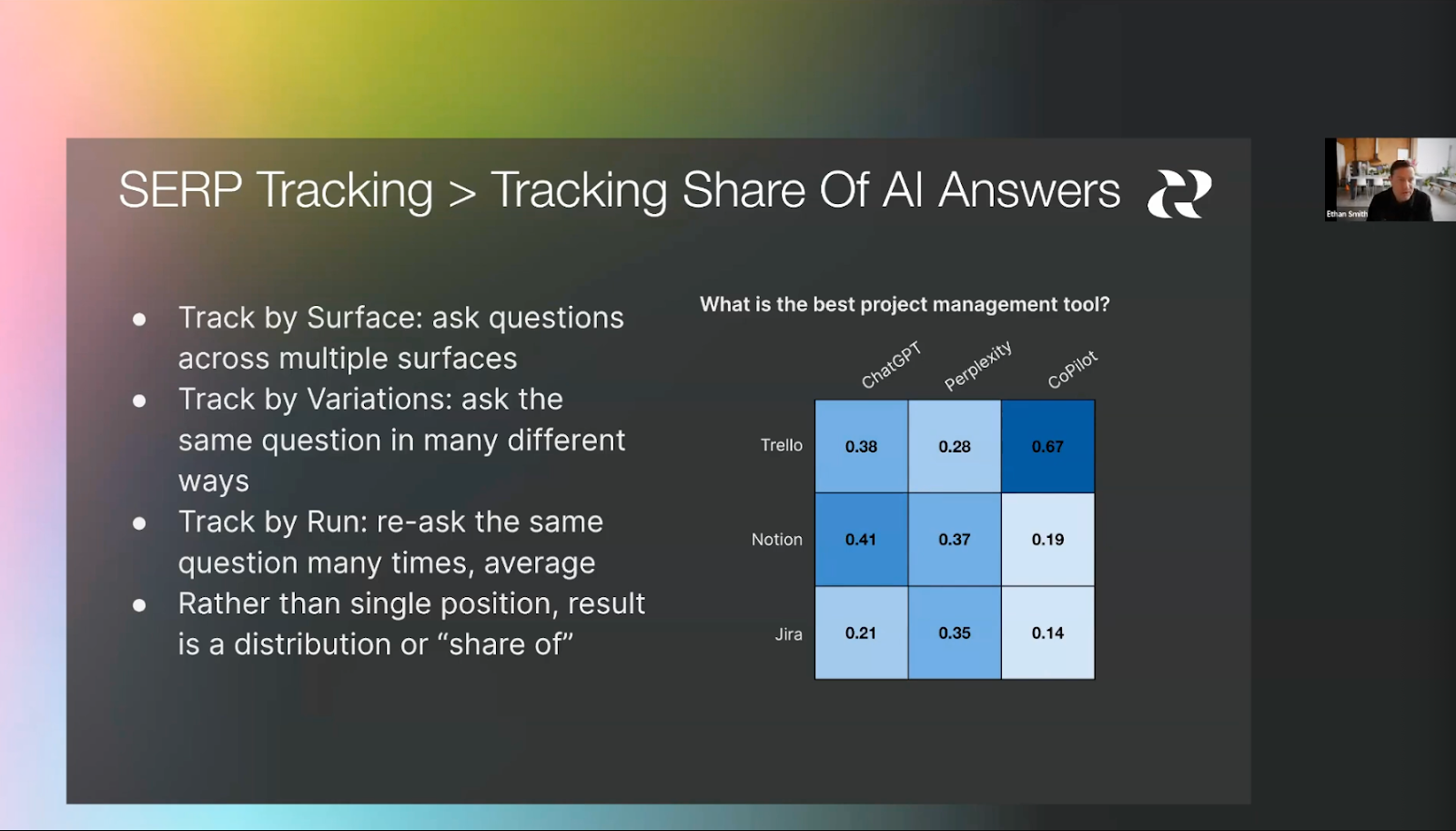
We next discuss tracking visibility and position in detail.
We mostly use the more general term “entity” in place of brand or product going forward.
Tracking Visibility
First, note that it does not matter that entire responses and lists of products mentioned typically differ across runs. Imagine flipping a set of weighted coins simultaneously. The exact set of coins that land heads will differ every time, but that does not mean the system is unmeasurable. Each coin has a bias, and by running the experiment many times, we can estimate the probability of heads for each coin. Similarly, while individual ChatGPT responses vary in which products appear, the visibility of a given product across many responses is stable and measurable.
Note that we focus on entity comparison prompts, which are the primary use case for prompt tracking tools. Results may differ for other prompt types.
How many times should we run each prompt? One is not enough, but how many responses do we need? Empirical analysis and statistical tools allow us to answer these questions precisely.
More data always increases the accuracy of an estimate, though with diminishing returns. Since prompt tracking has a cost, we would like to generate only the responses necessary to get the estimate we need. In many settings, rough estimates are sufficient. If the goal is to understand whether a brand appears frequently or rarely, distinguishing between 70% and 80% visibility matters less than distinguishing between 70% and 10%. Similarly, when tracking trends over time, what matters most is detecting significant changes, e.g., 30% to 60%, rather than pinpointing the exact value in any given week. The actions that result from prompt tracking, such as adjusting content or messaging, typically depend on coarse thresholds rather than precise numbers.
Even if a small sample is not precise enough for a specific need, the statistical tools we describe below allow us to quantify errors and determine how many responses are required.
Visibility Estimation Error
We conduct an experiment to measure the mean absolute error in visibility estimates as a function of the number of responses. For example, if the estimated visibility is 5% and the true visibility is 15%, the absolute error is 10%. The mean absolute error for a prompt is the average absolute error across all entities. We use this prompt-level metric because we are typically concerned with a brand's visibility relative to other competing entities. The MAE captures how well a sample of responses measures the visibility landscape for a prompt.
The dataset consists of 200 entity comparison question prompts from three sources: prompts tracked in Graphite’s prompt tracking tool, prompts generated from editorial search keywords, and manually written prompts on topics of general interest, like “What are the best science fiction books right now?” We obtain 400 responses for each prompt from the gpt-5.2-chat-latest model via the OpenAI API and extract entities that are answers to the question, as described later in the Entity Extraction section. (Note, we use the API for this experiment to get large numbers of responses, but see also the “API, Logged Out, and Logged In Responses” section.) We provide the full dataset of all responses and the entities.
We use 200 responses per prompt to estimate visibilities, and we treat these as ground truth values for our experiments, though of course they are also estimates. We subsample the remaining 200 responses 100 times, with different sample sizes, to simulate obtaining visibility metrics with fewer responses. This experiment illustrates the diminishing returns of generating additional responses.

In the figure above, we plot the mean absolute error (solid line) and one standard deviation above and below the mean (shaded area) to visualize the diminishing returns. The curve starts to flatten around 10 responses, at which point the mean absolute error is 5.6%, which is likely accurate enough for most use cases. To make sure the MAE is not overly biased by low-visibility entities, we also compute the MAE only considering entities with visibilities of at least 10%. The error is slightly higher in this setting, 9.1% mean absolute error, but the shape of the curve is exactly the same.
We also ran this evaluation on 50 prompts with OpenAI’s web search tool available. Web search was used 99.8% of the time. The curves are very similar.
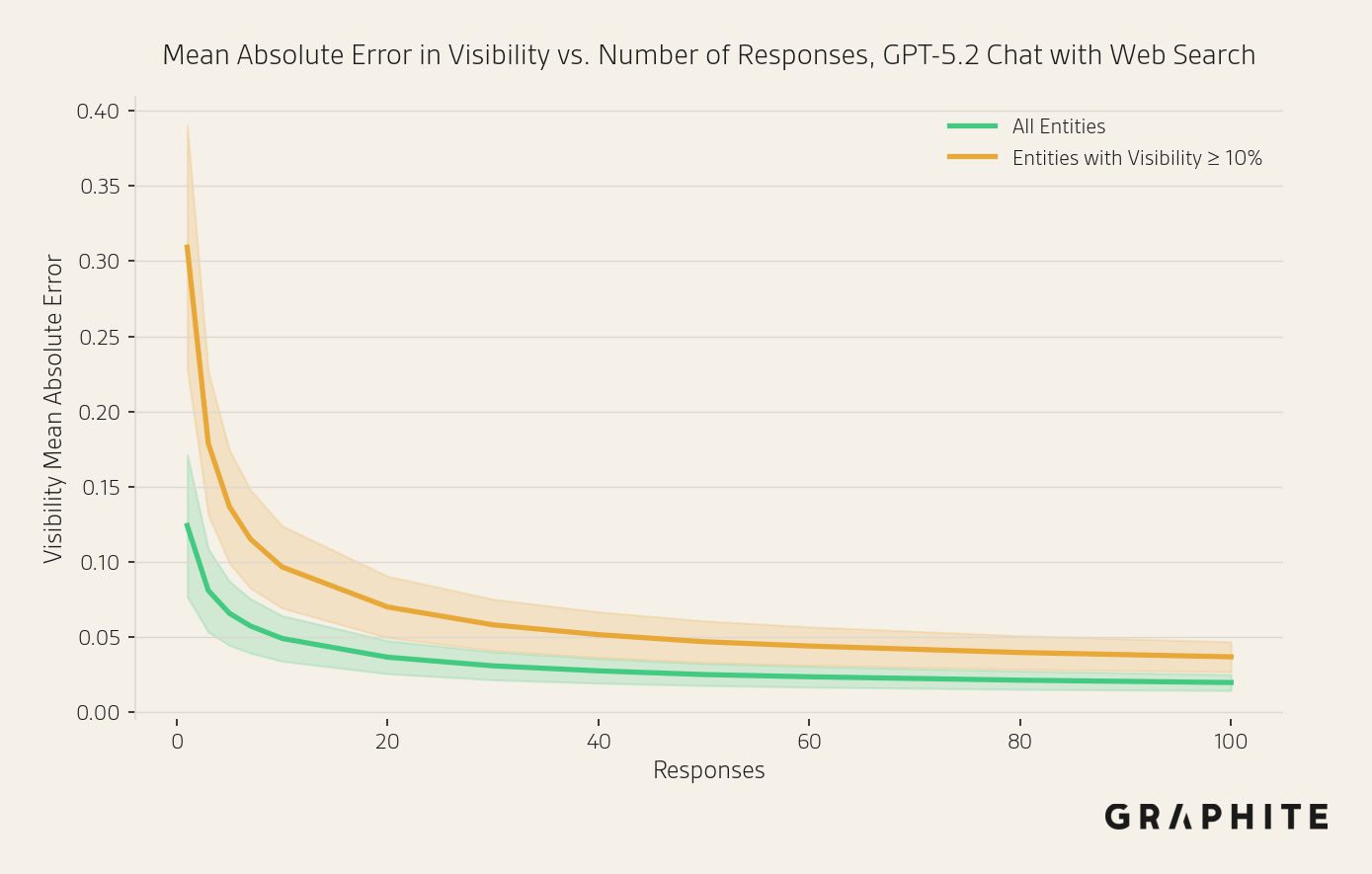
To verify this is not specific to OpenAI models, we also ran this evaluation using Gemini 3 Flash and again obtained similar results. With 10 responses, MAE is 5.5% with all entities, and 8.6% with entities with visibility >= 10%.

We can also look at what percentage of prompts have a mean absolute error of less than or equal to 10% and 5% with a given number of responses.
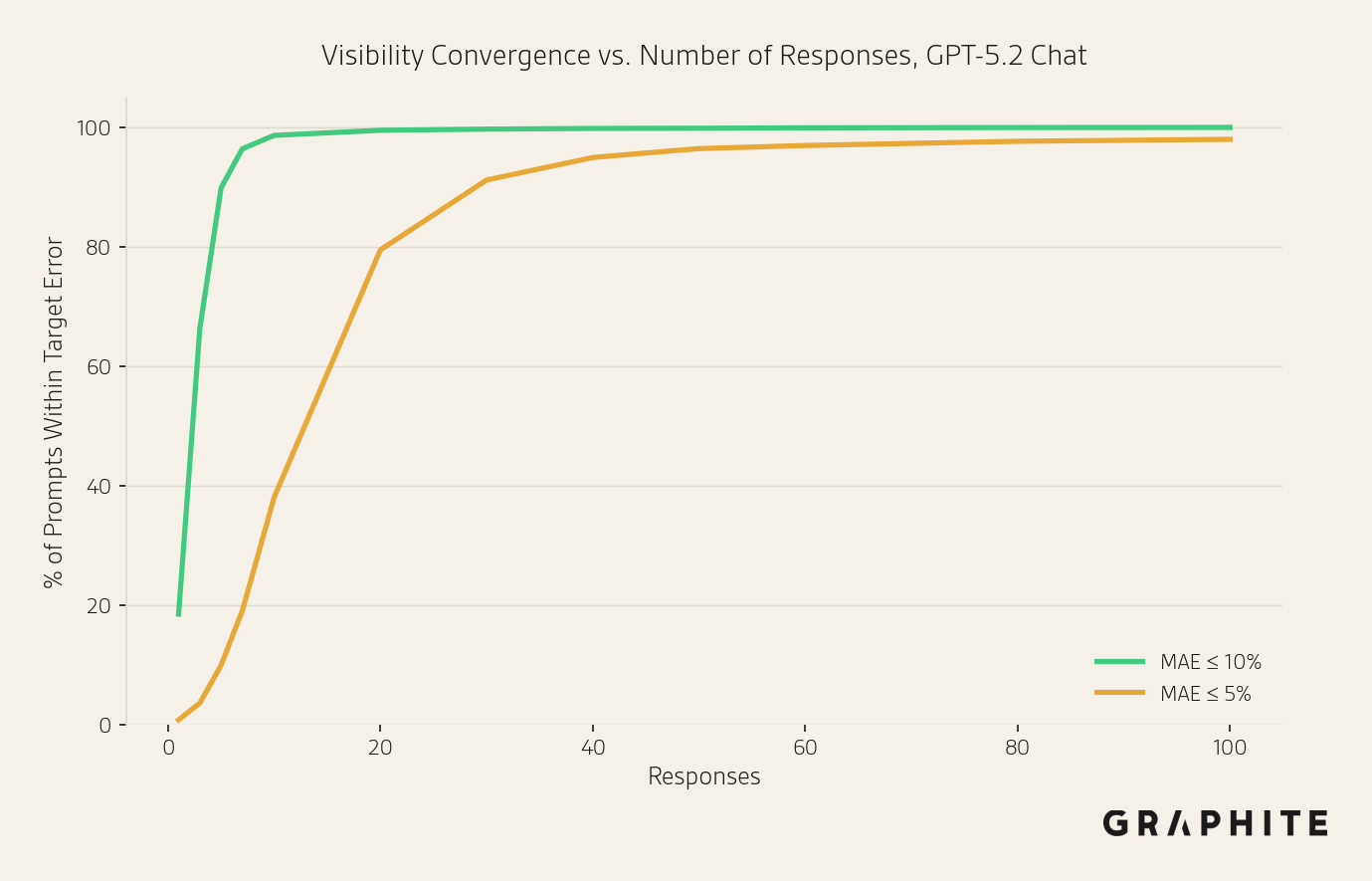
Here we see that 98.6% of prompts have a mean absolute error <= 10% after only 10 responses, and 94.9% of prompts get a mean absolute error <= 5% after 40 responses. The prompts that do not achieve MAE <= 5% at 100 responses tend to have many entities with visibilities close to 50%, such as “What are the best hotels in St. Barts?” and “Which wearables are the most accurate?” We discuss this more in “Do Some Prompts Need More Responses?”
This empirical evidence supports our recommendation of 10 responses as a starting point for most use cases when tracking entity comparison prompts. When greater precision is required, the following sections provide statistical tools to quantify the margin of error for any sample size and determine exactly how many responses are needed to achieve a target accuracy.
Visibility Confidence Intervals
Confidence intervals are statistical margins of error on estimates. To compute a confidence interval for an individual visibility value, note that the number of responses in a sample of size n that contain an entity can be modeled using a Binomial distribution, where p is the probability of the product appearing in an individual response.
For a technical audience: p is the marginal probability that an entity appears in a response at a particular time, assuming the distribution is stationary: the context is fixed and there are no changes to the model during that time. The Binomial model assumes responses are independent. We verified this by partitioning the 200 responses for each prompt into independent batches and comparing the observed variance of visibility estimates across batches to the expected Binomial variance. The median observed/expected variance ratio is 1.02, confirming that responses from independent API calls behave as independent draws.
We can compute a confidence interval for our estimate of p using the Wilson score interval (formula in the Appendix). For example, if 16 of 20 responses mention a product, the 95% confidence interval for the visibility is 58.40% to 91.93%. This means we are 95% confident that the true visibility value is in this range. However, a 95% confidence level may be unnecessary, depending on our risk tolerance. If we drop the confidence level to 80%, the confidence interval is tighter: 66.47% to 88.98%.
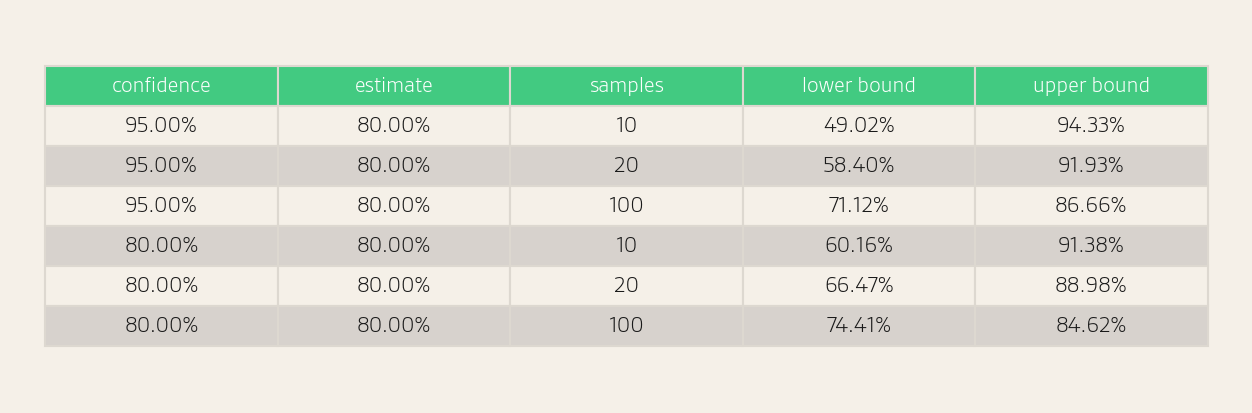
Note that while the MAE suggests a sample of 10 responses is sufficient on average, individual entities may have larger errors. Confidence intervals provide entity-level precision estimates.
Do Some Prompts Need More Responses?
The similarity of responses varies across prompts. One way to measure the similarity of responses for entity comparison question prompts is how similar the set of entities mentioned is across the responses. Here, we use the mean cosine similarity between binary entity vectors for pairs of responses. The higher the similarity, the more entities the responses have in common. The following figure shows that the prompts vary in how similar their responses are.
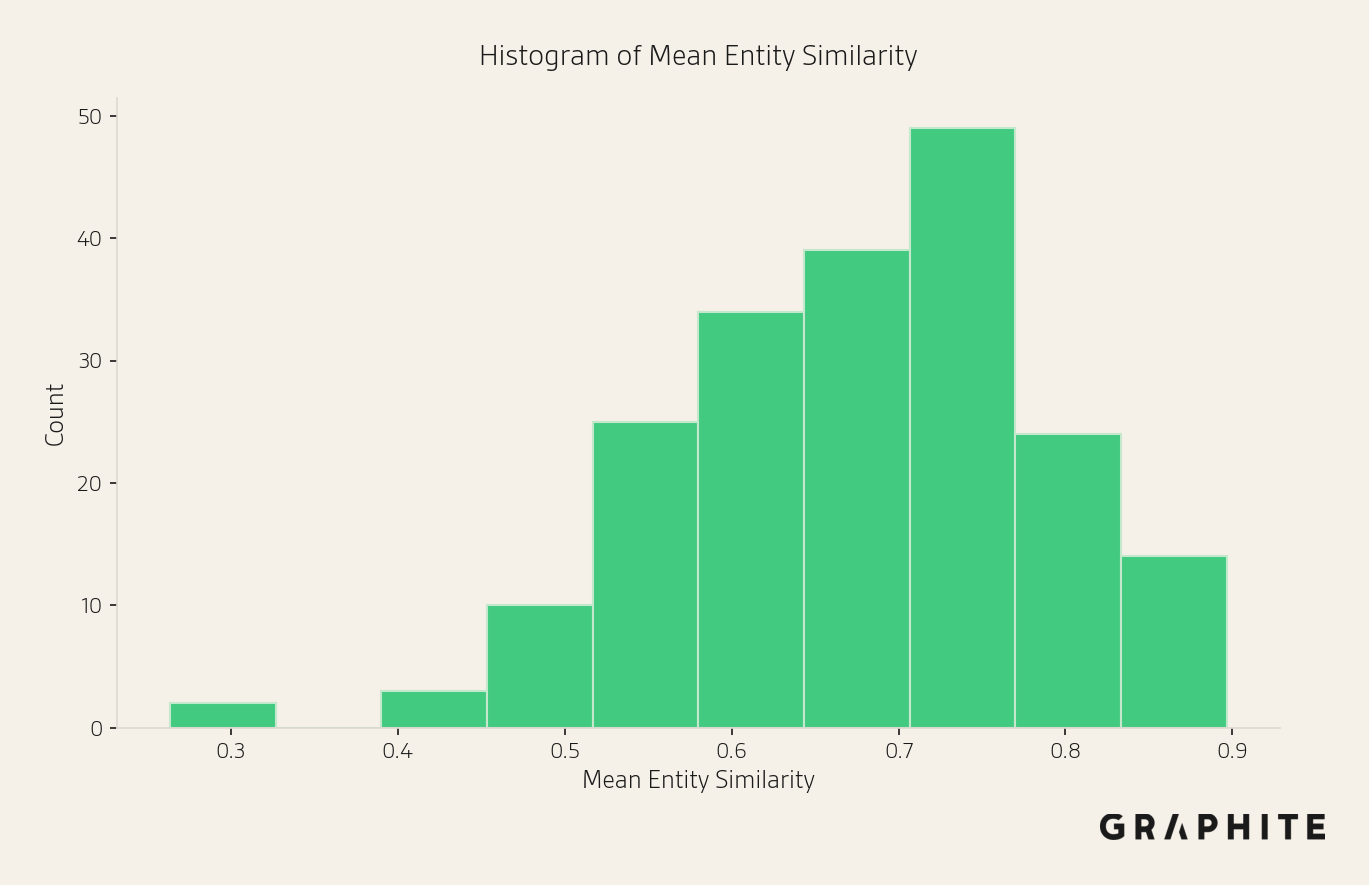
Here are examples of visibility charts for prompts with low, medium, and high entity similarity.
There are no entities that are always present in responses to “What are the best science fiction books right now?”, and there are many entities that have moderate visibility.
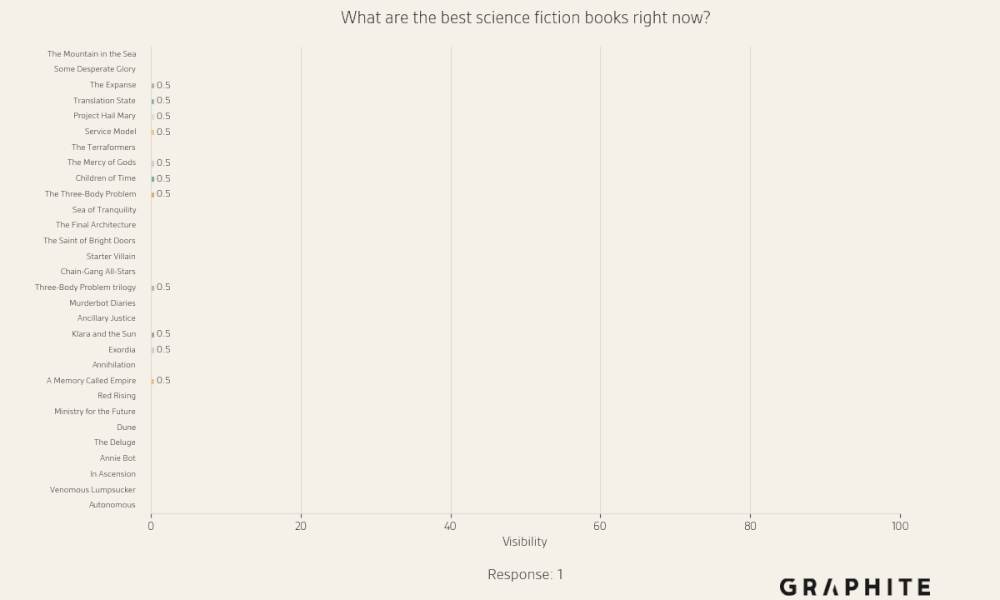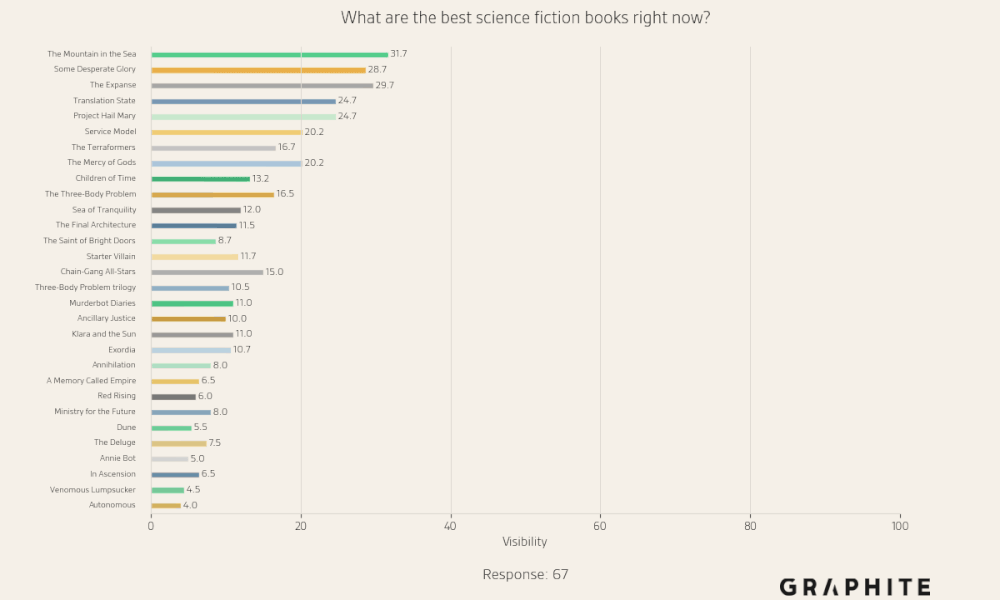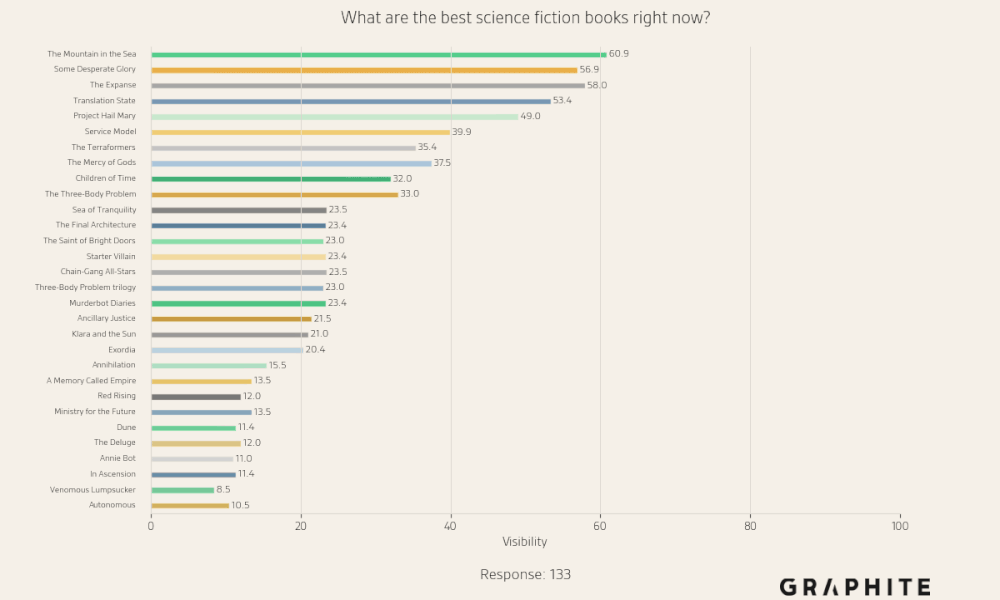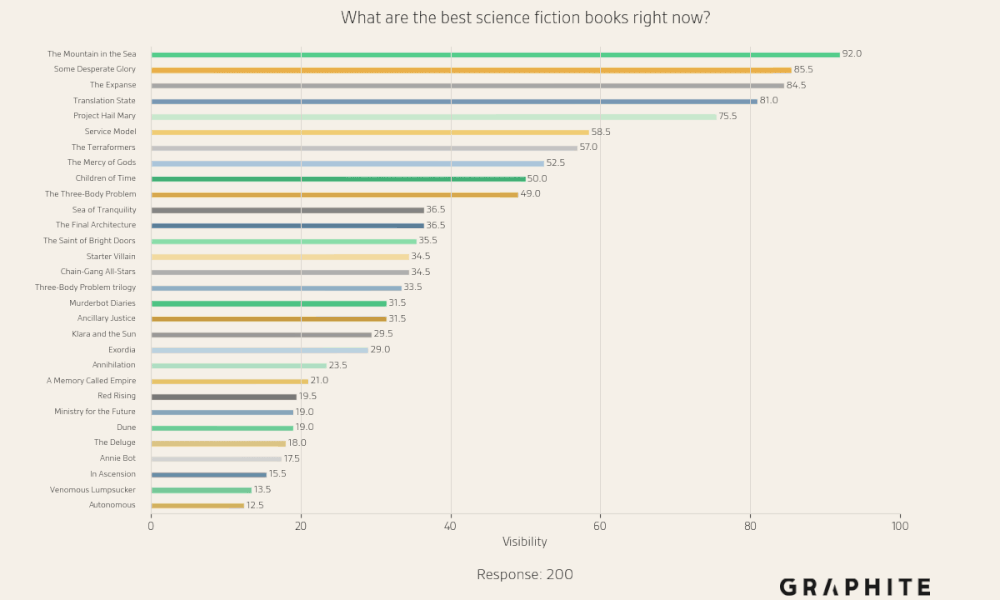
“What are the best hotels in Mexico City?” has more visibility concentrated in the top entities.

There is a small set of high-visibility entities for “What is the best board management platform for nonprofits, and how do their security and compliance features stack up?”
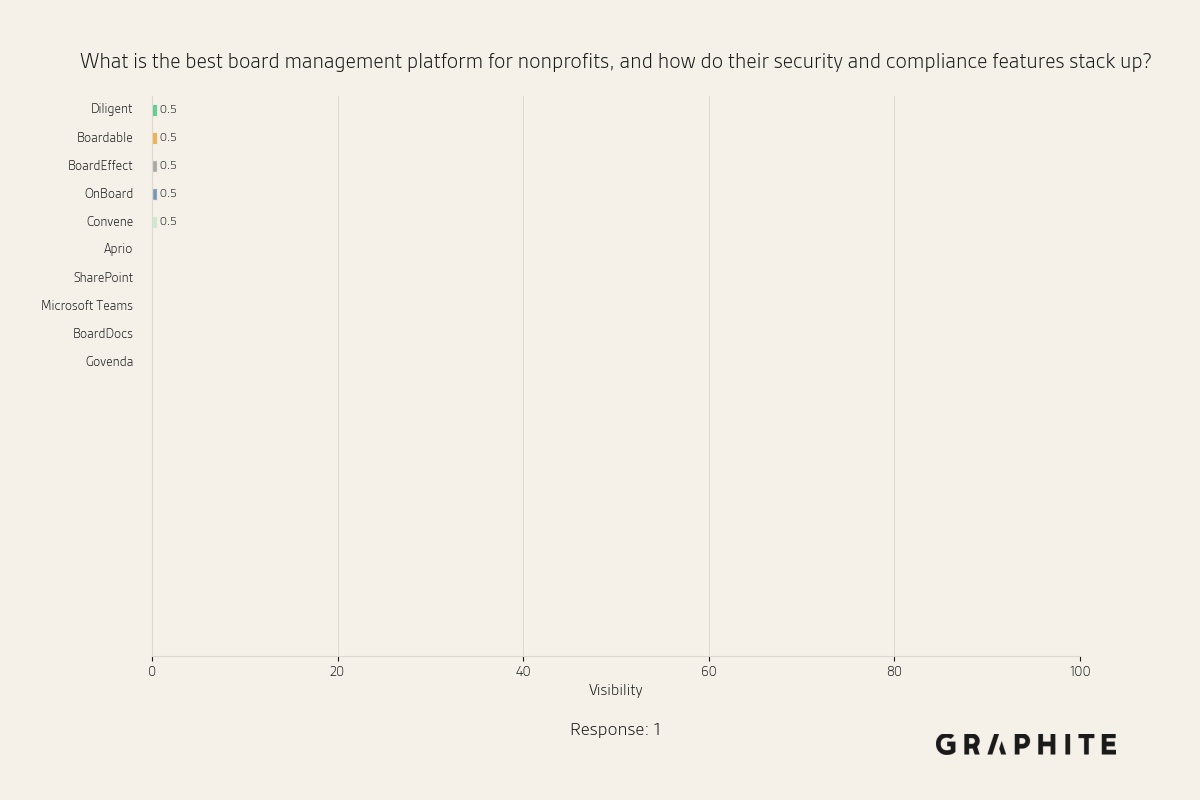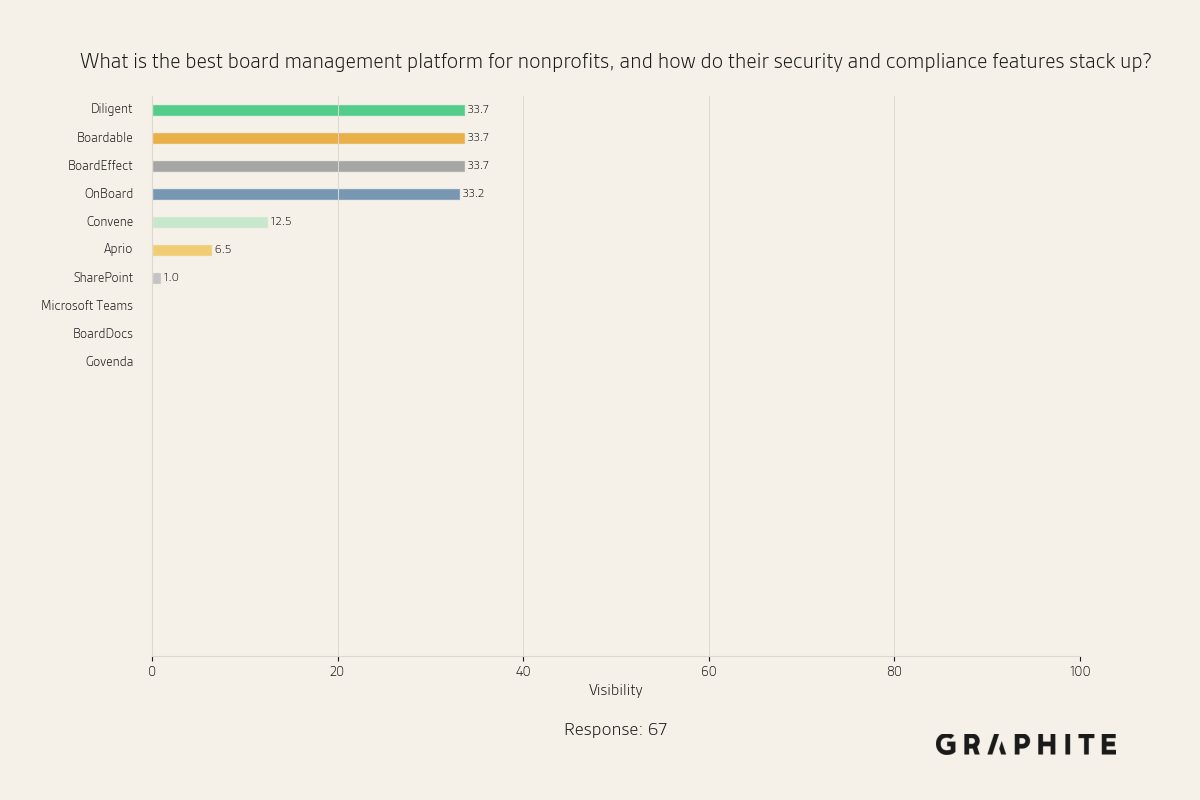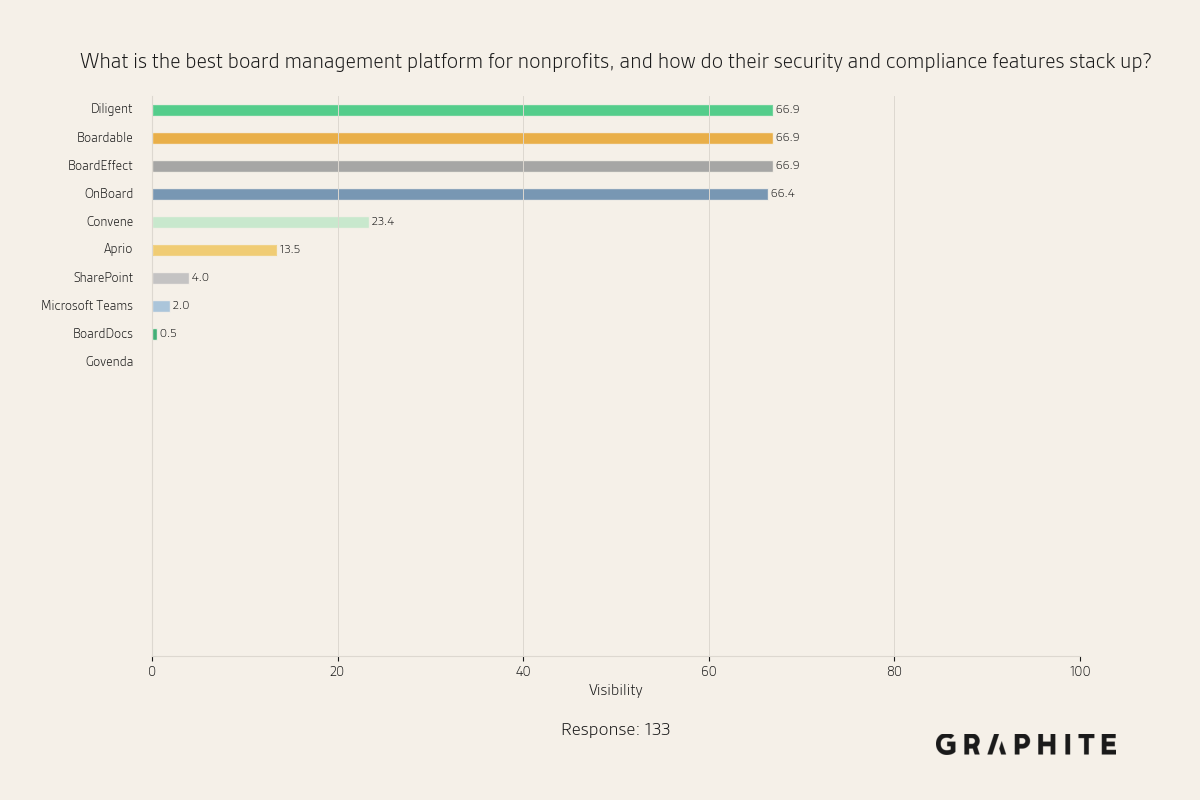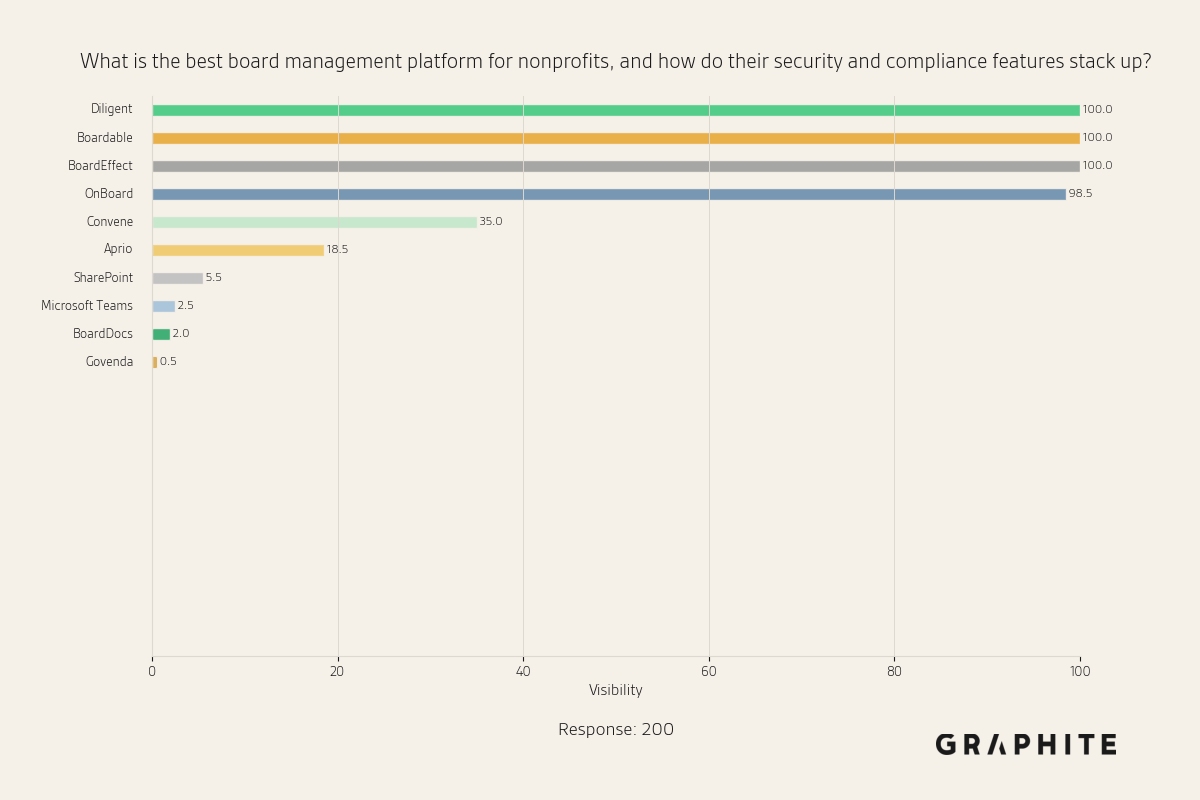
We can also visualize how these visibility values converge.


Should we handle prompts with more diverse responses differently?
Yes, but the distribution of visibility values is more important than the number of entities.
Number of Entities
With more long-tail answer options, we expect lower visibility values. The equations above are still correct, but the relative errors, the widths of the confidence intervals relative to the visibility values, may be large. However, whether a product appears 1% or 5% of the time may not be meaningful; the difference between 25% and 75% is meaningful.
Therefore, having more entities does not necessarily require larger sample sizes. The same sample size provides the same absolute precision; the high-visibility entities are estimated just as accurately as in responses with few entities.
Skew of Visibility Values
Visibility confidence intervals are wider when the visibility is close to 50%. The reason is that, statistically, visibility values near 50% require more responses to estimate, whereas values close to 0% or 100% are easier to estimate. In other words, visibility estimates for the entities that appear very frequently and very rarely converge faster.
Empirically, in our dataset, we find that more entities have visibility values closer to 0% or 100% than to 50%. Therefore, a small number of responses, such as 10, is often sufficient because the worst-case for the Binomial distribution (visibility near 50%) is more infrequent in practice. This explains why we can often achieve a low mean absolute error with fewer responses than expected.

We next plot the number of responses required to achieve MAE <= 10% vs. the mean entropy of the Bernoulli distribution (single coin flip) across all entities for each prompt. A higher value means the visibility values are, on average, closer to 50%. We find that, indeed, prompts with higher average entropy require more responses to obtain a low mean absolute error.

Prompts from our internal prompt tracking tool, which are focused on brands, typically have lower average entropy than other prompts in our dataset (0.586 vs. 0.632, out of a maximum of 1.0), indicating they are easier to estimate. Highly subjective questions on general interest topics, like “What are the best restaurants in Oakland right now?”, are harder to estimate.
For these higher-entropy prompts that require more responses, we can use sequential sampling, described next, to efficiently determine the appropriate number of responses.
Prompt-Specific Sample Sizes with Sequential Sampling
We can use sequential sampling to decide when an estimate is “good enough”, so that different prompts get different numbers of responses, rather than the common strategy of using a fixed number of responses per prompt, such as 100.
If we care about a specific entity getting a confidence interval of width E, we can start with a few responses and iteratively add more until the width of the confidence interval falls below E. For example, if the 95% confidence interval of 58.40% to 91.93% for visibility 80% with 20 responses is too wide, and we want a width less than 25%, we can try iteratively adding 10 responses:
- 16/20 => width: 33.54%
- 23/30 => width: 29.14%
- 33/40 => width: 23.20% STOP
The savings provided by stopping early depend on the true visibility. Visibilities close to 50% take the longest to converge, but visibilities close to 100% converge much faster. For example, to get a 95% confidence interval of width 15% with a true visibility value of 50%, 167 responses are required, whereas for visibility 100% the number of samples is only 22, an 87% reduction.
In our data set, visibility values are skewed away from 50%. Among entities with visibility ≥ 10%, 51% have visibility below 20% or above 80%, and only 13% are between 40 and 60%. On average, achieving a 95% confidence interval of width 15% would take 101 responses, a reduction of 40% relative to the worst-case 167. For a confidence interval of width 30%, the reduction is 36%: 39 samples to 25.
We could also stop when the average or max width of the confidence interval across all entities reaches a target error width.
For example, considering entities with visibility ≥ 10%, suppose we want the average 95% confidence interval width on each prompt to be less than 15%. Under worst-case sampling, the smallest fixed budget that guarantees this on every prompt is 135 responses per prompt. Sequential sampling achieves the same guarantee with an average of 89.3 responses per prompt, a 34% reduction.
Tracking Position
The position of an entity in a response is its order relative to other entities, based on its first appearance in the response. For example, in the ice cream example, if the first three entities were “vanilla”, “chocolate”, and “strawberry”, the position of “strawberry” would be three. One subtlety with position is what to do when an entity does not appear in a response. The clearest approach is to define position only when an entity appears.
Therefore, visibility measures how often an entity appears, and position measures how prominently it appears when present. Track visibility when an entity doesn’t appear often, but if it appears very frequently, focus on position.
We can apply the same methodology we applied to visibility to position. We should not infer anything from individual responses, but with a sample of responses, we can estimate the position distribution and measure the average position over all responses. (Even in traditional search, position changes frequently, which is why GSC displays the average position.)
One thing to note, however, is that because position is defined only when an entity occurs, the effective sample size for measuring the average position depends on the entity's visibility. Tracking the position of low-visibility entities yields a low effective sample size and unstable estimates, which is another reason to avoid position until visibility is high.
Position histograms are a good way to visualize position variance.
Position Estimation Error
As we did with visibility, we compute the mean absolute error of position estimates as a function of the number of responses. We measure error for entities with visibility of at least 10% in the full set of responses, and we discard entities that do not appear in the sub-sample. Note that when estimating position from k responses, the effective sample is <k unless the true visibility of the entity is 100%, since position only considers responses where the entity is present. The error decreases more slowly, but by 10 responses, it is just above one position, at 1.06 (out of 23.4 entities on average that appear in a sample of 10 and have ground-truth visibility of at least 10%), despite the smaller effective sample size. We find that this surprisingly small error is achievable because the entities at the top of the list tend to be very stable: high-visibility (more samples) and consistent position, leading to low error. Entities near the bottom vary more and contribute most of the error, but also tend to be low-visibility.
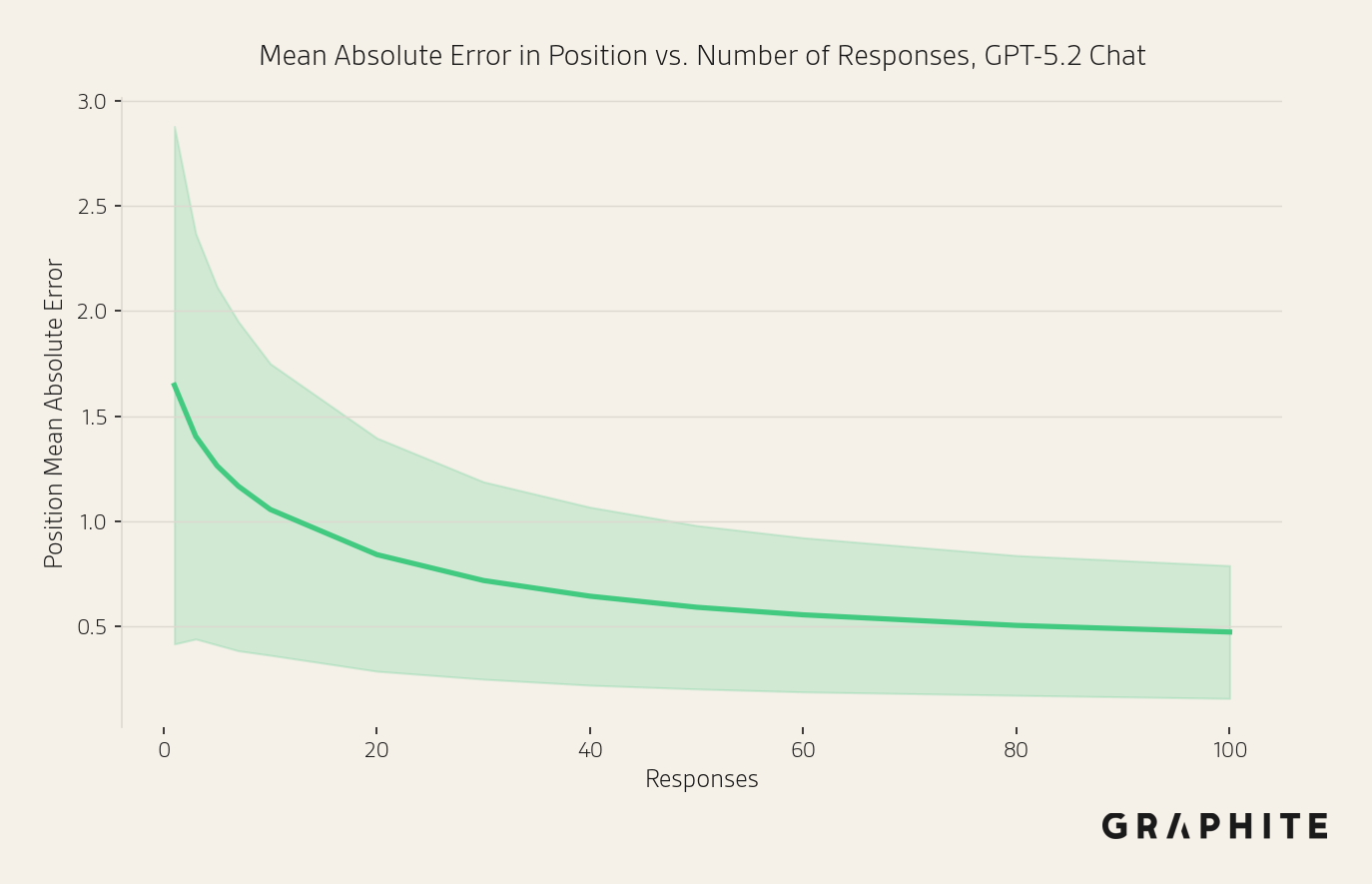
We also ran this evaluation on 50 prompts with OpenAI’s web search tool available to the model. Web search was used 99.8% of the time. The curves are very similar.

We also repeated this experiment using Gemini 3 Flash and found similar results. With 10 responses, MAE is 0.95 positions, and the shapes of the curves are also very similar.

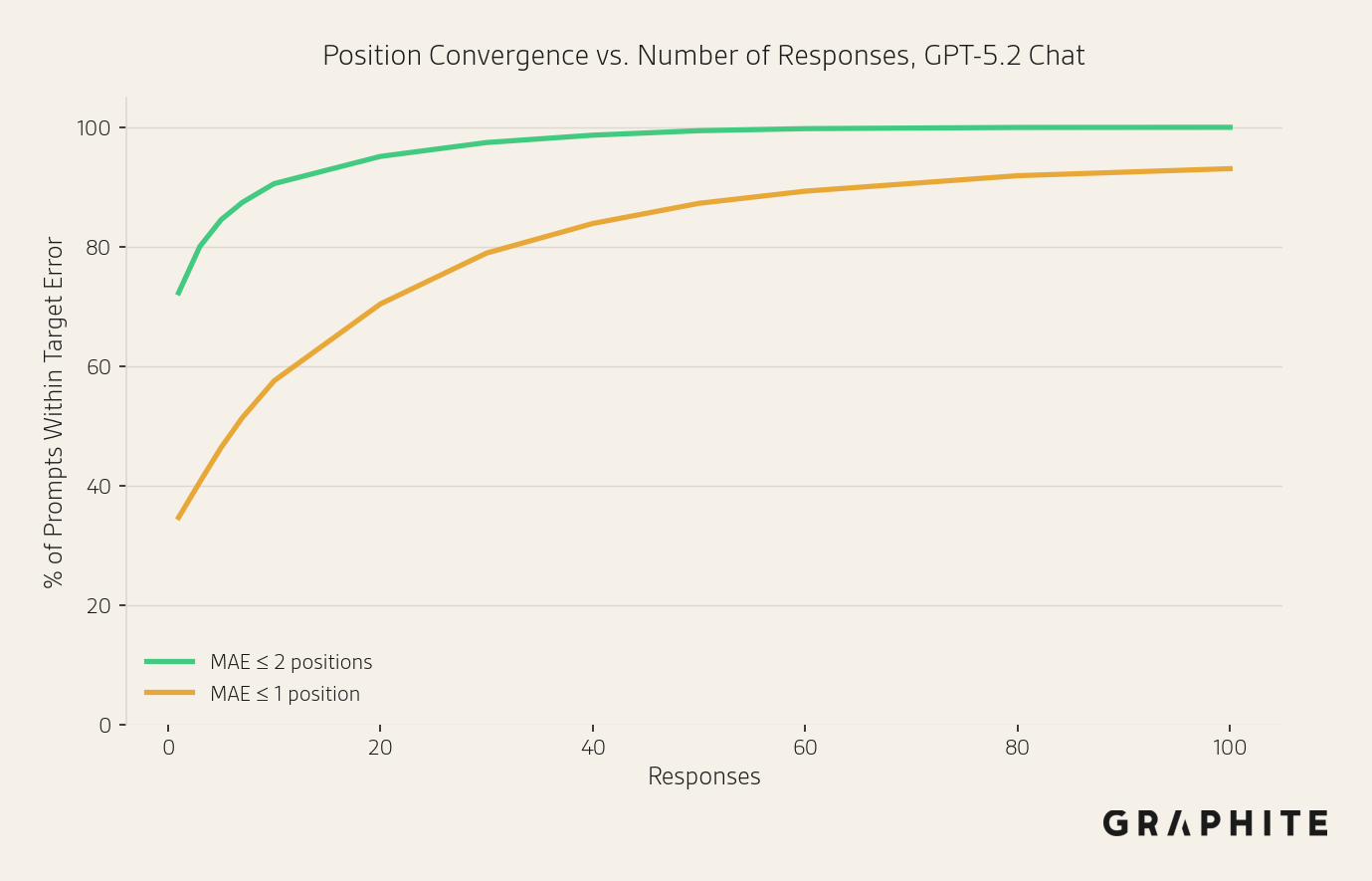
Below, we show the percentage of prompts that have a mean absolute error <= 2 or 1 position after different numbers of responses. With 10 responses, 90.6% of prompts have a mean absolute error <= 2 positions. Many of the prompts that do not achieve MAE <= 1 position after 100 samples are “What are the best things to do in CITY?” questions, that have less stable orderings.
Position Confidence Intervals
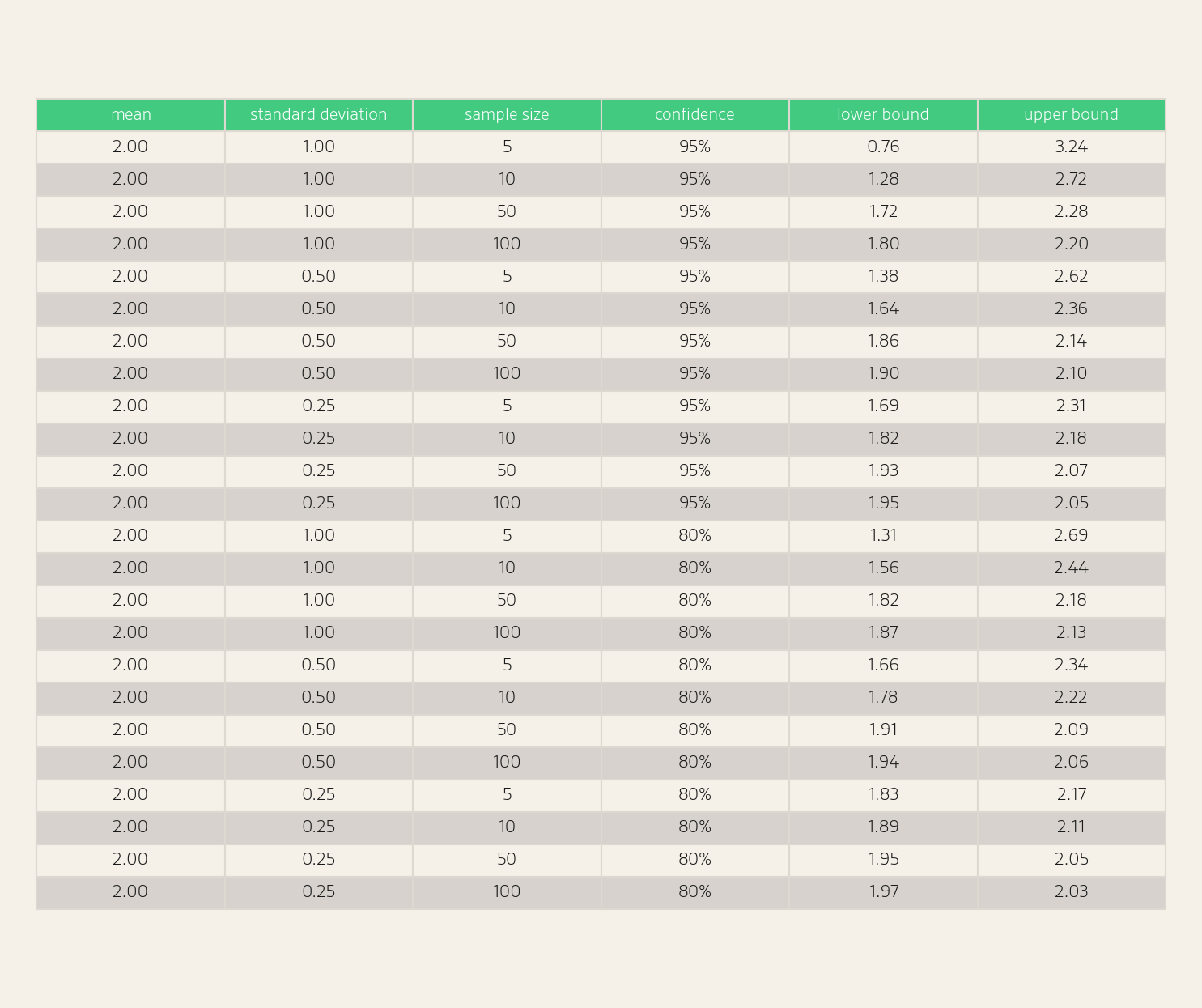
We can compute a confidence interval for the average position (formula in the Appendix). For this calculation, we need to compute the standard deviation of observed positions. We can see some example confidence intervals in the table below.
As with visibility, sequential sampling can be used to efficiently collect additional responses for position estimates that are not precise enough.
Tracking Over Time
We should track responses over time. However, daily tracking may be excessive for many use cases. We hypothesize that meaningful day-to-day changes will be rare, though we leave the evaluation of this to future work. Regardless of cadence, we take care not to interpret fluctuations in the metrics due to randomness as meaningful changes. A simple method is to compute confidence intervals for each time interval, as described in the Tracking Visibility and Tracking Position sections above. If the confidence intervals do not overlap, the difference is statistically significant. If they do overlap, the difference may be due to noise rather than a significant change, and we can run a statistical significance test to check whether the difference is real (see the Appendix for details).
Below are some example test results:
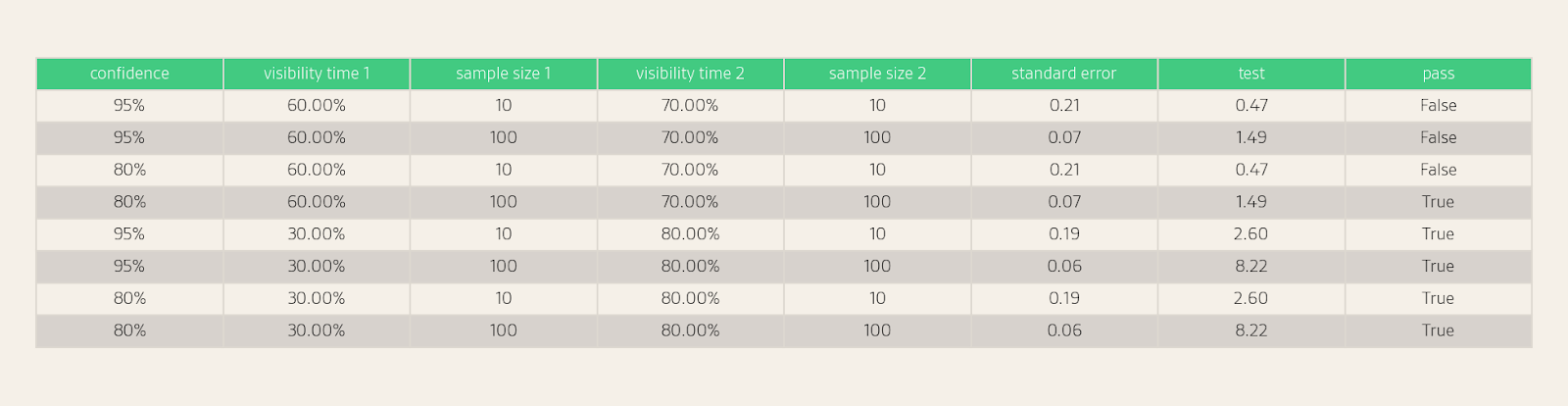
In the following figure, we show whether two visibility estimates can be distinguished based on a particular sample size and confidence level.
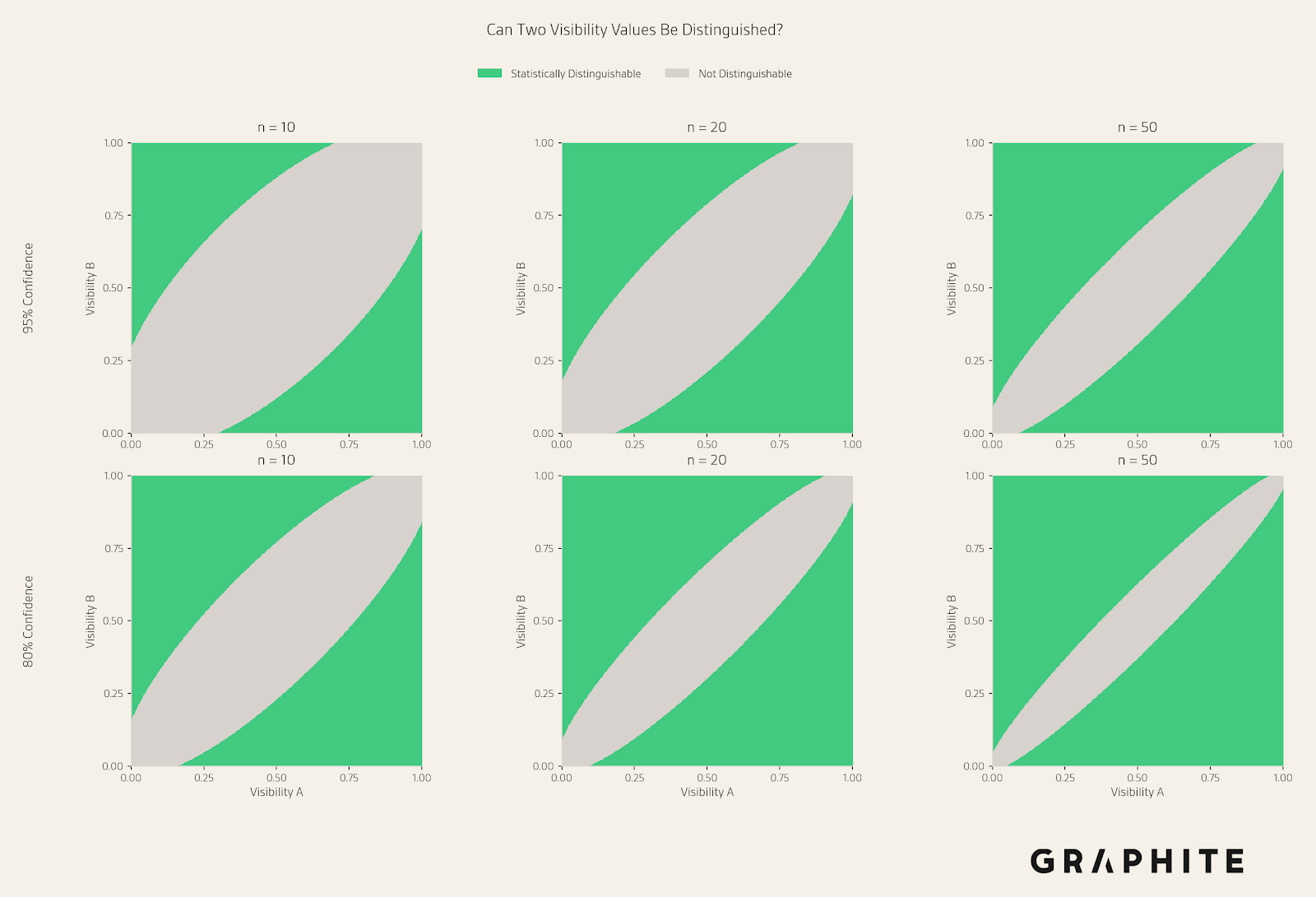
For example, with 10 responses, we can statistically distinguish between 75% and 25%, but not 75% and 50%. With 50 responses, we can statistically distinguish between 50% and 30%, but not 50% and 40%.
We can also run statistical significance tests for position.
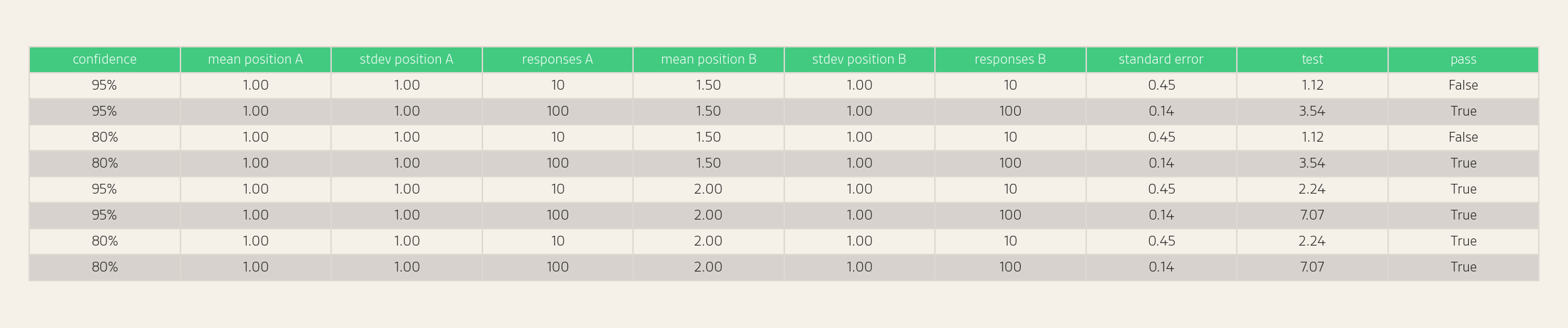
Note that this test assumes independent samples (see also the note for a technical audience in Visibility Confidence Intervals), so it applies to comparing the same entity across time periods, but not to comparing two different entities from the same set of responses. When comparing visibilities from the same set of responses, we can use McNemar's test, which accounts for the paired structure of the data. Alternatively, we can simply compare the entities' individual confidence intervals. Each interval is valid on its own, regardless of correlation, so non-overlapping intervals still imply a significant difference.
Sequential sampling can also be applied within each time period to ensure estimates are precise enough to make meaningful comparisons.
If tracking daily with a single response, using a moving average is essential, but be aware that this approach may make it more difficult to identify real changes.
A/B Testing
The above statistical test can also be used to measure the difference between the visibility of a brand among control and treatment groups of prompts in an A/B test, assuming the prompts are randomly assigned to the groups. We will discuss experimental design for prompt tracking in a future article.
Search
Note that if the response does not include citations, the AI assistant is not using a search tool, thereby eliminating one frequent source of variation. Therefore, the response distribution has fewer reasons to change over time, and observed differences between time periods are more likely to be due to sampling noise.
When responses include citations, we can also measure citation visibility, the percentage of responses that cite a particular source, using the exact same methodology as entity visibility.
Personalization
To account for personalization, we need access to responses to the same prompt from many different user accounts. That is, we need panel data (responses from a representative sample of real user accounts). For prompt tracking without panel data, we recommend using new chats without conversation history and disabling memory to ensure responses reflect the underlying probability distribution.
What Prompts Should We Track?
We focus on measuring visibility and position for a particular prompt. In practice, users may express the same intent using many different phrasings, so selecting which prompts to track is an important consideration. We plan to formally quantify the sensitivity of visibility and position to prompt variation and provide recommendations for selecting and grouping prompts and for allocating samples among them in future work.
API, Logged Out, and Logged In Responses
Prior work showed that there can be significant differences between the responses and citations output by LLM APIs and those that users see in consumer-facing applications. Should we track non-API responses differently?
For these experiments, we use data provided by Gauge, a software platform that helps brands show up in more AI answers (Answer Engine Optimization/AEO). Gauge scrapes answers from the websites of the model providers themselves, as opposed to the APIs, in order to get as close as possible to replicating real user behavior.
We conduct experiments with 400 scraped, logged-out responses from ChatGPT and Gemini for each of the 200 prompts used for our API experiments. We provide the full dataset of all responses and the entities.
Are the responses users see different?
To quantify the entity-level agreement between logged-out and API responses, we merged the entity maps across both datasets and computed pairwise cosine similarity. Focusing on entities with at least 20% visibility, the mean within-dataset similarity is 0.70 for logged-out responses and 0.76 for API responses, while the cross-dataset similarity is 0.48. This validates that API responses and the responses users see are different. The logged-out responses are also slightly more variable.
Are the responses users see harder to measure?
In the figure below, we see that although the answers differ, the variability does not make visibility measurement more difficult.
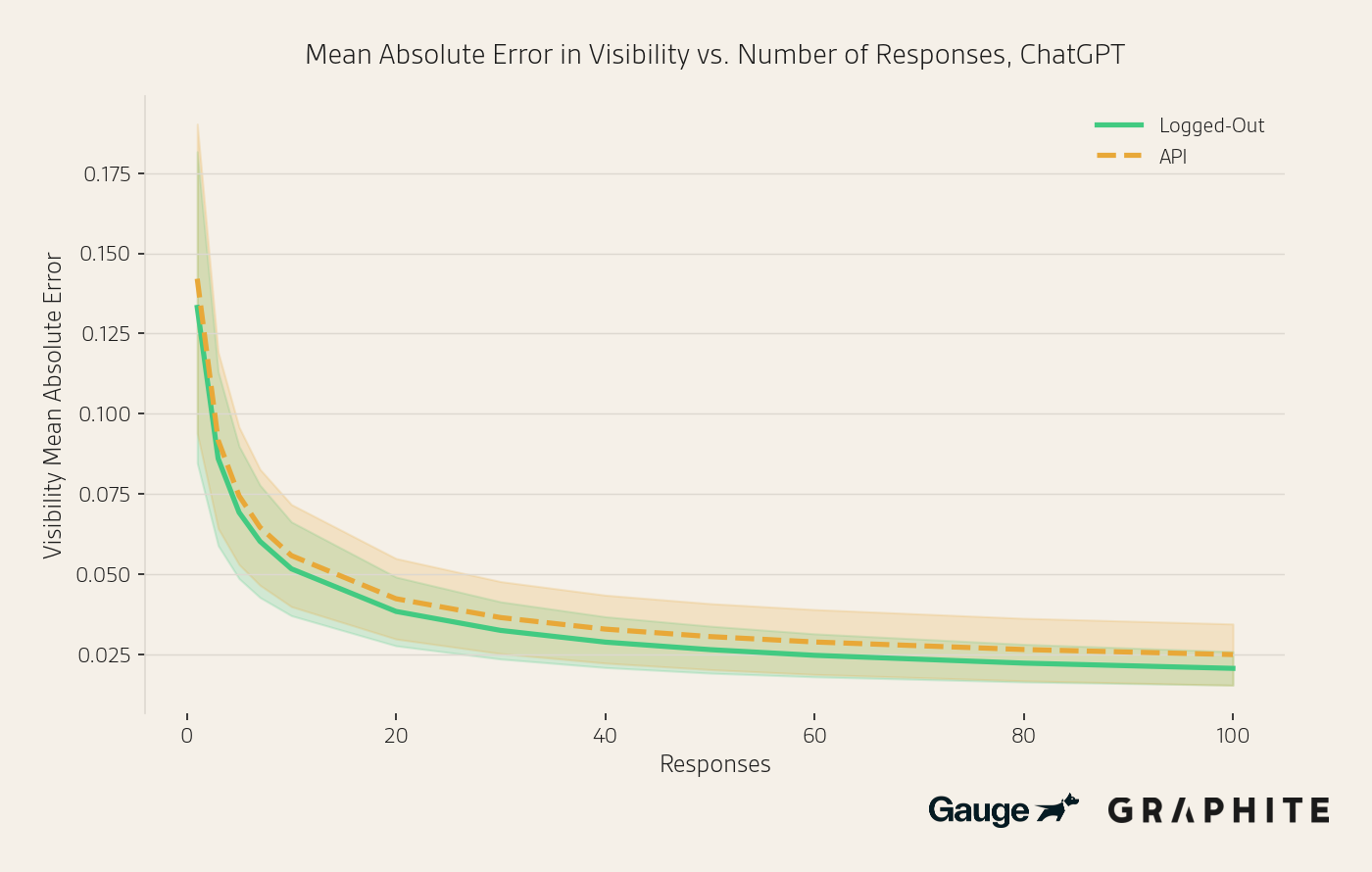
When measuring position, we see a slightly larger error for logged-out responses compared to API with the same number of responses. This is primarily because logged-out responses have 81 unique entities mentioned per-prompt, on average, vs. 71 for the API, which means a larger range of positions and, hence, a higher potential for error. Note that the absolute errors are still quite small, averaging about 1.11 positions (out of 24.1 qualifying entities, on average) at 10 responses.

We see similar results for Gemini, with a slightly larger gap for position (1.22 vs. 0.95 positions at 10 responses). Logged-out Gemini responses have 78 unique entities per prompt vs. 69 for the API.


We also tested independence here and found median observed/expected variance ratios of 1.02 and 1.02 for ChatGPT and Gemini (batch size 10), confirming that responses from independent scrapes behave as independent draws.
We are actively working on collecting logged-in responses for our prompt data set, and will post new experimental results soon. Early results suggest a similar pattern: while the responses and entities vary quite a bit with logged-in user responses, the error is not substantially larger, and the same recommendations apply.
Note that scraping and having users run prompts are challenging to scale, so gathering large numbers of responses is likely only feasible at scale with APIs. Using sequential sampling is very impactful here.
Entity Extraction
Extracting product names from a response may seem straightforward, but there are subtleties to consider. First, entities are often referred to by different names, so we need to group them. Second, responses often mention entities that are not a part of the answer. For example, responses to the prompt “What are the best restaurants in California?” will include entities like “San Francisco” and “Dominique Crenn”, but the actual entities we care about, the “answers”, are the names of restaurants.
One solution is to define the set of entities to track for each prompt. For this article, we use the following algorithm:
- Use a GPT-5.2 to extract main entities from each response in each round.
- Use a GPT-5.2 to cluster unique entity mentions into groups of mentions that refer to the same canonical entity.
Note that it is challenging to do entity extraction and canonicalization perfectly, and entity extraction errors will inevitably propagate into visibility and position estimates.
We provide the prompts in the Appendix.
Conclusion and Summary of Recommendations
There is randomness in how LLMs respond, but this does not make responses unmeasurable. The statistical tools described in this paper allow practitioners to quantify precision, determine appropriate sample sizes, and make confident comparisons. These tools work for any data collection method. Our recommendations:
1. Do not rely on a single response. Instead, run each prompt at least 10 times for a quick estimate.
2. For more precise estimates, rather than gathering large numbers of responses by default, use sequential sampling: add responses iteratively until the confidence interval is sufficiently tight.
3. Use confidence intervals or statistical tests to decide if changes are real (make a copy of the provided sheet). Generally, be skeptical of small differences in visibility and position, especially for responses that do not use web search.
4. Track weekly or biweekly. If tracking daily, take care not to interpret noise as signal.
5. Use a new chat for each prompt and disable memory.
6. Focus on the right metric for your situation:
- Visibility (how often a brand appears) is the best initial metric, especially if your brand is not yet consistently mentioned.
- Position (how prominently a brand appears when it does appear) matters more when a brand already appears frequently, and the focus is on its placement relative to competitors.
7. Supplement prompt tracking tools by also manually gathering responses from AI with a logged-in account.
Future Work
There are many additional questions about prompt tracking to answer. In future studies, we plan to investigate and evaluate how to select prompts to track, how to think about related prompts, and how to group prompts into topics.
Disclosures
The authors are the Chief AI Officer and CEO at Graphite, a research-powered AEO and SEO consulting agency. All data and calculations referenced in this paper are publicly available.
Appendix
Statistics
Wilson score binomial confidence interval for visibility
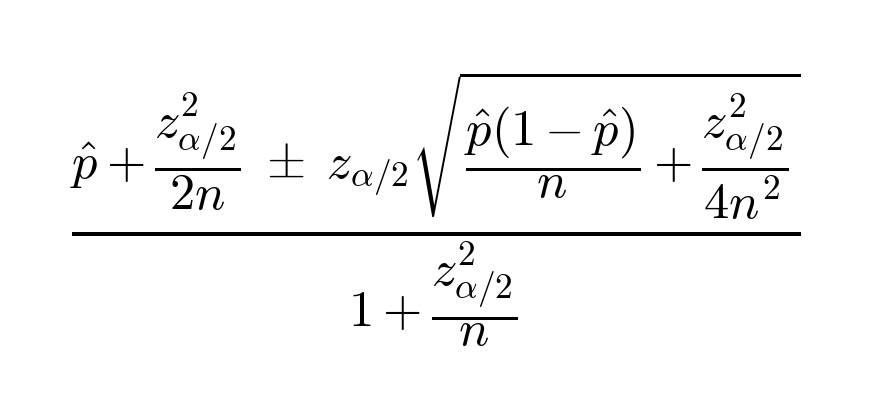
Statistical significance test for visibility
We can compute the standard error of the difference as follows:

Then, the visibility difference is statistically significant if

Confidence interval for position
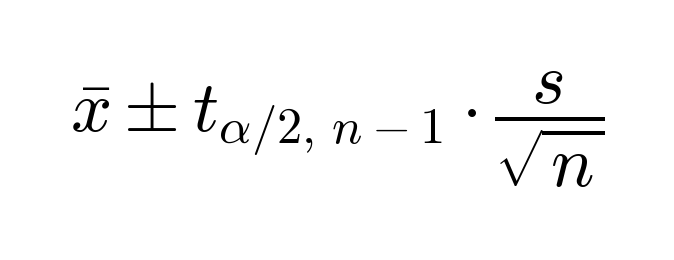
where x is the mean position, and s is the sample standard deviation.
Statistical significance test for position
We can compute the standard error as follows:
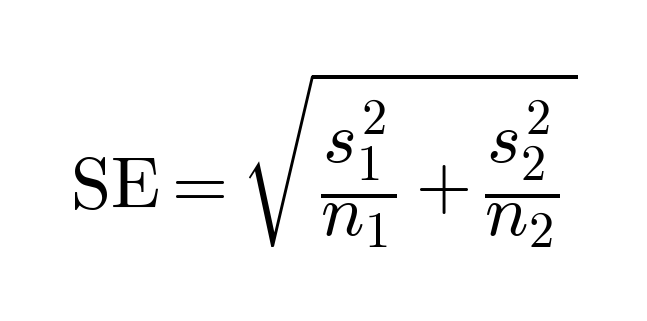
Then, the position difference is statistically significant if

With degrees of freedom df given by

Entity Extraction Prompts
Both prompts use structured outputs.
Tagging
You will receive a text that compares several named entities.
Provide a list of the main named entities that are compared.
Canonicalization
You will receive a list of named entity strings extracted from responses to a question.
Group named entity strings that refer to the same canonical named entity.
Make sure that each input named entity is included in the output.

